AWS Database Blog
Building a job search engine with PostgreSQL’s advanced search features
In today’s employment landscape, job search platforms play a crucial role in connecting employers with potential candidates. Behind these platforms lie complex search engines that must process and analyze vast amounts of structured and unstructured data to deliver relevant results. Building such systems requires database technologies that can handle complex queries, full-text search, semantic search for semantic understanding, and geospatial capabilities for location-aware recommendations.
PostgreSQL stands out as an ideal solution for implementing job search platforms due to its comprehensive search capabilities. PostgreSQL offers a unique combination of full-text search, vector similarity search, and geospatial search within a single database system. This convergence of capabilities enables developers to build rich search experiences without managing multiple specialized systems.
This post explores how to use PostgreSQL’s search features to build an effective job search engine. We examine each search capability in detail, discuss how they can be combined in PostgreSQL, and offer strategies for optimizing performance as your search engine scales.
Additionally, we discuss how the techniques presented in this post are broadly applicable to many search-driven applications across different domains, such as e-commerce product discovery and content recommendation.
The anatomy of a modern job search engine
Before diving into PostgreSQL’s specific search capabilities, it’s important to understand the fundamental components and requirements of a modern job search platform. At its core, a job search engine consists of two primary components:
Data repository – The foundation of any job search platform is its database serving as a repository for job listings from various sources. This database is continuously updated through web crawlers, direct employer submissions, and integrations with job boards and recruitment platforms. The repository additionally stores profiles and resumes of job candidates.
Search engine -The search engine allows for bidirectional search — employers seeking candidates and candidates seeking opportunities, processing queries, analyzing and joining structured data (like job titles, locations, and salary ranges) and unstructured content (like job descriptions and candidate resumes). An advanced search engine goes beyond simple keyword matching to understand context, handle synonyms, recognize related concepts, and factor in location-based constraints.
An effective job search engine requires:
- Full-text search -this provides precise lexical matching for job titles, skills, and organization names. It supports exact phrase matching and typo-tolerant fuzzy searches for partial matches. Full-text search excels when users can articulate specific search criteria, though it lacks contextual understanding.
- Semantic search – vector-based similarity search introduces important contextual understanding by interpreting job descriptions and candidate qualifications beyond literal terminology. This dimension captures nuanced professional relationships and implicit requirements and qualifications that keyword matching would miss, enabling more intelligent matching between candidates and positions.
- Geospatial search – location intelligence refines results by incorporating geographic considerations, allowing users to discover opportunities within specific distance parameters, commute thresholds, or regional boundaries. This connects professional qualifications with physical job market realities.
By integrating these complementary search techniques, job search engines can process elaborate queries that simultaneously evaluate exact terms, contextual meaning, and geographic considerations, delivering more relevant matches in an increasingly complex employment landscape.
PostgreSQL as a comprehensive search solution
PostgreSQL serves dual purposes as both a robust data repository and an advanced search engine. Through built-in features and extensions, PostgreSQL can handle all three essential search dimensions within a single system:
- Full-text search using built-in types like tsvector, tsquery, and GIN indexes
- Vector similarity search for semantic matching through the pgvector extension
- Geospatial queries via the PostGIS extension with GiST indexes
A job search engine uses PostgreSQL to store job listings, job candidates’ profiles, provide real-time full-text search and semantic search across millions of resumes and job listings, and find job matches within specified geographical radius. This unified approach simplifies architecture, reduces operational complexity, and enables hybrid search strategies.
Consider the following simple data model for a job search engine, composing of “job” and “resume” tables. These tables have columns of type tsvector, vector and geometry to hold vector data, vector embedding, and geometry for the location of the job and the candidate.
Now, let us explore how a job search engine can implement different search techniques in PostgreSQL.
Full-text search in PostgreSQL
PostgreSQL’s full-text search capabilities provide a solid foundation for matching job listings and candidate profiles based on specific keywords, phrases, and requirements. When the engine ingests job listings, and resumes, it employs tokenization techniques, breaking documents into lexemes using predefined linguistic dictionaries. These dictionaries guide the process of normalizing text, removing stop-words, and applying stemming to reduce words to their root forms. The resulting standardized lexemes are then mapped into an inverted index, creating an efficient structure for rapid retrieval. When a candidate enters a search query, the engine matches the query tokens against indexed job description tokens. The system ranks results based on term frequency and the lexical matches, providing a list of relevant job opportunities. The following diagram explains the process.
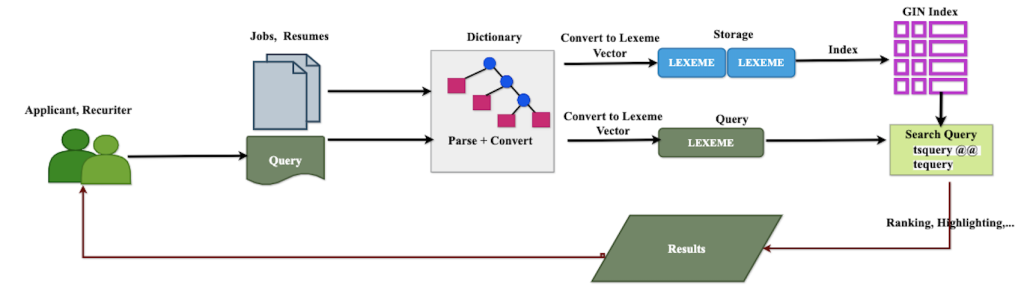
Full-Text Search in PostgreSQL
PostgreSQL full-text search component consists of:
- Dictionaries – PostgreSQL uses dictionaries to enable language-aware lexeme parsing, stemming, and stop-word removal. These dictionaries transform raw text into standardized lexemes (root forms of words), ensuring that variations like “working,” “worked,” and “works” all match a search for “work.” PostgreSQL includes built-in dictionaries for many languages and allows custom dictionaries for specialized terminology.
- Text processing – The to_tsvector function converts documents (like job descriptions or resumes) into a special tsvector format that stores normalized lexemes with their positions and optional weights. Similarly, the to_tsquery function processes search queries into a format optimized for matching against these document vectors.
- Match operator -The match operator (@@) evaluates the similarity between a document vector and a query, returning true if there’s a match.
- Ranking functions – Functions like ts_rank and ts_rank_cd determine the relevance of matches based on factors like term frequency and document structure, allowing results to be sorted by relevance.
The following example finds candidates with “JavaScript” and either “React” or “Angular” specific skills but excludes those mentioning “WordPress”.
Advanced full-text search features
PostgreSQL offers several advanced features for more complex full-text search:
Proximity search – Find words that appear near each other in a document:
This would match “software engineering” but not “software testing engineering” where the terms aren’t adjacent.
Simple ranking – makes sure that the most relevant results are ranked higher. Ts_rank considers the frequency of words; the more tokens that match the text, the higher the rank. You can rank resumes by frequency of the word “Amazon” in the job skills requirements
Weighted ranking – assign different importance to different parts of a document.
- A (most important): Highest weight
- B (high importance): Second highest
- C (medium importance): Third level
- D (lowest importance): Default weight
Here is an example:
Fuzzy matching – pg_trgm extension complements full-text search, enabling similarity-based matching. This capability is important for job search platforms where users might misspell technical terms or job titles.
Indexing for performance
PostgreSQL provides specialized index types for optimizing full-text search performance:
GIN (Generalized Inverted Index) – Ideal for static text data where search speed is prioritized over update speed. GIN indexes excel with tsvector columns and are the preferred choice for most job search scenarios.
GiST (Generalized Search Tree) – More balanced between search and update performance, consuming less space but potentially slower for complex queries. GiST indexes is more appropriate for applications with frequent updates.
Semantic search with pgvector
While full-text search excels at finding exact matches, it lacks understanding of meaning and context. For instance, a full-text search wouldn’t naturally understand that “software engineer” and “developer” represent similar roles, or that “cloud architecture” relates to “AWS expertise.” This is where semantic search through vector embeddings is valuable.
Understanding vector embeddings
Vector embeddings represent text as points in a high-dimensional space, where the geometric relationships between these points capture semantic relationships. Similar concepts appear closer together in this vector space, even if they share no common terms. The pgvector extension adds vector data types and operations to PostgreSQL, enabling storage of these embeddings directly in the database and performing efficient similarity searches.
Implementing semantic search
The following diagram shows how semantic search is implemented in PostgreSQL.
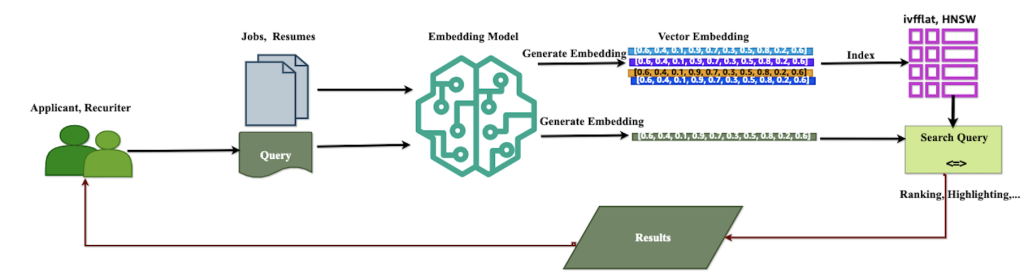
Semantic Search in PostgreSQL
The following are the steps for implementing vector search:
- Generate embeddings – Convert job descriptions and candidate resumes into vector embeddings. This typically involves using machine learning models available through services such as Amazon Bedrock. Here is an example of embeddings generated for job postings.
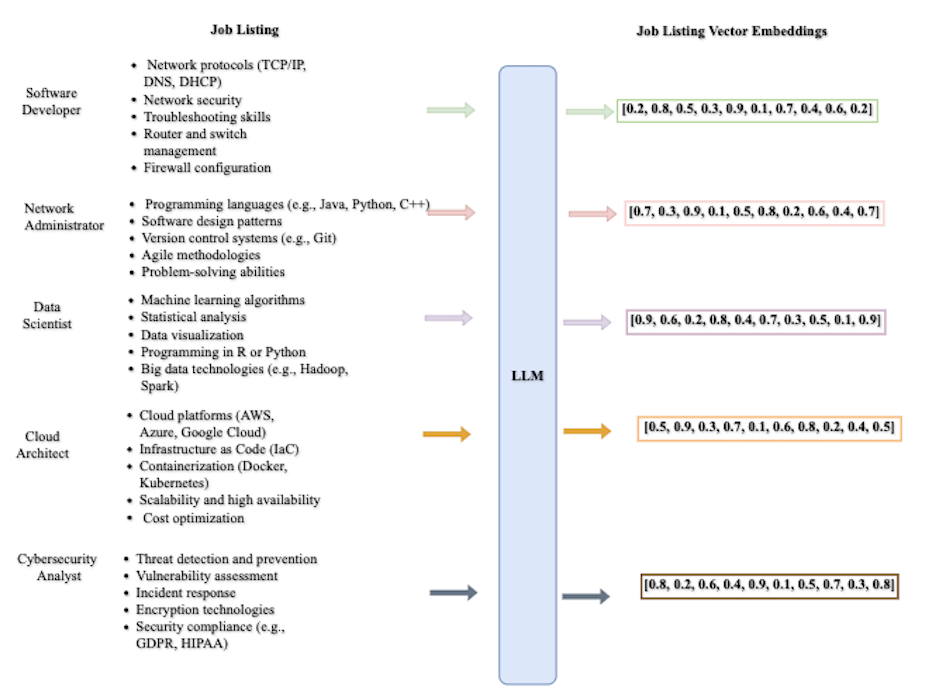
Vector Embedding
- Store vectors – store the embeddings in PostgreSQL using pgvector’s vector data type:
- Similarity search – Use vector operators to find similar items by calculating the distance between the vector embeddings, as depicted in the following diagram.
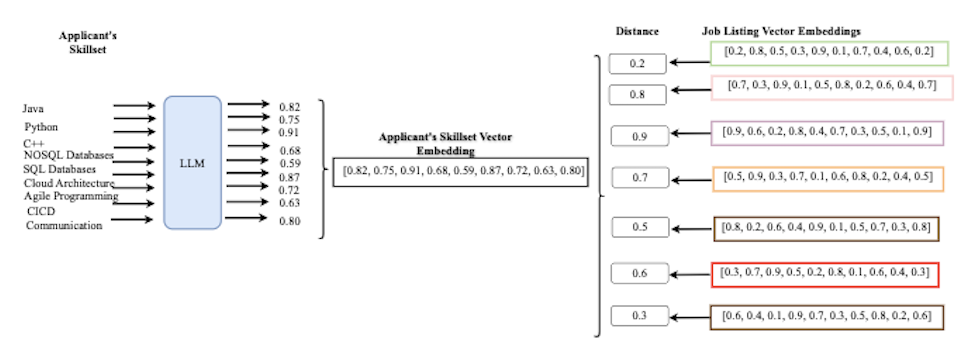
Vector Similarity Search
Following is a query calculating the distance between an applicant’s skillset embedding and the embeddings for the job postings.
The <-> operator calculates the distance between vectors. A smaller distance indicates greater similarity.
Optimizing vector search performance
As size of dataset grows, performance becomes critical for vector searches. PostgreSQL offers specialized index types for vector similarity searches:
IVFFlat index – Divides the vector space into smaller partitions for more efficient searching:
HNSW index – Hierarchical Navigable Small World graph index provides even faster approximate nearest neighbor searches:
These indexes dramatically improve search performance at the cost of some precision, making them ideal for large job search platforms where sub-second response times are important.
Geospatial search with PostGIS
Location is often a critical factor in job searches. Candidates typically seek positions within commuting distance, while employers target local talent pools. PostgreSQL’s PostGIS extension provides geospatial capabilities for implementing location-aware job searches.
Geospatial search implementation
The following captures the geospatial search architecture and the implementation steps in PostgreSQL.
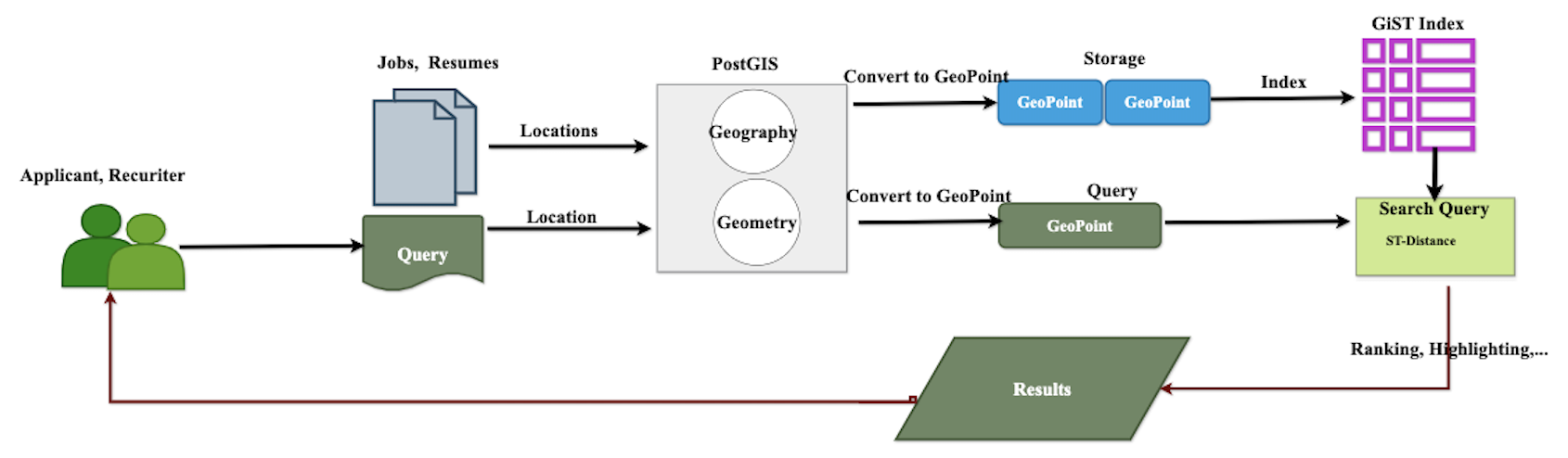
Geospatial Search in PostgreSQL
- Install and enable PostGIS.
- Add geometry or geography columns.
- Index using GiST indexes.
- Perform geospatial queries using geospatial functions, such as ST_DWithin and sort locations by distance using ST_Distance, as needed. The following query shows an example.
Combining search techniques
While each search technique offers distinct advantages, a hybrid search uses the strengths of each method to deliver more relevant results across diverse use cases. A hybrid of full-text search and semantic search is particularly effective for complex queries where both specific terms and overall meaning are important. Using a full-text search to match user preferences and similarity search to expand recommendations to related content can be ideal to give users a more comprehensive view of the available options. We can match specific skills or job titles (full-text search) while also understanding related roles or transferable skills through similarity search. For queries where user intent might not be fully captured by exact keyword matching, similarity search can help find relevant results, and full-text search makes sure no exact matches are missed. To make a job search, location aware, geo-contextual search can be combined with full-text search or semantic search, to further enhance the search results.
In PostgreSQL’s hybrid search, different search methods independently rank results using their own relevance algorithms. To combine these diverse rankings meaningfully, the Reciprocal Rank Fusion (RRF) algorithm merges them using a specific formula that assigns each result a unified score
The following is an example of hybrid search that shows top candidates for job engineering positions considering distance and skill match.
Performance and scaling considerations
As your job search platform grows in terms of data volume, user base, and query complexity, performance optimization becomes increasingly important. PostgreSQL offers various mechanisms to ensure the search engine remains responsive at scale.
Job search applications face several specific performance challenges:
- Computational complexity – Hybrid search queries combining multiple techniques can be resource-intensive, especially when they involve complex operations like vector similarity calculations or geospatial distance measurements.
- Indexing overhead – Maintaining specialized indexes for different search techniques increases storage requirements and can slow write operations.
- Result merging – Combining results from different search algorithms often requires complex join operations and scoring calculations.
- Concurrent query load – Popular job search platforms must handle many simultaneous search requests, especially during peak usage periods.
PostgreSQL offers several features to address performance challenges:
- Parallel query execution – Distribute query workloads across multiple CPU cores
- Query pipelining – Process multiple query stages concurrently:
- Materialized views– Pre-compute common search operations
- Right indexing – Choose the right index types for each search dimension
- Table partitioning – Divide large tables into more manageable chunks based on logical divisions to prune the data unnecessary to search.
What about other applications?
While our focus in this post is job search platforms, the architecture discussed applies to a wide range of applications. The following table captures some examples.
| Application | Full Text Search | Vector Search | Geospatial Search | How |
| E-commerce Product Discovery | Product names, descriptions, and specifications | “Similar products” recommendations based on product embeddings | Local availability and delivery time estimation | Helps shoppers find products matching their specific requirements while also discovering related items they might be interested in, filtered by what’s available in their region. |
| Real estate platforms | Property features, amenities, and descriptions | Find properties with similar overall characteristics | Neighborhood analysis and proximity to points of interest | Helps homebuyers find properties meeting their explicit criteria while also discovering neighborhoods they hadn’t considered but match their lifestyle preferences.
Content recommendation systems |
| Content recommendation systems | Topic-specific articles or videos | Thematically similar content based on embeddings | Locally relevant news and events | Enables both precise content discovery and serendipitous recommendations contextually relevant to the user’s location and interests. |
| Travel and hospitality | Accommodation amenities and features | “Places similar to this one” recommendations | Proximity to attractions, transportation, and activities | Helps travelers find accommodations that meet their specific requirements while also discovering options in areas they might not have initially considered. |
| Healthcare provider matching | Medical specialties and treatments | Providers with similar practice patterns and patient reviews | Proximity and accessibility | Helps patients find providers who match their specific medical needs while considering factors like practice style and convenient location. |
Conclusion
PostgreSQL’s combination of full-text search, vector similarity search, and geospatial capabilities makes it a versatile platform for building sophisticated search applications. By integrating these search techniques within a single database system, PostgreSQL enables developers to implement complex, multi-dimensional search experiences without managing multiple specialized systems.
For job search platforms, this integrated approach allows matching candidates to jobs based on explicit skills and requirements (full-text search), conceptually related experience and qualifications (vector search), and practical location considerations (geospatial search). The ability to combine these dimensions can potentially deliver more relevant matches than any single search technique could provide alone.
Try out these search techniques for your own use case and share your feedback and questions in the comments.