AWS Database Blog
Gracefully handle failed AWS Lambda events from Amazon DynamoDB Streams
Modern applications often use event-driven architectures to achieve scalability, responsiveness, and resilience. Amazon DynamoDB streams and AWS Lambda are a popular combination for building these systems, making it possible to respond in near real time to changes in your data. However, production systems must account for failure scenarios, especially when events are not processed successfully.
In this post, we show how to capture and retain failed stream events for later analysis or replay using Amazon Simple Storage Service (Amazon S3) as a durable destination. We compare this approach with the traditional Amazon Simple Queue Service (Amazon SQS) dead-letter queue (DLQ) pattern, and explain when and why Amazon S3 is a preferred option.
Understanding failure handling with DynamoDB streams and Lambda
When Lambda functions process DynamoDB streams events, the default behavior is to retry the batch if the function returns an error. Lambda continues retrying failed batches until the function succeeds or the stream record expires (after 24 hours).
By default, this retry policy is unbounded (maximumRetryAttempts = -1). Although this provides durability, it can also lead to a permanently failing event blocking the entire shard for up to 24 hours, delaying processing of all subsequent records on that shard. For this reason, it’s important to configure a bounded retry policy using the maximumRetryAttempts parameter and define an onFailure destination. If all retry attempts are exhausted, Lambda will send a record describing the failed invocation to the configured destination.
Traditional DLQ destinations like Amazon SQS and Amazon Simple Notification Service (Amazon SNS) only include metadata about the failed invocation, not the original event payload (Record) that triggered the failure. For stream-based workloads, this limits your ability to debug, replay, or audit failed events, especially if the original record expires from the stream before retrieval.
Keep in mind the following:
- Only metadata about the Lambda invocation is sent, not the full event that caused the failure
- If a full record is needed, it must be retrieved from the original stream within the 24-hour retention window
Support for Amazon S3 as a failure destination
As of November 2024, Lambda now supports Amazon S3 as an on-failure destination for event source mappings from DynamoDB streams, Amazon Kinesis, and Amazon Managed Streaming for Apache Kafka (Amazon MSK). This allows failed event payloads to be delivered directly to Amazon S3 as JSON files, enabling long-term storage, replayability, and observability.
Compared to Amazon SQS or Amazon SNS, Amazon S3 provides several advantages:
- Stores the complete payload that caused the failure, including stream metadata and invocation context
- Allows for flexible retention policies using Amazon S3 lifecycle rules
- Integrates with Amazon S3 Event Notifications to trigger automated recovery or alerting workflows
This pattern helps teams avoid data loss while simplifying diagnostics and operational response to failure events.
Solution overview
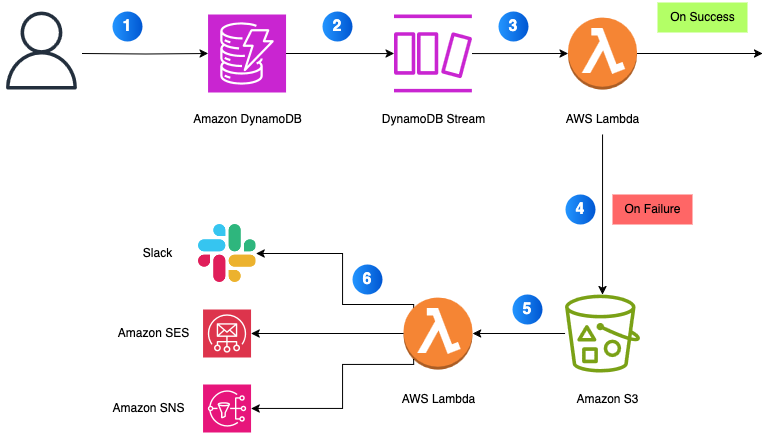
The following architecture illustrates how to implement failure handling using Amazon S3:
- A user makes a request to DynamoDB.
- A change event is emitted to a DynamoDB stream.
- A Lambda function consumes the stream using an event source mapping.
- If the function fails after all retry attempts, the failed event is written to an S3 bucket.
- A second Lambda function listens to new S3 object creation events.
- The Lambda performs one or more of the following actions:
- Send an alert downstream to services such as Amazon SNS, Amazon SES or Amazon EventBridge.
- Archives the payload to a central data lake.
- Replays the event into the original or fallback processing pipeline.
This approach decouples the real-time processing pipeline from failure remediation, maintaining continued stream processing while retaining the failed data for further inspection or replay.
The following diagram illustrates the solution workflow.
Event source mapping configurations
To provide reliable stream processing, it’s critical to tune your event source mapping configuration. Parameters such as maximumRetryAttempts and bisectBatchOnFunctionError play a key role in controlling retry behavior and isolating failures. By default, Lambda retries a full batch of records if an item in the batch fails, which can block progress on a shard and delay downstream processing. Enabling bisectBatchOnFunctionError instructs Lambda to split failed batches into smaller units, eventually isolating the failing record for retry or failure capture. Combined with a bounded retry policy, this makes sure your system continues processing healthy records while directing only unrecoverable failures to your configured destination, such as Amazon S3. This approach improves resilience, minimizes processing delays, and gives you fine-grained control over failure handling in stream-based architectures.
AWS CDK code example
The following AWS Cloud Development Kit (AWS CDK) code creates a DynamoDB table, S3 bucket, and Lambda function that uses Amazon S3 as a failure destination:
Sample failure payload format in Amazon S3
When Lambda writes a failed event to Amazon S3, the object is structured as follows:
The payload field is a stringified JSON containing the original Records array passed to your Lambda. You can parse it and replay the entire batch.
Operational considerations
The following are some best practices when configuring Amazon S3 as a failure destination for DynamoDB stream consumers:
- Make sure the Lambda execution role includes
s3:PutObjectpermissions for the destination bucket. - Be aware that Lambda uses a structured naming convention for S3 object keys when storing failed asynchronous events. The object key format is as follows, which you can use to organize and automate processing of failed events, and it supports chronological exploration in Amazon S3:
aws/lambda/async/<function-name>/YYYY/MM/DD/YYYY-MM-DDTHH.MM.SS-<UUID>.json
- Enable server-side encryption using AWS Key Management Service (AWS KMS) for compliance-sensitive workloads.
- Use S3 Event Notifications to trigger a downstream Lambda function that handles alerting (such as Slack), tagging, or custom reprocessing logic.
- Monitor event source mapping metrics in Amazon CloudWatch (for example, IteratorAge and DeadLetterErrors) and set up alarms for elevated failure rates or retry exhaustion.
Security best practices for Amazon S3 destinations
If you’re using Amazon S3 as a failure destination for your Lambda function, note the following security risk: if the destination bucket is ever deleted but still referenced in your function’s configuration, someone else could recreate a bucket with the same name in their own AWS account. Lambda would continue sending failed invocations to that bucket, and now someone else has access to your data.
To avoid this, you can lock down the permissions in your Lambda function’s execution role so that it can only write to buckets owned by your account. This is done using the s3:ResourceAccount condition key.
The following is an AWS Identity and Access Management (IAM) policy that allows s3:PutObject and s3:ListBucket, but only for buckets in your account:
Make sure to provide your own AWS account ID. This is a simple step that helps prevent failed events from being written to buckets you don’t control, especially in cases where infrastructure changes get out of sync with configuration.
Conclusion
Handling failures gracefully is a key part of building resilient, event-driven applications. Although Amazon SQS and Amazon SNS remain useful for lightweight DLQ scenarios, they aren’t ideal for stream processing pipelines where complete event fidelity is required.
With support for Amazon S3 as a Lambda failure destination, teams can now build stream-based architectures that retain failed payloads durably, without being constrained by message size or stream retention limits.
This makes it straightforward to implement observability, auditing, and replay features, all of which are foundational to building production-grade serverless applications with DynamoDB and Lambda.
We look forward to hearing how you’re using this capability; share your feedback, use cases, or questions in the comments section.