AWS Database Blog
Category: Intermediate (200)

Introducing Amazon Neptune Global Database
Today, Amazon Neptune announced the general availability of Amazon Neptune Global Database. You can use Neptune Global Database to build graph applications across multiple AWS Regions using the same graph database. Neptune Global Database is available in the US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Europe (Ireland), Europe […]

PostgreSQL bi-directional replication using pglogical
July 2023: This post was reviewed for accuracy. PostgreSQL supports block-based (physical) replication as well as the row-based (logical) replication. Physical replication is traditionally used to create read-only replicas of a primary instance, and utilized in both self-managed and managed deployments of PostgreSQL. Uses for physical read replicas can include high availability, disaster recovery, and […]

Architect a disaster recovery for SQL Server on AWS: Part 2
In this series of posts (Part 1, Part 2, Part 3 and Part 4), we compare and contrast the disaster recovery (DR) solutions available for Microsoft SQL Server on Amazon Elastic Compute Cloud (Amazon EC2). This post introduces three methods for implementing DR for SQL Server on AWS: SQL Server backup and restore, SQL Server […]

Architect a disaster recovery for SQL Server on AWS: Part 1
In today’s world, it’s just a matter of time before disaster happens, and when it happens it’s essential to recover your SQL Server databases and bring the systems online with minimal data loss and downtime. To respond to and recover from an outage of SQL Server database access, high availability (HA) and disaster recovery (DR) […]

How Zulily drives discovery shopping using Amazon Kinesis Data Analytics and Amazon DocumentDB
This is a guest post by Sergey Podlazov – Director of Engineering (Shopping Experience) at Zulily, Senthil Kumar, Sr. Solutions Architect, AWS, and Praveen Chamarthi, Sr. Technical Account Manager, AWS August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog […]

Managed disaster recovery with Amazon RDS for Oracle cross-Region automated backups – Part 1
Today, customers using Amazon Relational Database Service (Amazon RDS) for Oracle have several managed high availability (HA) and disaster recovery (DR) capabilities to choose from based on your business requirements and use cases: With Amazon RDS Multi-AZ, you get enhanced availability and durability for database (DB) instances within a specific AWS Region. This is often […]

How to index on Amazon DocumentDB (with MongoDB compatibility)
October 2024: This post was reviewed and updated for accuracy. Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6, 4.0, and 5.0 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB […]
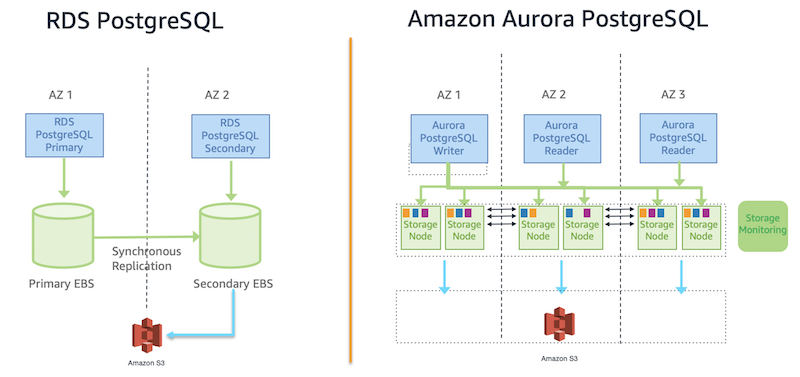
Deep dive on Amazon Aurora and Amazon RDS for PostgreSQL architecture and features
April, 2026: Aurora Serverless v2 has been renamed Aurora serverless. No action required. May 2024: This post was reviewed and updated for accuracy. If you’re considering migrating your self-hosted PostgreSQL database or transitioning your commercial databases to PostgreSQL on AWS, you’ll need to choose the database service that best aligns with your requirements. AWS offers […]
Key considerations in moving to Graviton2 for Amazon RDS and Amazon Aurora databases
Amazon Relational Database Service (Amazon RDS) and Amazon Aurora support a multitude of instance types for you to scale your database workloads based on your needs (see Amazon RDS DB instance classes and Aurora DB instance classes, respectively). In 2020, AWS announced Amazon M6g and R6g instance types for Amazon RDS and recently announced the […]

Performance impact of idle PostgreSQL connections
July 2023: This post was reviewed for accuracy. The first post of this series, Resources consumed by idle PostgreSQL connections, talked about how PostgreSQL manages connections and how even idle connections consume memory and CPU. In this post, I discuss how idle connections impact PostgreSQL performance. Transaction rate impact When PostgreSQL needs data, it first […]