AWS Database Blog
Demystifying the AWS advanced JDBC wrapper plugins
In 2023, AWS introduced the AWS advanced JDBC wrapper, enhancing the capabilities of existing JDBC drivers with additional functionality. This wrapper enables support of AWS and Amazon Aurora functions on top of an existing PostgreSQL, MySQL, or MariaDB JDBC driver of your choice. This wrapper supports a variety of plugins, including the Aurora connection tracker plugin, the limitless connection plugin, and the read-write splitting plugin. With these plugins, you can customize the AWS Advanced JDBC Wrapper to seamlessly integrate with your application, providing enhanced features for failover management, monitoring, authentication, load distribution, and much more. For a full list of plugins that the AWS Advanced JDBC Wrapper supports, see the official GitHub repository.
In previous posts, we introduced the AWS Advanced JDBC Wrapper Driver for Aurora, examined how to achieve 1 second or less downtime with the AWS Advanced JDBC Wrapper when upgrading Amazon RDS Multi-AZ DB clusters, and introduced the Advanced Python Wrapper Driver for Aurora. In addition to Python, AWS has also developed similar wrapper drivers for other popular programming languages and protocols, including Node.js, Go, and ODBC drivers for both PostgreSQL and MySQL.
In this post, we discuss the benefits, use cases, and implementation details for two popular AWS Advanced JDBC Wrapper Driver plugins: the Aurora Initial Connection Strategy and Failover v2 plugins. Although the AWS Advanced JDBC Wrapper GitHub repository includes a vast amount of information regarding the wrapper and its plugins, this post dives deeper into individual plugins to help you decide whether they can benefit your use case and assist with their implementation.
Aurora Initial Connection Strategy Plugin
The Aurora Initial Connection Strategy Plugin controls how your application first connects to your Aurora cluster’s read-only endpoint. You can select from different connection strategies using the readerInitialConnectionHostSelectorStrategy parameter:
- Random – Establishes the connection to a random reader instance
- roundRobin – Establishes connections to reader instances in a round robin fashion
- leastConnections – Establishes the connection to the instance with the least connections
- fastestResponse – Establishes the connection to the instance with the fastest response time
While you are using a smart driver, you must still make sure that DNS is not being cached, because this can influence the results you see from the Aurora Initial Connection Strategy Plugin. For best practices on connection handling and management, refer to the Amazon Aurora MySQL Database Administrator’s Handbook.
To configure this plugin, you can set the properties within your Java code. In the following example, we configure the database’s username and password, specify the plugin (initialConnection), and set the initial connection strategy value to random:
try { Properties props = new Properties(); PropertyDefinition.USER.set(props, USERNAME); PropertyDefinition.PASSWORD.set(props, PASSWORD); PropertyDefinition.PLUGINS.set(props, "initialConnection"); AuroraInitialConnectionStrategyPlugin.READER_HOST_SELECTOR_STRATEGY.set(props, "random");}Let’s demonstrate the behavior of the plugin using an Amazon Aurora MySQL-Compatible Edition cluster with three read replicas. We will open 100 connections to this cluster using the cluster’s read-only endpoint. These connections will continue to perform SQL queries for the duration of the test, making sure they remain open throughout the entire process.
Random initial connection strategy
The following graph shows the distribution of 100 connections when using the random initial connection strategy for the readerInitialConnectionHostSelectorStrategy parameter. The random initial connection strategy is the default selection strategy for this plugin.
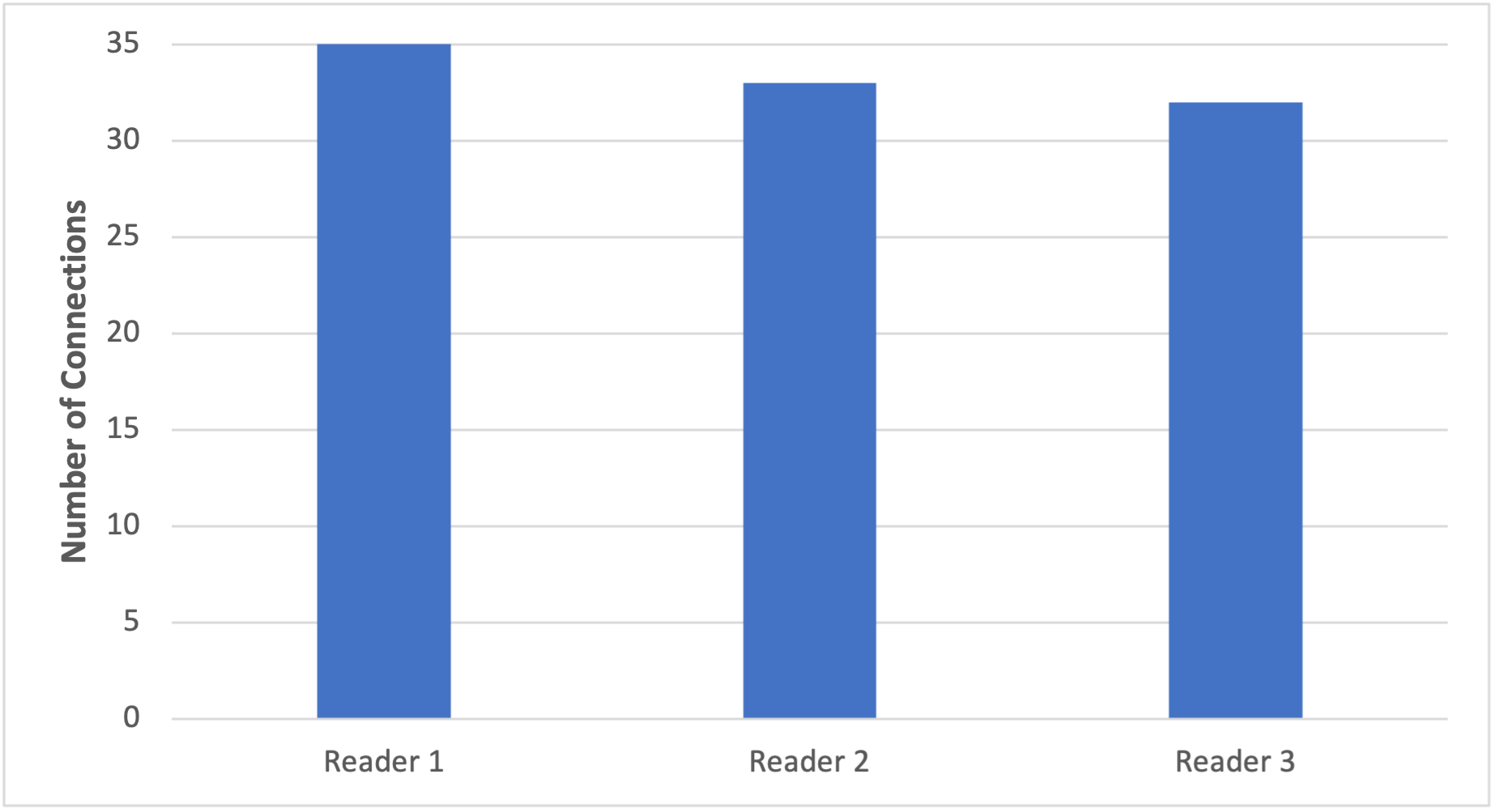
Figure 1. Graph displaying distribution of connections when utilizing the “random” initial connection strategy
As seen in Figure 1, our connection distribution between the three readers is fair. With this selection strategy, each reader gets an equal chance to receive the newly opened connection. In the graph, 35% of the connections were established with reader 1, 33% of the connections were with reader 2, and 32% of the connections were with reader 3.
Round robin initial connection strategy
The following graph shows a test for the roundRobin initial connection host selector strategy. As mentioned previously, this strategy will select a reader instance by taking turns with available DB instances in a cycle. However, you can weight your reader instances with the roundRobinHostWeightPairs parameter. This means you can configure the relative distribution of connections to specific hosts in one connection cycle. For more information, refer to Reader Selection Strategies. In this example, we use the default weights for each host, which will provide us with a near-even distribution.
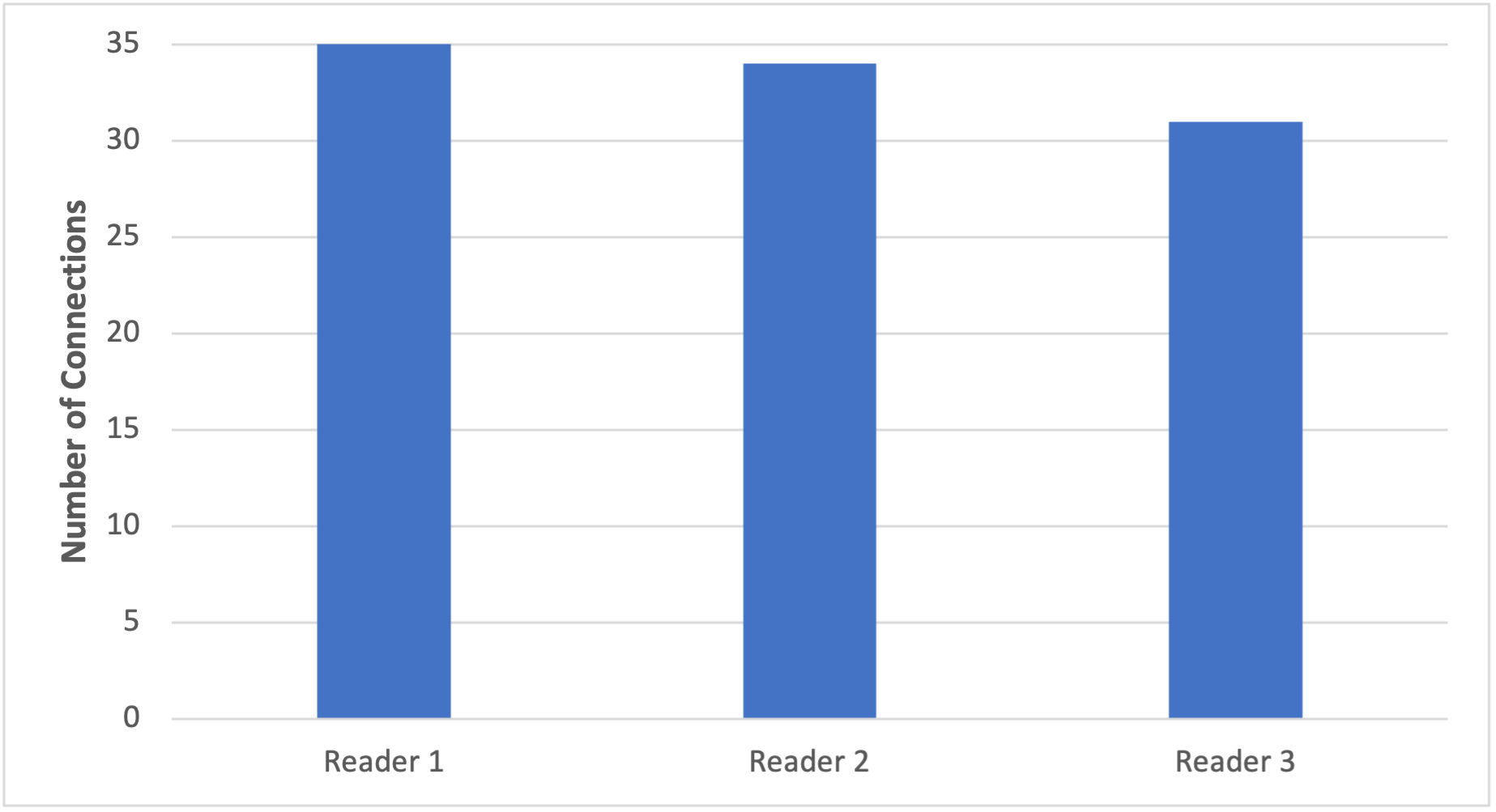
Figure 2. Graph displaying distribution of connections when utilizing the “roundRobin” initial connection strategy with 100 connections established over 8 minutes.
We see in Figure 2 that the distribution of connections between the three readers was almost as expected but not entirely. Instead of a 33/33/34 split between the readers we got 35/34/31. To understand why this happened, we must discuss another plugin that is enabled by default within the AWS Advanced JDBC wrapper called the Failover v2 plugin.
By default, when using the Failover v2 plugin, we have a clusterTopologyRefreshRateMs of 30,000 milliseconds (30 seconds). When a refresh to the cluster topology occurs, the ongoing round-robin cycle is interrupted and must restart using the newly refreshed topology. In the preceding example, we generated 1 connection every 5 seconds, which means in order to establish 100 connections, it took over 8 minutes. During this time, there were at least 16 topology refreshes, which could have impacted the current round robin cycle.
In the following graph we instead generate the 100 connections to our database in less than 1 second, which will avoid the cluster topology refresh and produce the near-even distribution that was previously expected.
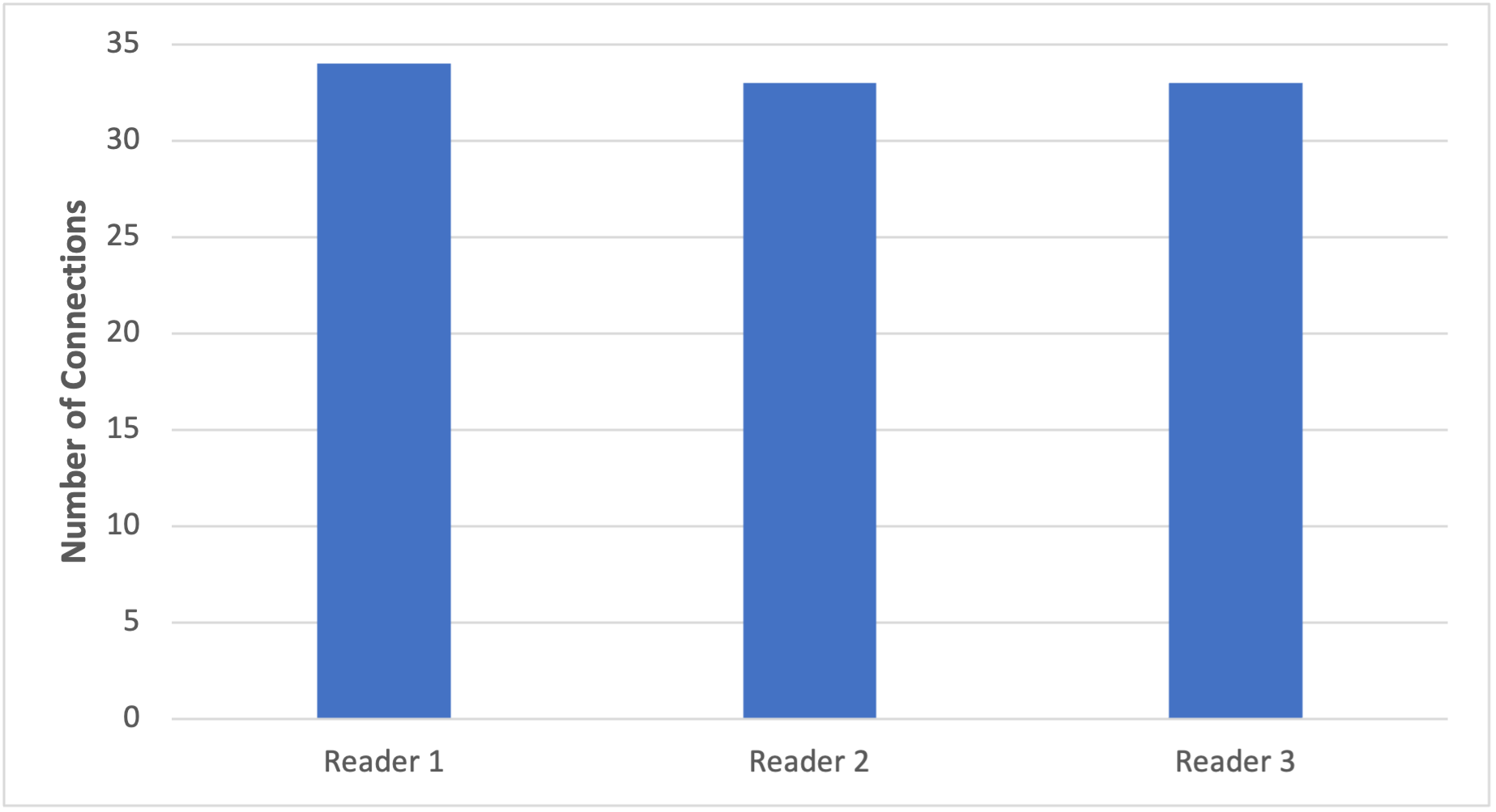
Figure 3. Graph displaying distribution of connections when utilizing the “roundRobin” initial connection strategy with 100 connections established over 1 second.
Least connections initial connection strategy
Next, let’s configure the readerInitialConnectionHostSelectorStrategy parameter to leastConnections. The least connections strategy selects which reader instance to connect to based on the number of active connections within your application’s internal connection pool (such as HikariCP, or C3P0). Important considerations for using the leastConnections strategy:
- This strategy requires an internal connection pool to be already configured in your application
- The plugin only tracks connections from its own connection pool instance
- If you have multiple applications or connection pools connecting to the same Aurora cluster, the
leastConnectionsstrategy may not provide optimal load distribution since each pool only has visibility to its own connections - If you set the connection property to
leastConnectionswithout an internal connection pool configured, an exception will be thrown, similar to the following:
java.lang.UnsupportedOperationException: Unsupported host selection strategy 'leastConnections'.During the test with the leastConnections configuration 100 connections were created over 1 second. This resulted in a near-even distribution of connections between our reader nodes, with 33% of the distribution going to readers 2 and 3, and reader 1 receiving 34%. The reason for the near even distribution is because during the duration of the test, we kept the connections to the database active by running transactions. This meant the AWS Advanced JDBC Wrapper’s initial connection strategy plugin was able to properly determine which reader instance had the least number of active connections from within the internal connection pool. It does this with the LeastConnectionsHostSelector.getHost() function, and can then route the newly formed connection to the instance with the least active connections in the connection pool.
The following diagram demonstrates how the leastConnections strategy decides which reader instance to form a connection with.
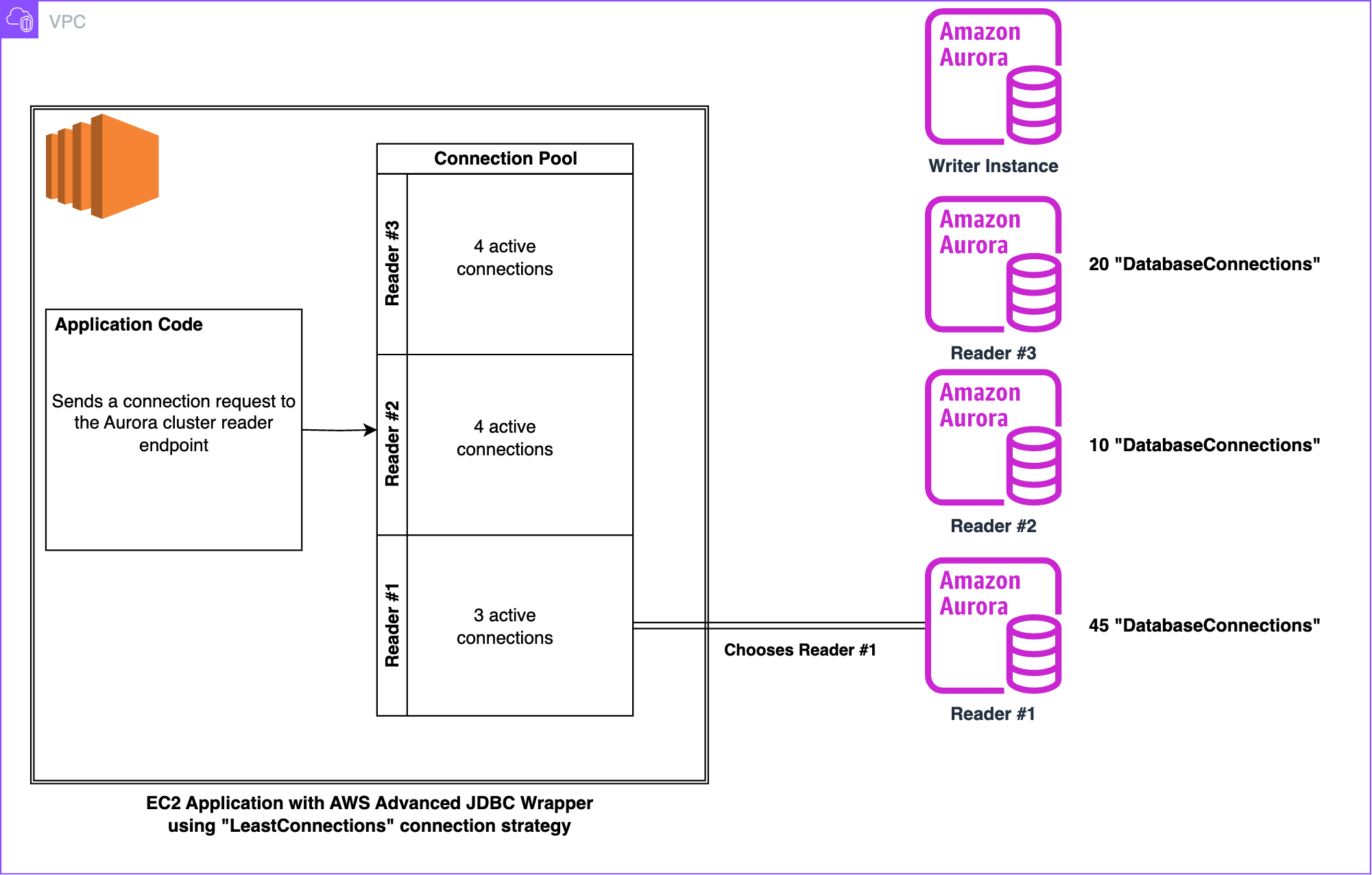
Figure 4. Diagram visualizing how connections are distributed when utilizing the “leastConnections” initial connection strategy
In the preceding figure, Reader 2 has only 10 total database connections which is by far the least within the cluster. However, the application decides to create a connection with Reader #1, which has the most total connections. The reason for this is because the internal connection pool only tracks the connections it has formed with the Aurora cluster. Based on the knowledge of the internal connection pool, Reader 1 actually has the least connections, with three. This behavior is important to keep in mind when you have many different applications or clients connecting to your Aurora cluster.
Fastest response initial connection strategy
The fastestResponse connection strategy connects to the host that responds the fastest. It identifies the fastest response from the reader instances within the cluster and then stores it within a cache for further use. To use this plugin, you must load the fastestResponseStrategy plugin as shown in the following Java code:
props.setProperty(PropertyDefinition.PLUGINS.name, "initialConnection,fastestResponseStrategy");The connection distribution is dependent on many factors, including but not limited to the reader instance’s Availability Zone, resource contention, and availability. If latency is the primary concern for your application, consider using the fastestResponse connection strategy to minimize potential latency when generating connections. Additionally, by implementing a connection pool, you can reuse existing connections, thereby reducing the latency associated with establishing new connections.
Failover v2 plugin
The Failover v2 Plugin is an enhanced version of the original Failover Plugin, offering several improvements. This plugin uses the wrapper’s knowledge of the Aurora cluster topology to minimize downtime during failover events when the primary DB instance becomes unavailable. It achieves this by reducing reconnection time for existing database connections. You can configure various settings, including:
- Prioritization of specific DB instances that the wrapper attempts to reconnect to in the event of a failure
- Timeout values
- The
failoverReaderHostSelectorStrategywhich uses the same reader selection strategies outlined in the previous section
Although most of the information and suggestions from the original Failover Plugin apply to the Failover v2 Plugin, there are three key differences:
- Each connection performs its own failover process
- Each connection calls the
RdsHostListProvidermonitoring component in the same thread to fetch the topology - A reader node may fetch the topology and it is stale for a short period after the failover
In the event of a DB instance failure, Aurora initiates a failover on the cluster to promote a new primary DB instance in attempt to recover. During this process, the JDBC driver intercepts related communication exceptions and performs its own failover process for each connection. In the original version of the plugin, each failover process is handled independently. Although this approach has the benefit of not being reliant on the state of other connections, it can cause a significant client-side load if there are large amounts of failover processes at the same time. This approach is visualized in Figure 5:

Figure 5. Diagram visualizing how each connection triggers its own independent failover process to detect a new writer
The Failover v2 Plugin implements an optimized method, where the process of detecting and confirming the Aurora cluster topology is handled by the central topology monitoring component MonitorRdsHostListProvider, which runs in a separate thread. After it has confirmed the topology and the new writer is verified, each connection waiting on the topology can resume and reconnect to the required DB instance. This approach minimizes the required resources and scales much better for large numbers of connections than the original Failover Plugin. Additionally, the MonitorRdsHostListProvider component fetches the up-to-date topology from a writer DB instance, whereas the original Failover Plugin might fetch the topology from a reader DB instance, which can be stale. Figure 6 illustrates this process.

Figure 6. Diagram visualizing how the MonitorRDSHostListProvider streamlines failovers
To showcase how this plugin can minimize downtime for existing connections in the event of a DB instance failure, we perform tests against an Aurora MySQL cluster with three read replicas. We simultaneously use the sysbench tool to simulate a write and read workload against the cluster’s writer endpoint, which will create new tables and repeatedly insert 100,000 new rows. While this load is running, we repeatedly execute a write transaction with several UPDATE queries, as well as a SELECT query that reads from the connected host. With this workload running, we scale up the writer instance class, which initiates a failover within the Aurora cluster and forces the AWS Advanced JDBC Wrapper to reconnect. The following graph shows the reconnection time in multiple tests for the same workload. One test utilizes the AWS Advanced JDBC Wrapper with the Failover v2 Plugin enabled and the other test has the plugin disabled while still utilizing the AWS Advanced JDBC Wrapper.
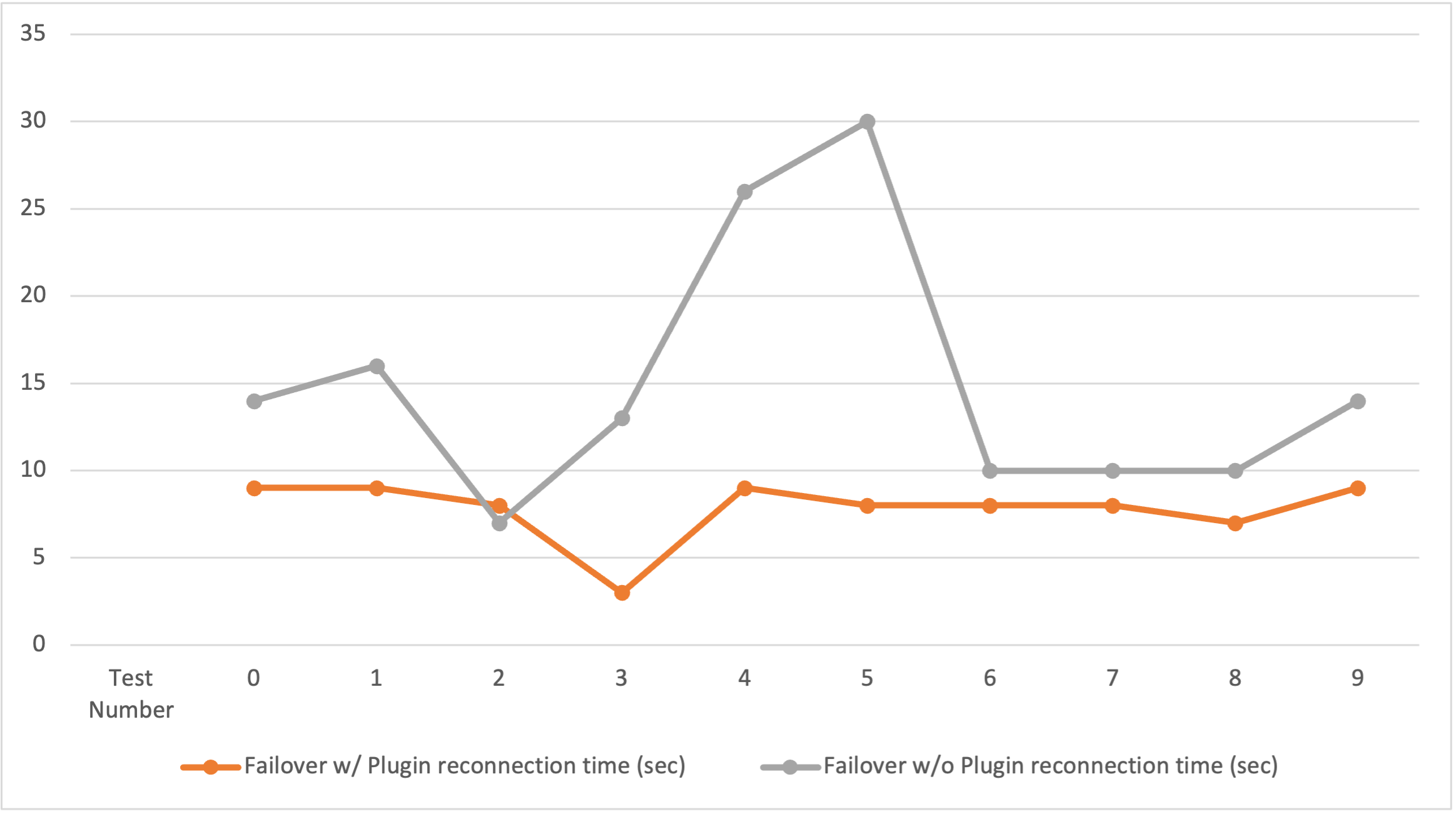
Figure 7. Graph visualizing the time it takes in seconds to reconnect with and without the Failover v2 Plugin over 10 tests.
With the Failover v2 plugin enabled the client averaged a reconnection time of 7.8 seconds across all tests, whereas the test without the Failover v2 plugin averaged 15 seconds. The results demonstrate that the Failover v2 plugin consistently achieves reconnection times faster than just using the bare AWS Advanced JDBC Wrapper. It also exhibits more consistent performance due to its mechanism to actively query the cluster topology. The Failover v2 Plugin helps you minimize downtime during Aurora cluster failovers and provides options for prioritization of certain DB instances for their connections. The values for parameters like failoverMode, failoverReaderHostSelectorStrategy, and other timeout-related parameters are determined by the application requirements and Aurora cluster architecture that you decide to use.
Conclusion
In this post, we demonstrated in detail how the Aurora Initial Connection Strategy Plugin and Failover v2 Plugin work within the AWS Advanced JDBC Wrapper. These plugins offer advanced management capabilities for Aurora failovers and establishing connections. By understanding the inner workings of these plugins you can better configure your Aurora environment. Try out these plugins in your own use case, and share your feedback and questions in the comments section.