AWS Database Blog
Evolve your Amazon DynamoDB table’s data model
Most software applications evolve over time, often requiring changes to their database schema. Amazon DynamoDB offers schemaless design – you only need to define the primary key attributes when you create a table. This flexibility allows you to store both structured and semi-structured data, making it possible to implement data model updates without requiring service interruptions.
In this post, we show you how to evolve your DynamoDB table’s data model to meet changing application requirements while maintaining zero downtime in production systems. We explore two main techniques with examples that you can apply to your own applications.
- Adding new attributes
- Creating new entities
Add a new attribute to items on your table
As your application’s features evolve, it may require new attributes to store new features on its database. Depending on the requirements of the new feature, you may start creating new items without having to update existing items first. When your application requires a new attribute on your table’s data model that doesn’t affect the access pattern of the application, you can add the new attribute to new items being written to the table.
If you have an access pattern that depends on the new attribute, you can create a global secondary index (GSI) that uses the new attribute in its primary key. Items will be added to the GSI when new items are created with the new attribute or existing items are updated to include the new attribute.
Consider a DynamoDB table that holds orders for a groceries website. Each order is identified by a partition key (CustomerId) and a sort key (OrderId). The following figure shows the data model for the DynamoDB table.
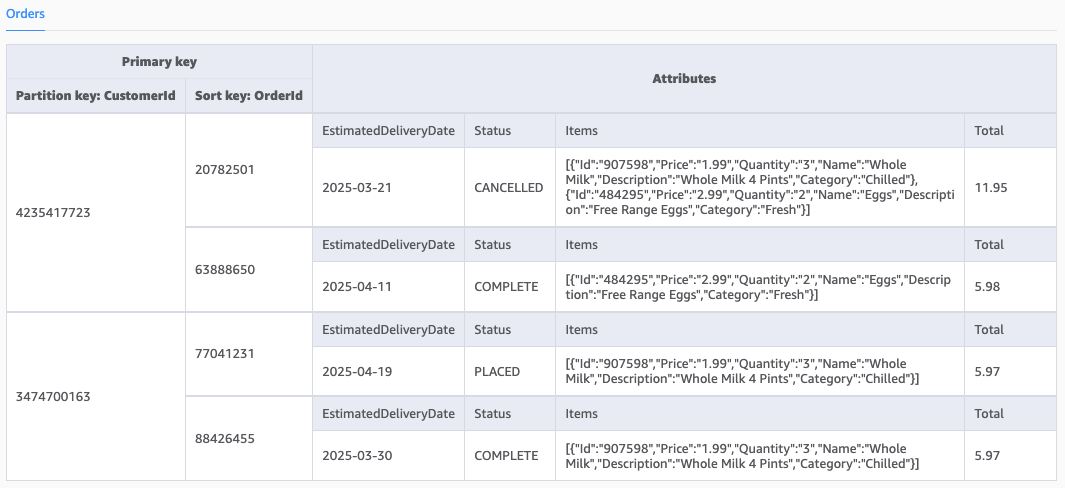
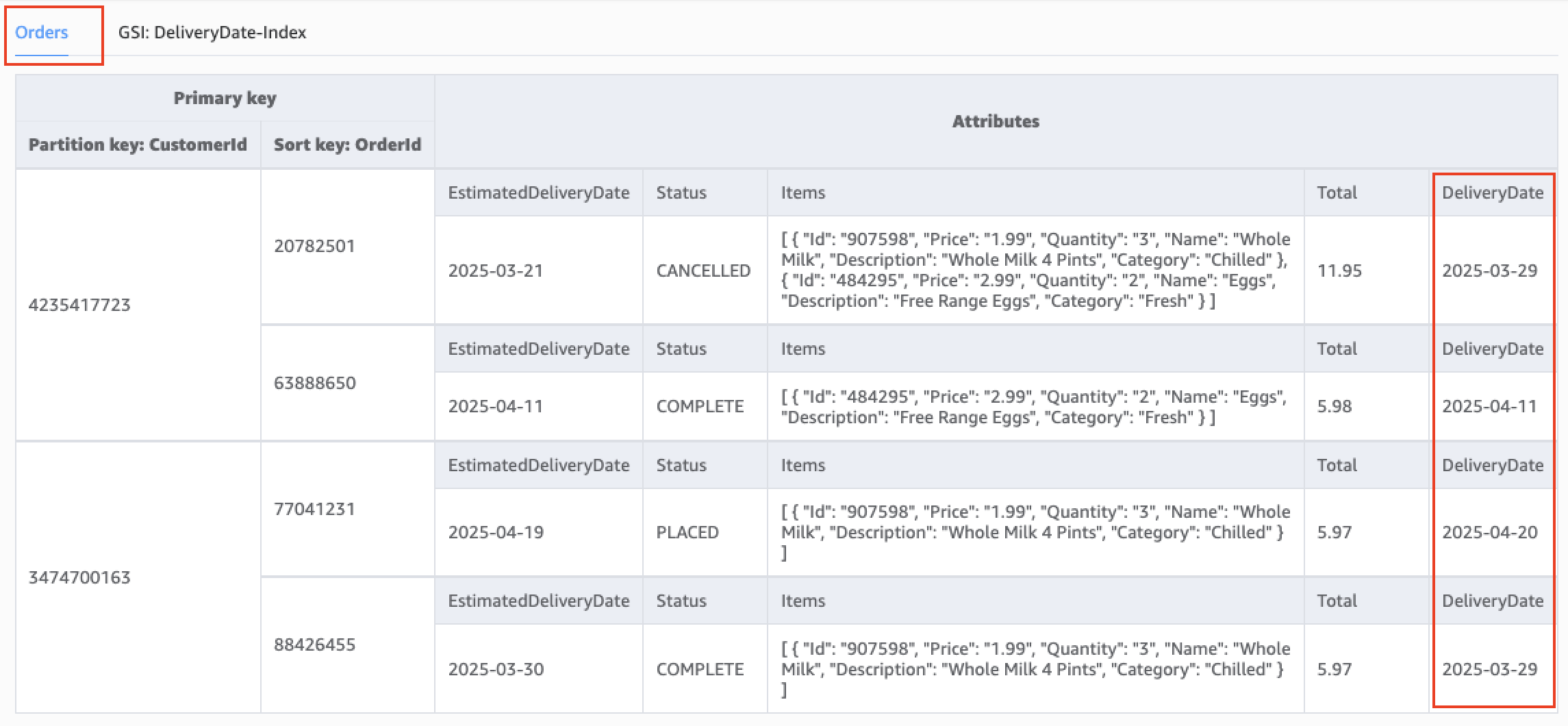
We add a new attribute called DeliveryDate and enable a new access pattern using a GSI called DeliveryDate-Index. This allows the application to search for orders using the delivery date of the order. The following figure shows the data model for the updated DynamoDB table.
The following figure shows the data model for the DeliveryDate-Index GSI.
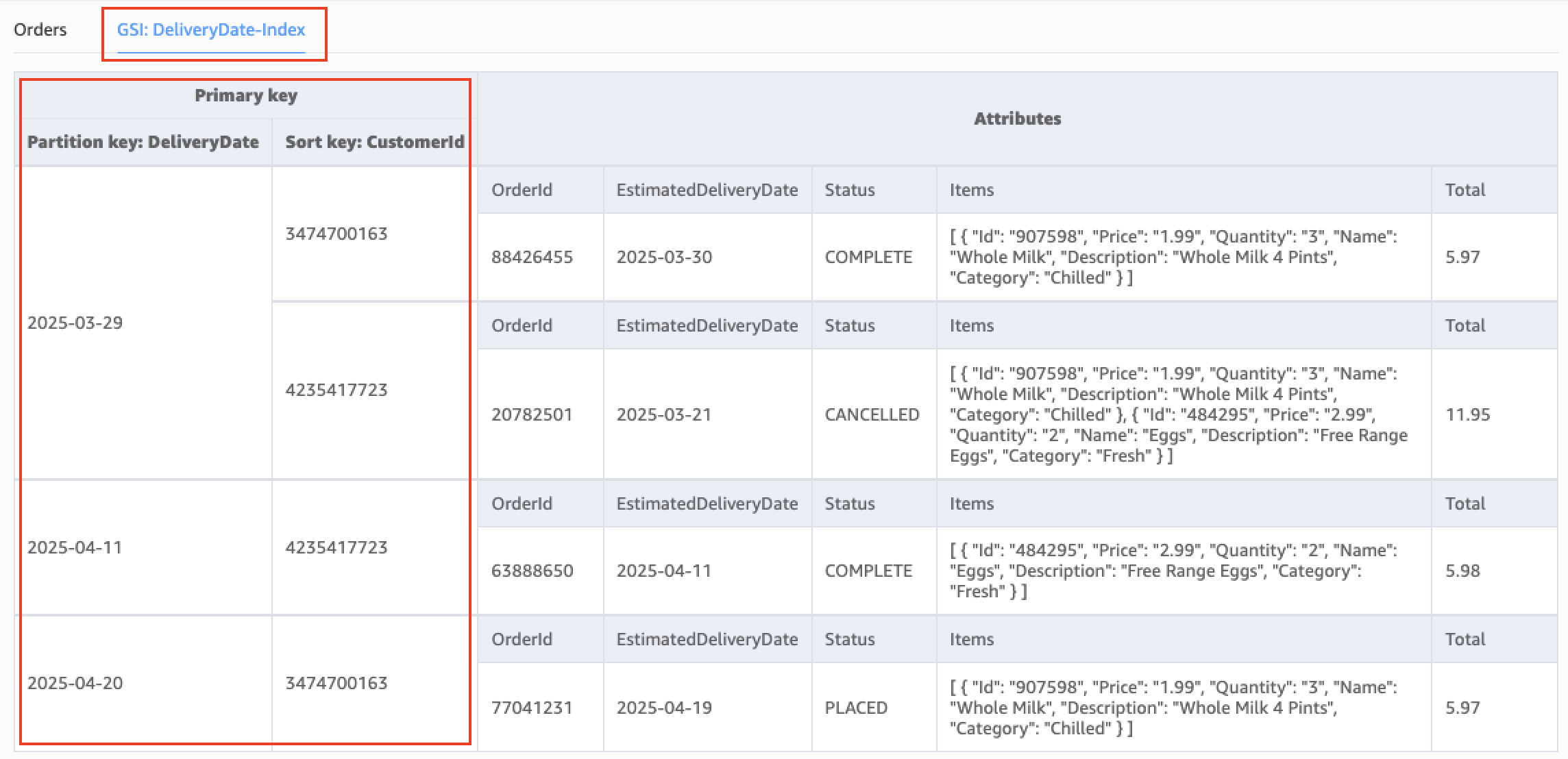
With this update, we can retrieve orders delivered on a given date from the DynamoDB table. The following Python code snippet shows how to retrieve orders from the DynamoDB table using a delivery date:
For existing items on your table that don’t have the new attribute, you can update your application to tolerate instances where items retrieved from your table don’t have the new attribute, then gradually set the attribute on those items. This can increase the operational complexity of your table because you will have to manage different versions of the same entity in your table for an extended period. Alternatively, you can perform a bulk update to items on your DynamoDB table to set the new attribute. This option is quicker and operationally less complex but will incur the costs of performing updates to all items that require the new attribute.
The trade-off in the preceding options is the time it takes to gradually update the existing items on your table versus the cost of performing a bulk update to data on your table. The best approach to choose will depend on your specific use case, the size of your table and your application’s requirements. For new attributes that are needed by most application functions, updating existing items before creating new items is a good option. For new, optional attributes or new attributes on a very large table, a phased approach starting with creating new items may be more practical.
If your application requires all existing items to have the new attribute before you create new items, you can update items in bulk on your DynamoDB table using AWS Step Functions (see Bulk update Amazon DynamoDB tables with AWS Step Functions) or AWS Glue.
Refer to Cost-effective bulk processing with Amazon DynamoDB to learn about preforming cost effective bulk updates to a DynamoDB table.
Add a new entity to your table
Since DynamoDB tables have a flexible schema you can store and effectively retrieve different entities from a single DynamoDB table without having to perform a JOIN operation.
When your application requires a new entity on your table’s data model, the process is similar to adding a new attribute to a table’s data model. If the attributes of the new entity aren’t used by your application’s access patterns, you can add the new entity to your data model and then perform a bulk update to your DynamoDB table if you need one.
If a nested attribute in a new or existing entity on your table is used by your application’s access pattern, you can create a new entity on your table that allows you to support the new access pattern.
Consider a DynamoDB table that holds orders for a groceries website. Each order is identified by a partition key (CustomerId) and a composite sort key (OrderDate#OrderId), and each order has a list of grocery items purchased. The following figure shows the data model for the DynamoDB table.
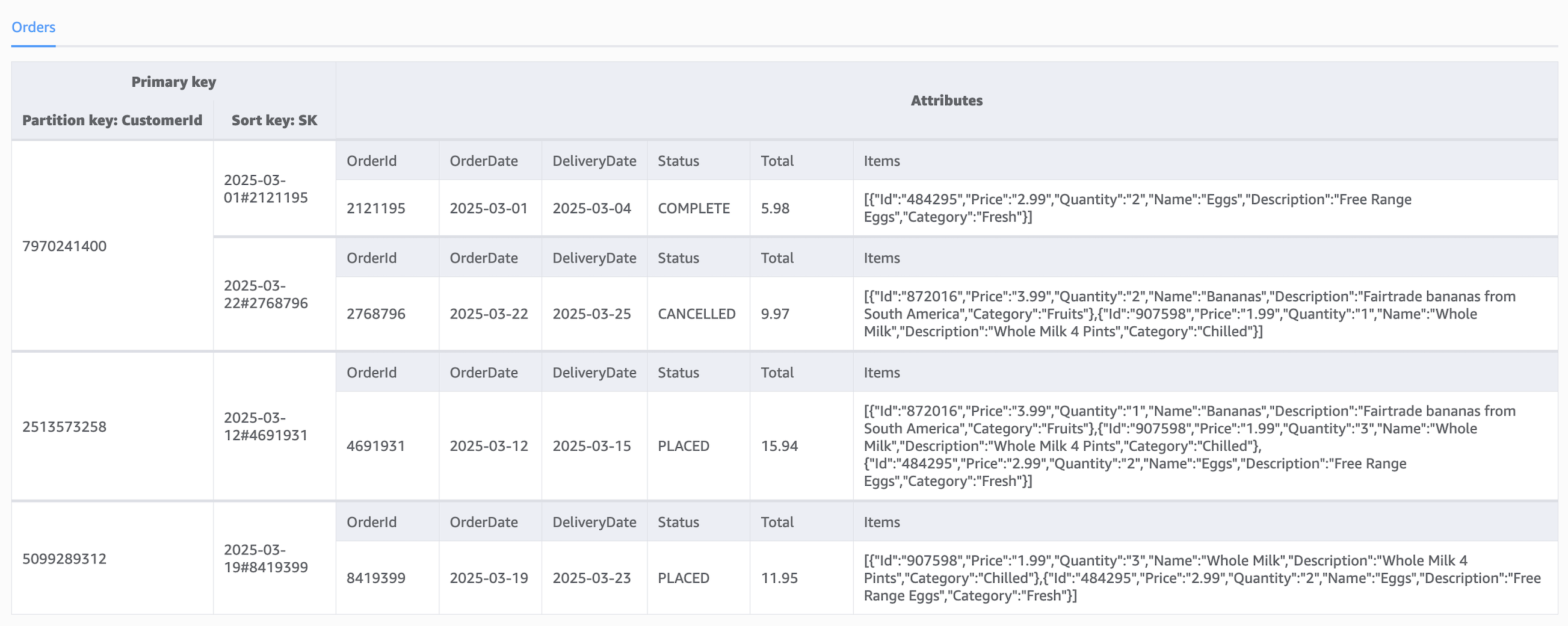
As the website evolves, we want to allow customers to shop from previous orders by marking items in past orders as favourite items. Shoppers will then be able to retrieve a list of items that have been previously tagged as favourite items when they are placing new orders.
To support these features on the website, we add a nested Boolean attribute (Favourite) to the Items entity of the Orders table. This will allow shoppers to tag items in their groceries order as favourite items. We also add a new entity identified by a partition key (CustomerId) and a composite sort key (FAVOURITE#ItemId) to the Orders table. We use a composite sort key with prefix – FAVOURITE# for the new entity so we can retrieve all favourite items for a given CustomerId using the begins_with range query operator.
Refer to the DynamoDB Developer Guide to learn more about best practices for using sort keys to organize data in DynamoDB.
The following figure shows the updated data model for the DynamoDB table.
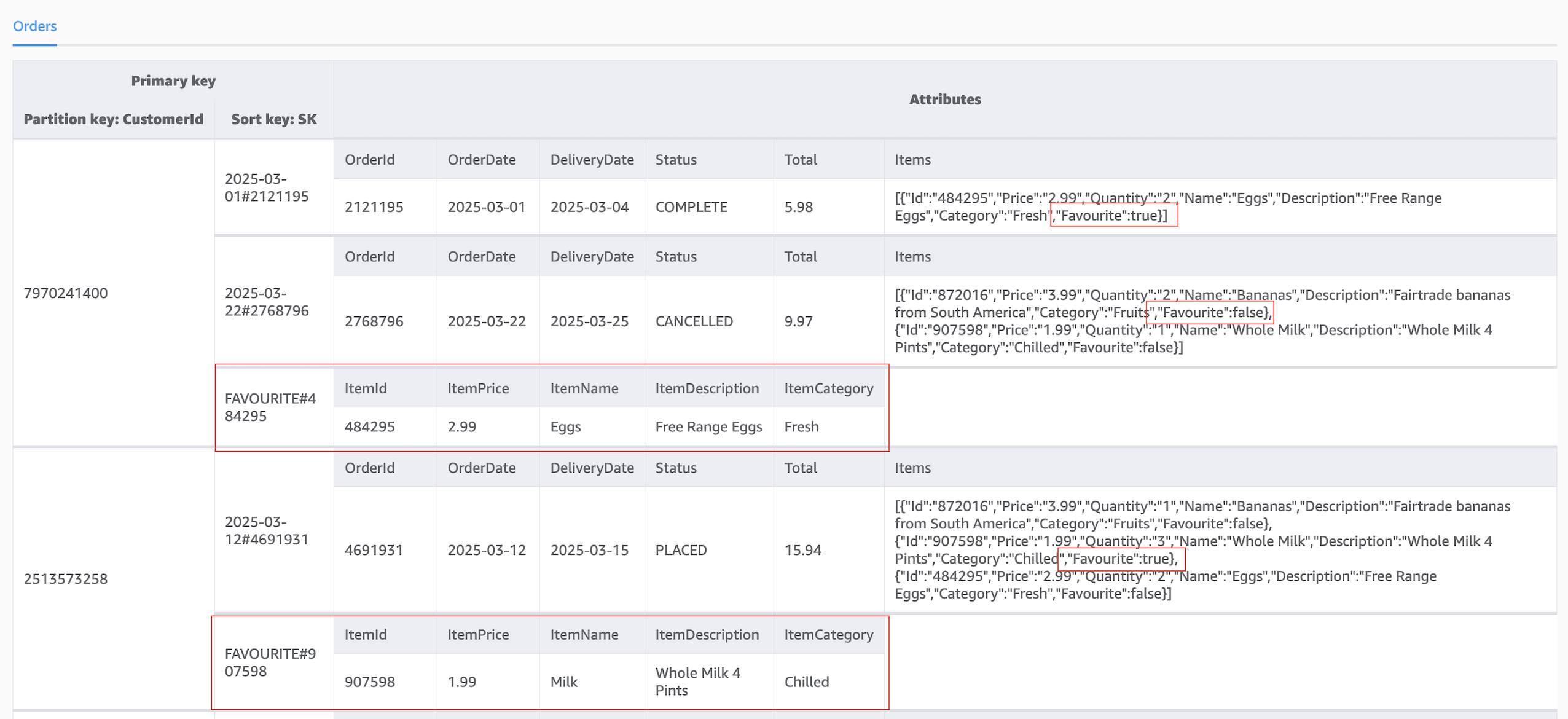
With this update, we can tag a grocery item on an order as a favourite item when writing new orders to the DynamoDB table. We can also retrieve a list of favourite items for a shopper. The following Python code snippet shows how to retrieve favourite items from the Orders table:
Best practices when updating your DynamoDB table model
Consider the following best practices:
- Consider projecting a subset of your item’s attributes to new indexes – When adding a new GSI to your DynamoDB table, consider projecting only attributes you require to your GSI. A projection refers to the attributes copied from your base table to your index. When creating a GSI, you can choose to project your table’s key attributes, specific attributes from your table, or all attributes from your base table. The projection to your GSI cannot modified after an index is created. A new GSI will be required if the data model of an existing GSI on your table needs to evolve. Attributes you project to your index affect the storage and write costs of your index.
- Document changes to your table’s data model – Document the changes to your table’s data model as the features of your application evolve. Include comprehensive details and a rationale behind each change. This will help you maintain consistency across data stored on your DynamoDB tables.
- Complete data integrity checks in your application – DynamoDB doesn’t maintain the relationships between different entities stored on your table. Maintain all entity relationships within your application. We recommend using transactions and conditional writes when performing operations to multiple related items on your DynamoDB tables to maintain consistency and integrity across your data. For example, use a
TransactWriteItemscommand to make sure that when you create a new favourite entity on theOrderstable, the operation to update an order item as a favourite item and the operation to create the favourite item entity are completed as a single operation. The following Python code snippet shows how to perform aTransactWriteItemsoperation on theOrderstable:
In the preceding example, the UpdateExpression sets the value of the item attribute – Favourite of the first item in the Items array to True.
Common pitfalls to avoid
Keep in mind the following troubleshooting tips:
- Minimize the number of indexes on your table – GSIs enable alternate access patterns to data you have stored on DynamoDB. Though GSIs help adapt your data model to your application’s evolving needs, every new index increases your DynamoDB storage and write costs. The provision throughput on every GSI you create is separate to the provisioned throughput of your base table. So, write item, update item and delete item operations to your base table that affect items on your GSI consume the GSI’s write capacity. To optimize costs, consider projecting
KEYS_ONLYto your GSI. This will create the smallest possible GSI for your table, but your application may require two calls to DynamoDB for the new access pattern. The trade-off is between the storage and write costs, and the cost of making two read requests to DynamoDB when using the new access pattern. - Avoid using DynamoDB for analytical access patterns – DynamoDB is ideal for online transaction processing use cases because your access patterns are known. Do not update your DynamoDB table’s data model when your application evolves to include analytical access patterns. DynamoDB offers zero-ETL integration with several AWS services that are purpose-built for analytics use cases, including Amazon OpenSearch Service, Amazon Redshift, and Amazon Simple Storage Service (Amazon S3).
Conclusion
In this post, we showed you how to update the data model for your DynamoDB table when the requirements of your application evolve. You can use the techniques we discussed to update your DynamoDB table’s data model without requiring application downtime.
Try out these techniques for your own use case, and share your feedback in the comments.