AWS Database Blog
Assess and convert Teradata database objects to Amazon Redshift using the AWS Schema Conversion Tool CLI
AWS Schema Conversion Tool (AWS SCT) makes self-managed data warehouse migrations predictable by assessing and converting the source database schema and code objects to a format compatible with Amazon Redshift. AWS SCT includes graphical user interface (GUI) and command line interface (CLI) modes. You can use the AWS SCT CLI to automate database assessment and conversion.
By using virtual targets in the AWS Schema Conversion Tool, you can convert your source database schema to a different target database service without needing to connect to an actual target database instance.
You can save the converted code to a SQL file when working with a virtual target or apply it directly to the target database. For non-virtual targets, saving to a SQL file is also available as an option.
In this post, we describe how to perform a database assessment and conversion from Teradata to Amazon Redshift. To accomplish this, we use the AWS SCT and its CLI, because it provides support for Teradata as a source database, complementing the wide range of assessments handled by AWS Database Migration Service (AWS DMS) Schema Conversion (DMS SC).
Prerequisites
You should have the following prerequisites:
- The AWS SCT installed on your local server or Amazon Elastic Compute Cloud (Amazon EC2) instance. For instructions, see Installing and Configuring AWS Schema Conversion Tool. The installation contains everything you need to get started with the AWS SCT CLI, including the required version of Java.
- You can download the AWS SCT CLI separately from AWS SCT. See AWS Schema Conversion Tool CLI for instructions on downloading the JAR file. It requires Java to run. To download Amazon Corretto version 17, see Downloads for Amazon Corretto 17.
Solution overview
In the following sections, we go through the steps to assess and convert database objects from Teradata to Amazon Redshift with AWS SCT using the AWS SCT CLI. The AWS SCT CLI is available in interactive and script mode. In interactive mode, you enter each command into the console one at the time. You can also create an AWS SCT CLI scenario to include a set of commands and run it in a batch mode.The high-level steps are as follows:
- Generate the AWS SCT CLI scenario template.
- Prepare the AWS SCT CLI scenario (SCTS):
- Create an AWS SCT project.
- Add and connect to the source and target connections.
- Map the source and target schemas.
- Generate and view assessment reports.
- Convert Teradata objects and save generated target code.
- Apply the converted schema object code to the target.
- Save the AWS SCT project.
- Run the AWS SCT CLI scenario.
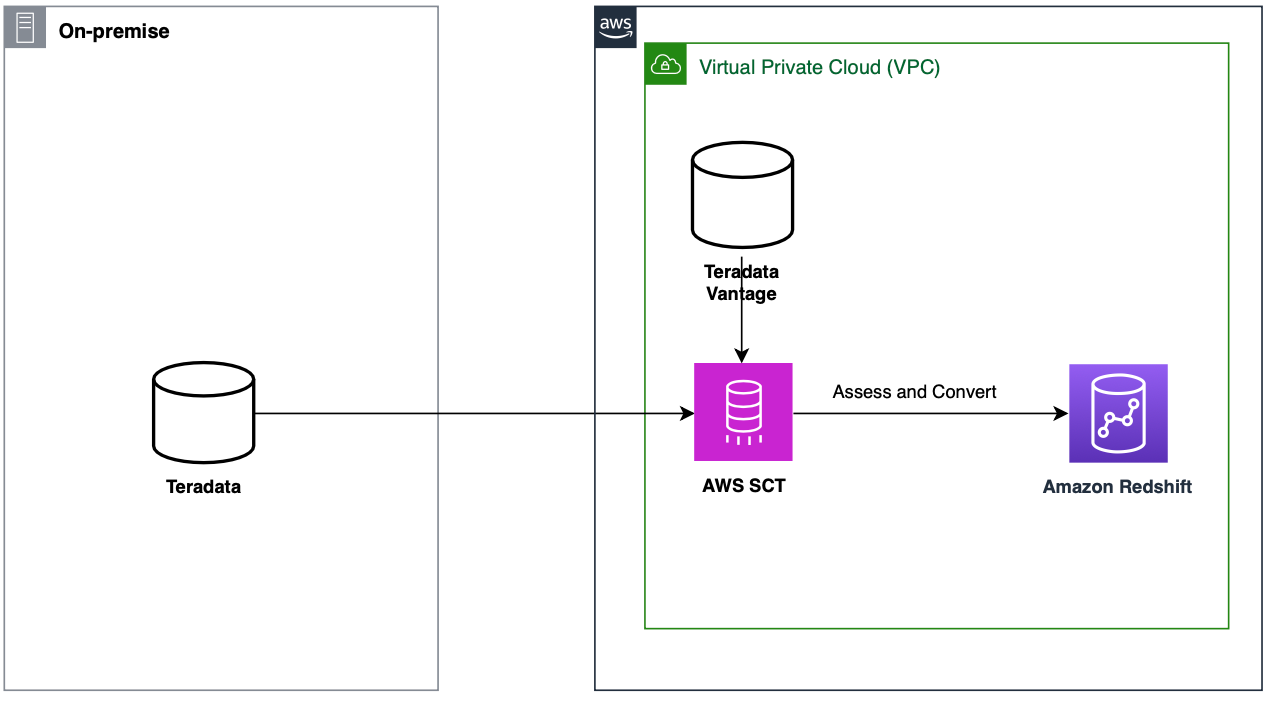
The following architecture diagram shows how you can use AWS SCT to assess and convert database objects from Teradata to Amazon Redshift.
Generate the AWS SCT CLI scenario template
You can use the GetCliScenario command to generate an AWS SCT CLI scenario (SCTS) template for common AWS SCT use cases:
In this command, you must specify the type of the AWS SCT CLI scenario template you want to generate and the directory in which the template will be saved. The most suitable CLI scenario template names for the Teradata to Amazon Redshift conversion task are ConversionApply and ReportCreation. For the full list of templates, see Getting AWS SCT CLI scenarios.
Using object paths in the AWS SCT metadata tree
When working with AWS SCT CLI, object paths provide an explicit way to reference objects in AWS SCT metadata tree. Think of them as addresses that tell AWS SCT exactly which metadata tree nodes (representing database objects) you want to work with. Whether you’re targeting a specific table, function, or an entire schema, object paths provide the means to scope them.
In this post, we’re using object tree paths, which are the more explicit and structured way to reference objects. Tree paths follow a specific pattern that includes both the object category and object name at each level, connected by dots. For more detailed information about object paths, including the alternative name path syntax and advanced usage patterns, see the AWS SCT CLI Reference Guide.
Prepare the AWS SCT CLI scenario
AWS SCT runs a set of operations (commands) to assess or convert your source database schema. It’s recommended to use an AWS SCT CLI scenario (SCTS) script to perform this.
To prepare the mentioned SCT CLI scenario, complete the following steps:
- Include the following commands in the AWS SCT CLI scenario to create an AWS SCT project and configure Teradata and Amazon Redshift JDBC drivers:
Because the
save: 'true'flag is specified in theSetGlobalSettingscommand, the paths to the JDBC drivers are stored and reused in subsequent AWS SCT projects. - Include the following commands in the AWS SCT CLI scenario to add your Teradata source and Amazon Redshift target database connections:
The AWS SCT CLI loads objects in the same manner as the AWS SCT GUI.
- Add a server mapping for your source and target database. In this case, because the mapping is performed from the entire source server to the entire target server, schemas from the source server will be mapped to their corresponding target server schemas:
To specify mapping at the database schema level, provide the object tree path to the corresponding schema.
- To generate an assessment report, use the
CreateReportcommand for the specified object scope. This command analyzes the database objects and generates a report within the current project, which you can then save in a convenient format (such as PDF or CSV) using the appropriate commands.
For example, to generate an assessment report for a specific Teradata schema (that is, objects within that schema), use the following sequence of commands: - Objects for conversion can be flexibly selected using the
CreateFiltercommand which created a filter that can be applied to the source database metadata tree for scoping purposes.
To convert tables and views in the selected schema (TD_DWH), along with four explicitly named functions and procedures matching a specific name pattern within the same schema, include the following commands in the AWS SCT CLI scenario:AWS SCT doesn’t apply the converted code to the target database directly. You can choose to apply the converted code through the project or save it to a SQL script.
Applying converted objects to a target Amazon Redshift database requires a valid AWS profile configured in AWS SCT. This is necessary to install the extension pack, which provides support for certain source database features that are not available in the target database.
Extension pack files are stored in an Amazon Simple Storage Service (Amazon S3) bucket, so make sure that the profile specifies the Amazon S3 bucket name. Use the
CreateAWSProfilecommand to create a new profile, and theSetAWSProfilecommand to make it active. Use theModifyAWSProfilecommand to modify an existing profile. - Use the following commands to apply the converted schema object code to the target:
Set the
useSourceSideparameter to true to apply converted objects to the target database using their original source names instead of the converted target names.It is used in combination with a source filter (
origin: 'source') or with object paths that point to nodes in the source metadata tree of AWS SCT.This is useful when you don’t know the names or the number of target objects created during conversion (because a single source object can be converted into multiple target objects). By using the
useSourceSideparameter and source filter, you let AWS SCT automatically identify and apply or save corresponding target objects. - Because AWS SCT doesn’t automatically save changes in the project, use the
SaveProjectcommand to save the project at different stages:
When you combine the preceding steps into the AWS SCT CLI scenario, the script performs the following actions:
1. Creates an AWS SCT project.
2. Connects to your source and target databases.
3. Generates an assessment report.
4. Converts the objects.
5. Applies the converted objects.
6. Outputs the converted code as SQL.
Run the AWS SCT CLI scenario
Now you can use the AWS SCT CLI scenario you created for the source database to run AWS SCT using the command line. The following examples show the commands for Windows and Linux:
Windows:
Linux:
Download the complete AWS SCT CLI scenario
To help you get started, we’ve prepared an AWS SCT CLI scenario file containing the commands described in this post: teradata_to_redshift.scts. By using this script, you can consolidate the commands into a single file and implement the migration steps with minimal setup time. You need only replace the placeholders inside it with your specific values. By using this scenario, you can immediately begin working according to the instructions provided in this post without having to manually enter each command. We hope this helps streamline your database migration process and accelerates your journey to the cloud.
Conclusion
With AWS Schema Conversion Tool, you can plan, assess, and convert your Teradata objects to Amazon Redshift. In this post, we demonstrated how to generate an AWS SCT CLI scenario template and prepare an SCT scenario (SCTS) to assess and convert Teradata objects to Amazon Redshift using the command-line interface in batch mode.
To learn more, see the AWS SCT CLI Reference Guide.