Containers
Under the hood: Amazon EKS ultra scale clusters
This post was co-authored by Shyam Jeedigunta, Principal Engineer, Amazon EKS; Apoorva Kulkarni, Sr. Specialist Solutions Architect, Containers and Raghav Tripathi, Sr. Software Dev Manager, Amazon EKS.
Today, Amazon Elastic Kubernetes Service (Amazon EKS) announced support for clusters with up to 100,000 nodes. With Amazon EC2’s new generation accelerated computing instance types, this translates to 1.6 million AWS Trainium chips or 800,000 NVIDIA GPUs in a single Kubernetes cluster. This unlocks ultra scale artificial intelligence (AI) and machine leaning (ML) workloads such as state-of-the-art model training, fine-tuning and agentic inference. Besides customers directly consuming Amazon EKS today, these improvements also extend to other AI/ML services like Amazon SageMaker HyperPod with EKS that leverage EKS as their compute layer, advancing AWS’s overall ultra scale computing capabilities.
Our customers have made it clear that containerization of training jobs and operators such as Kubeflow, the ability to streamline resource provisioning and lifecycle through projects like Karpenter, support for pluggable scheduling strategies, and access to a vast ecosystem of cloud-native tools is critical for their success in the AI/ML domain. Kubernetes has emerged as a key enabler here due to its powerful and extensible API model along with robust container orchestration capabilities, allowing accelerated workloads to scale quickly and run reliably. Through multiple technical innovations, architectural improvements and open-source collaboration, Amazon EKS has built the next generation of its cluster control plane and data plane for ultra scale, with full Kubernetes conformance.
At AWS, we recommend customers running general-purpose applications with low coupling and horizontal scalability to follow a cell-based architecture as the strategy to sustain growth. However, developing cutting edge AI/ML models needs thousands of accelerators working together as a single coordinated system with low-latency, high-bandwidth communication. Running them within a single cluster offers certain key benefits. First, it lowers compute costs by driving up utilization through a shared capacity pool for running heterogeneous jobs ranging from large pre-training to fine-tuning experiments and batch inferencing. Partitioning those jobs into separate clusters can lower utilization due to capacity fragmentation or remapping delays. Second, splitting a massive job across clusters complicates centralized operations such as scheduling, discovery and repair. Running in a single cluster instead can improve its overall reliability and performance by eliminating cross-cluster coordination overhead. Third, ML frameworks don’t always work well in a split-cluster mode due to assumptions baked in about running with a global cluster view. While they evolve for a multi-cluster model over time, we believe in empowering customers to innovate today.
Technical Deep Dive
Kubernetes’ core cluster architecture is shown here. Amazon EKS builds on top of that with specific infrastructure and software configurations, a cluster management plane and components/services that provide deeper AWS integrations to customers. The Kubernetes data store (etcd) and API server form the heart of the cluster and are critical enablers for ultra scale. Followed by various controllers that perform centralized cluster operations or operations local to a node. Add-ons provide extended functionality, such as service discovery, telemetry and credential vending for applications running in the cluster. Accelerated workloads demand an extensive set of add-ons, such as device plugins and daemons for node management and monitoring. Outside the cluster realm, various services in the Amazon EKS management plane continually work to secure, scale and update all our clusters. As part of this initiative, we engineered all these components and services to operate seamlessly at the 100,000 node scale, and continuously validate that through continuous integration tests. Let’s dig in.
Next generation data store
etcd is a strongly-consistent, distributed, key-value database that provides the storage backend for Kubernetes API. Underneath, it uses the raft consensus algorithm to maintain a consistently-replicated transaction log across all its cluster members. Each member maintains a copy of the log, and a given transaction is only applied to its local database state after a majority (or quorum) of the cluster members have persisted it in their log. Managing and scaling etcd is substantial heaving-lifting that we already abstract away from our customers. We made multiple innovations in our etcd architecture to deliver the next generation of cluster performance to customers, all while continuing to be fully Kubernetes conformant. We will keep investing in the success of the open-source etcd project and believe that only a solid etcd core can pave the way for such advancements.
Consensus offloaded: Through a foundational change, Amazon EKS has offloaded etcd’s consensus backend from a raft-based implementation to journal, an internal component we’ve been building at AWS for more than a decade. It serves ultra-fast, ordered data replication with multi-Availability Zone (AZ) durability and high availability. Offloading consensus to journal enabled us to freely scale etcd replicas without being bound by a quorum requirement and eliminated the need for peer-to-peer communication. Besides various resiliency improvements, this new model presents our customers with superior and predictable read/write Kubernetes API performance through the journal’s robust I/O-optimized data plane.
In-memory database: Durability of etcd is fundamentally governed by the underlying transaction log’s durability, as the log allows for the database to recover from historical snapshots. As journal takes care of the log durability, we enabled another key architectural advancement. We’ve moved BoltDB, the backend persisting etcd’s multi-version concurrency control (MVCC) layer, from network-attached Amazon Elastic Block Store volumes to fully in-memory storage with tmpfs. This provides order-of-magnitude performance wins in the form of higher read/write throughput, predictable latencies and faster maintenance operations. Furthermore, we doubled our maximum supported database size to 20 GB, while keeping our mean-time-to-recovery (MTTR) during failures low.
Partitioned key-space: Kubernetes natively supports partitioning etcd clusters by resource type and doesn’t require serializable transactions across keys of different types. Although etcd itself doesn’t natively support key-space partitioning today for simplicity, ultra scale clusters benefit significantly by splitting hot resource types into separate etcd clusters. With an optimal partitioning scheme, Amazon EKS achieved up to five times the write throughput while continuing to use etcd’s rich API semantics that evolved for Kubernetes over the years. Our new architecture allows for dynamic repartitioning, but we found that well-assigned static partitions are sufficient to support the 100K node scale. These improvements are only available to new EKS clusters created with ultra scale capabilities enabled.
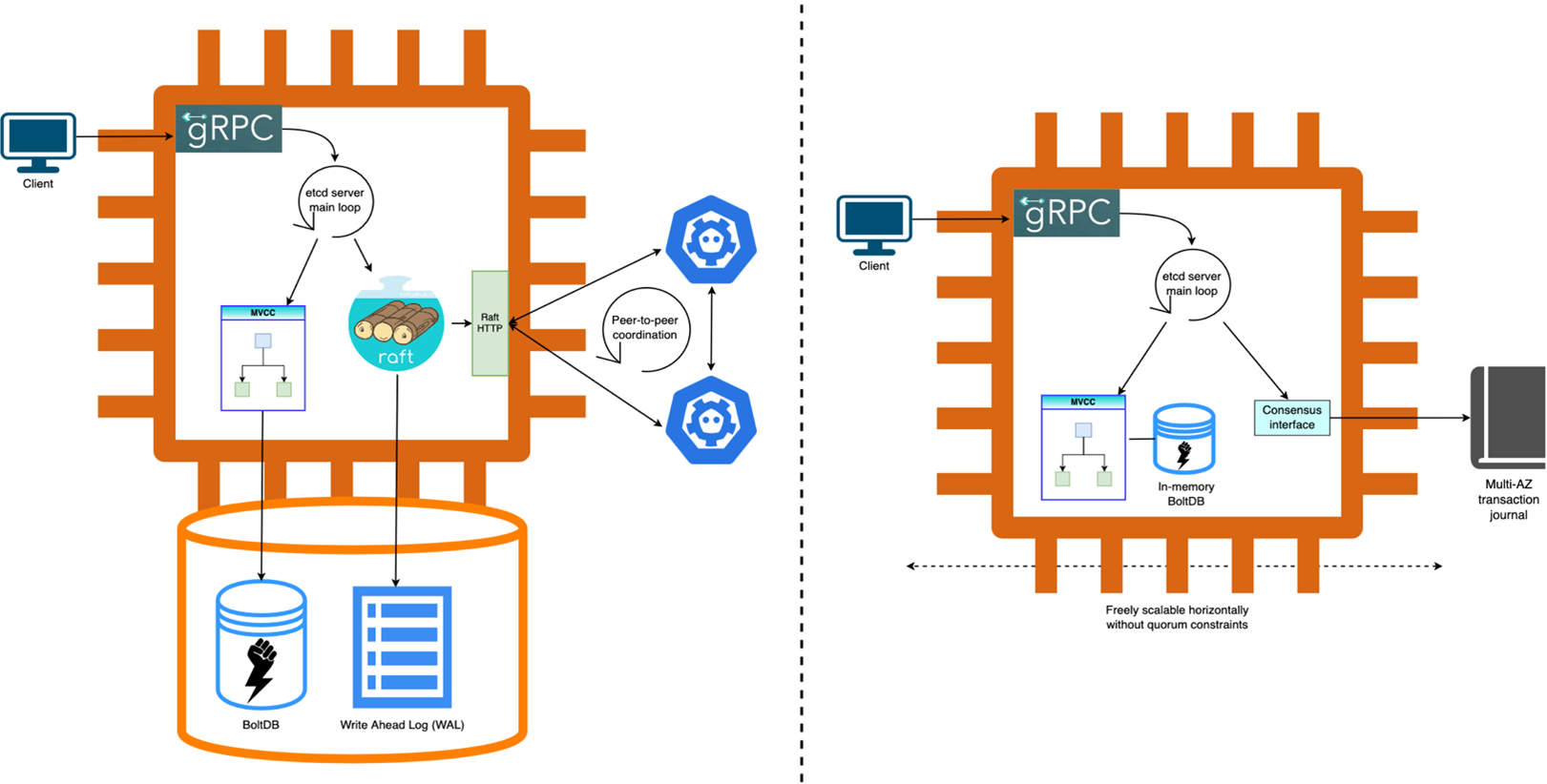
Figure 1 – Amazon EKS etcd server before and after our re-architecture
Extreme throughput API servers
Kubernetes API servers in Amazon EKS today can scale freely, vertically and horizontally, which is a strategy we already use to increase read throughput and watch fan-out in response to various usage signals. On the other hand, write throughput is primarily governed by etcd and we have already covered improvements there. Below, we discuss more enhancements that were key to enabling ultra scale, starting at Amazon EKS v1.33.
API server and webhook tuning: Traffic patterns at scale, especially with accelerated workloads, make it quite amenable to tune API servers and critical webhooks in specific ways that trade-off resource efficiency for scalability. We achieved optimal performance by carefully tuning various configurations such as request timeouts, retry strategies, work parallelism, throttling rules, http connection lifetime, garbage collection, and etcd client settings. Tuning this way isn’t beneficial for most workloads, but works great for improved throughput and cluster reliability at tens thousands of nodes.
Consistent reads from cache: Kubernetes v1.31 introduced strongly-consistent reads from cache that allowed offloading a big portion of read traffic from etcd to the API server. Previously, reads that needed label or field-based filtering (such as Kubelet listing pods assigned to a node) would make the API server list the entire collection from etcd first, then perform filtering in memory to send the client response. The new mechanism tracks cache freshness with etcd and, when current, serves reads directly from the API server cache. Cutting down on server-side CPU usage by 30% and speeding up list requests by three times revealed substantial read throughput wins. As part of our ultra scale testing, we found that clients making paginated reads were unnecessarily falling back to etcd in v1.33 and helped fix it in v1.33.3, thereby restoring cluster stability during thundering herd scenarios.
Reading large collections efficiently: Large clusters come with large collections of objects. Listing these efficiently is a prerequisite for Kubernetes controllers that need to fetch entire collections before kicking off their reconciliation loops. For example, Anthropic needed this for their job scheduler. The streaming list response feature enabled in Kubernetes v1.33 helped here by improving memory efficiency and thereby the list request concurrency of the API server (approximately eight times) by incrementally encoding/transmitting items in the collection rather than buffering the entire collection at once.
Binary encoding for custom resources: Kubernetes custom resources (CR) are extensively used by ML frameworks such as Kubeflow to model training jobs, pipelines, and inference services. These resources add significant server-side overhead when storing, processing and transmitting them to clients at scale due to inefficient JSON encoding. Concise Binary Object Representation (CBOR) encoding, an alpha feature introduced in Kubernetes v1.32 provides a cheaper alternative. It reduces the payload size and serialization overhead by up to 25% using binary encoding and makes CRs faster/cheaper to process. This also benefits high-throughput high-cardinality CR clients, such as node daemons commonly used by AI/ML customers. Note that this feature is not currently enabled by default in upstream and we’re benchmarking performance to help graduate it to beta.
Lightning fast cluster controllers
Controllers operating at the cluster scope typically need to maintain a global view of resources to perform centralized cluster operations (such as pod scheduling). Although they are replicated for high availability, often only a single “leader” replica is doing the real work to avoid conflicts. Larger clusters mean bigger state to hold in memory, increased TPS on dependencies and the need to make high volume decisions. Most controllers can process incoming work in parallel through multiple worker threads and lock-safe work-queues. Given enough resources, the throughput achieved by a controller is often limited by worker parallelism or dependency rate limits. By improving on those, we improved the throughput for many Kubernetes and EKS controllers. However, we needed to improve controller architectures beyond this to achieve ultra scale.
Minimizing lock contention: Kubernetes controllers heavily use the Informer pattern — a mechanism for efficiently tracking and reacting to changes in Kubernetes resources by maintaining a local, in-memory cache of the resources and notifying registered handlers when changes occur. The changes themselves are delivered through a long-running watch connection with the Kubernetes API server. We observed high read-write lock contention on the shared informer cache when the controller’s worker threads perform large lists, delaying incoming event processing and causing various second order effects such as piled-up queues, high memory usage and congestive collapse eventually. We drove a broader investigation of this issue upstream and made fixes to several key controllers by adding indexes that optimized heavy list requests. We further improved the event handling throughput during high churn scenarios by up to ten times through batch processing. We continue contributing these improvements upstream.
Scheduling optimizations: Customers can bring their own schedulers today and use them either exclusively or in conjunction with the default Kubernetes scheduler (KS). Certain AI/ML workloads benefit with job schedulers that perform gang scheduling and pre-emption efficiently. However, KS remains the most general-purpose scheduler commonly used for Kubernetes DaemonSets, Deployments, Jobs and StatefulSets. Unlike most controllers, KS processes pods serially to satisfy correctness properties, making its throughput inherently latency-bound. On large clusters this latency worsens because there are more nodes to evaluate. However, we achieved consistently a high throughput of 500 pods/second even at the 100K node scale by carefully tailoring scheduler plugins based on the workload and optimizing node filtering/scoring parameters.
Karpenter enhancements
Karpenter is a flexible, high-performance node lifecycle management project for Kubernetes, led by AWS. It helps customers scale their clusters efficiently and optimize costs by automatically provisioning right-sized nodes based on pods’ scheduling needs and consolidating underused nodes. Customers often run general-purpose and accelerated workloads in the same cluster and want a unified way to manage their compute with Karpenter. However, certain limitations prevented it from being an ideal fit for ultra scale AI/ML workloads. We evolved Karpenter to solve them.
Guaranteed capacity for ultra scale
ML training jobs often come in batches with specific patterns. Karpenter’s reactive provisioning model doesn’t anticipate this, potentially leading to provisioning delays when large jobs arrive together. To address this problem, we introduced support for static capacity. With static node pools, customers can create and maintain a minimum set of nodes in the cluster consistently, thereby guaranteeing capacity for long-lived AI/ML workloads. We also added support for Capacity Blocks for ML in the NodeClass API. Capacity Blocks are ideal for model training, fine-tuning, running experiments and preparing for inference demand surges. Karpenter prioritizes use of Capacity Blocks when provisioning static capacity before falling back to other capacity types. These changes will soon land upstream.
Auto-repair for accelerated compute: Accelerator failures are rare, but when they do occur, they can be disruptive to AI/ML workloads. Using Karpenter’s node repair feature with EKS Node Monitoring Agent (NMA) to detect health degradation, customers can automatically perform unhealthy node replacements as needed. Similarly, customers can leverage the drift feature to drive compute configuration updates such as their Amazon EKS-optimized accelerated AMIs. We parallelized various controllers in Karpenter to perform well at scale. Further, during our testing, we discovered several bottlenecks due to memory allocations and inefficiencies in calling dependency APIs. We optimized those code paths to improve resource usage, eliminate redundant API calls and batch suitable operations. All these changes helped improve node repair and drift latencies at ultra scale and are available upstream.
Scaling the cluster network
Amazon EKS supports native VPC networking for Kubernetes pods, avoiding the overhead of an overlay network. We also enable deep network integrations such as custom subnets, security groups and elastic fabric adapter (EFA) support for accelerated workloads. Customers can achieve high performance for their applications by eliminating network hops between their traffic-serving load balancers and backend pods. Following enhancements pushed our ultra scale AI/ML capabilities further.
Moving from IP assignments to warm prefixes: As cluster scale grows, you must plan for the Network Address Usage (NAU) metric. Each NAU unit contributes to a total that represents the size of a VPC and a VPC can support up to 256,000 NAUs or 512,000 NAUs when peered with another VPC. By default, each pod gets an individual IP address from the cluster VPC today. Given both an IP address and an IP prefix count as a single NAU unit regardless of the prefix size, we configured the Amazon VPC CNI with prefix mode for address management on ultra scale clusters. Further, prefix assignment was done by Karpenter directly in instance launch path with the Amazon VPC CNI discovering network metadata locally from the node after launch. These improvements allowed us to streamline the network with a single VPC for 100K nodes, while speeding up the node launch rate up to three-fold.
Maximizing network performance: When training with massive petabyte-scale datasets, network bandwidth can be a key bottleneck. Ultra scale AI/ML workloads often need to pull enormous data from Amazon S3 into the cluster. To avoid the accelerators from sitting idle when waiting for data, we need high-bandwidth data transfer between the storage layer and the node. By default, the Amazon VPC CNI selects one network card for the elastic network interface (ENI) assigned to the pod. This network card handles all incoming and outgoing traffic for the pod. With accelerated computing instance types supporting multiple network cards, we enabled plugin support to create pod ENIs on additional network cards. This enhanced the pod’s network bandwidth capacity (above 100 GB/s) and packet rate performance, thereby also driving up accelerator usage.
Rapid container image pulls
We observed that ultra scale AI/ML workloads tend to use large container images such as PyTorch training, TensorFlow notebooks, and SageMaker distribution, often exceeding 5 GB. The speed of downloading and unpacking container images is an important factor in workload readiness. We introduced Seekable OCI (SOCI) fast pull which enables concurrent download and unpacking operations. SOCI fast pull downloads large layers in chunks allowing this step to complete faster. Next, we leveraged the high Elastic Block Store (EBS) IOPS (260k) and throughput (10 GB/s) supported by both Trn2 and P5e/P6 instance types to reduce time to unpack. We introduced parallel unpacking which allows multiple layers to be decompressed and processed simultaneously rather than waiting for each layer to complete before starting the next. Our testing demonstrates up to a 2x reduction in overall image download and unpack compared to the default. Additionally, we created an Amazon S3 VPC endpoint in the worker node VPC which guarantees 100 GB/s bandwidth per availability zone. This ensured sufficient throughput while downloading the container image layers and led to significant speed up in node readiness.
Testing for scale
A key tenet of our test methodology is to work closely with customers and work backwards from their needs – to resemble real-world ultra scale AI/ML workloads and integrations that enable their success. This meant covering a spectrum of workloads ranging from a large distributed pre-training job to multiple concurrent fine-tuning or distillation jobs to serving high throughput inference. Exercising accelerated infrastructure also requires clusters to run a variety of device plugins for compute/network/storage and consume essential AWS services like Amazon ECR, Amazon FSx and Amazon S3. Additionally, AI/ML customers also commonly install node agents for health monitoring (EKS Node Monitoring Agent), telemetry (Amazon CloudWatch agent, NVIDIA DCGM server), application credentials (EKS Pod Identity Agent) and image caching. Through extensive testing we vetted all these core capabilities scaled seamlessly and worked reliably at 100K nodes.
Node lifecycle
First, we used Karpenter to launch 100K Amazon EC2 instances with a combination of node pools and instance types. This completed in 50 minutes, at a rate of 2000 ready nodes joining the cluster per minute. Then we exercised drift to update all the nodes to a new AMI, a common day-2 operation for customers. Karpenter was able to drift the entire cluster in about 4 hours while respecting the node disruption budgets. Finally, we scaled down all the nodes with Karpenter in 70 minutes. Below graphs show the timeline for provisioning, drift and termination respectively.
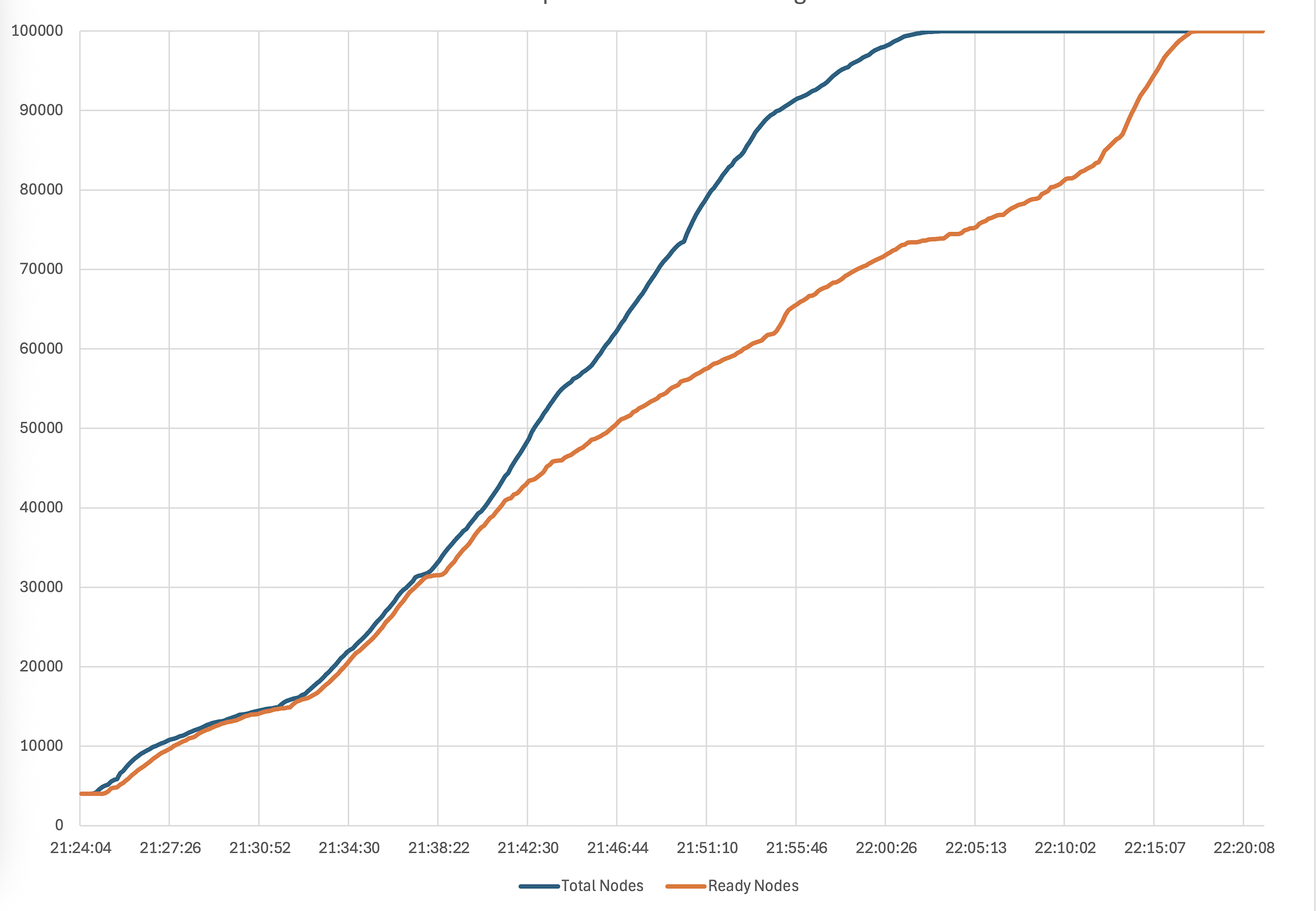
Figure 2 – Timeline for 100K node provisioning
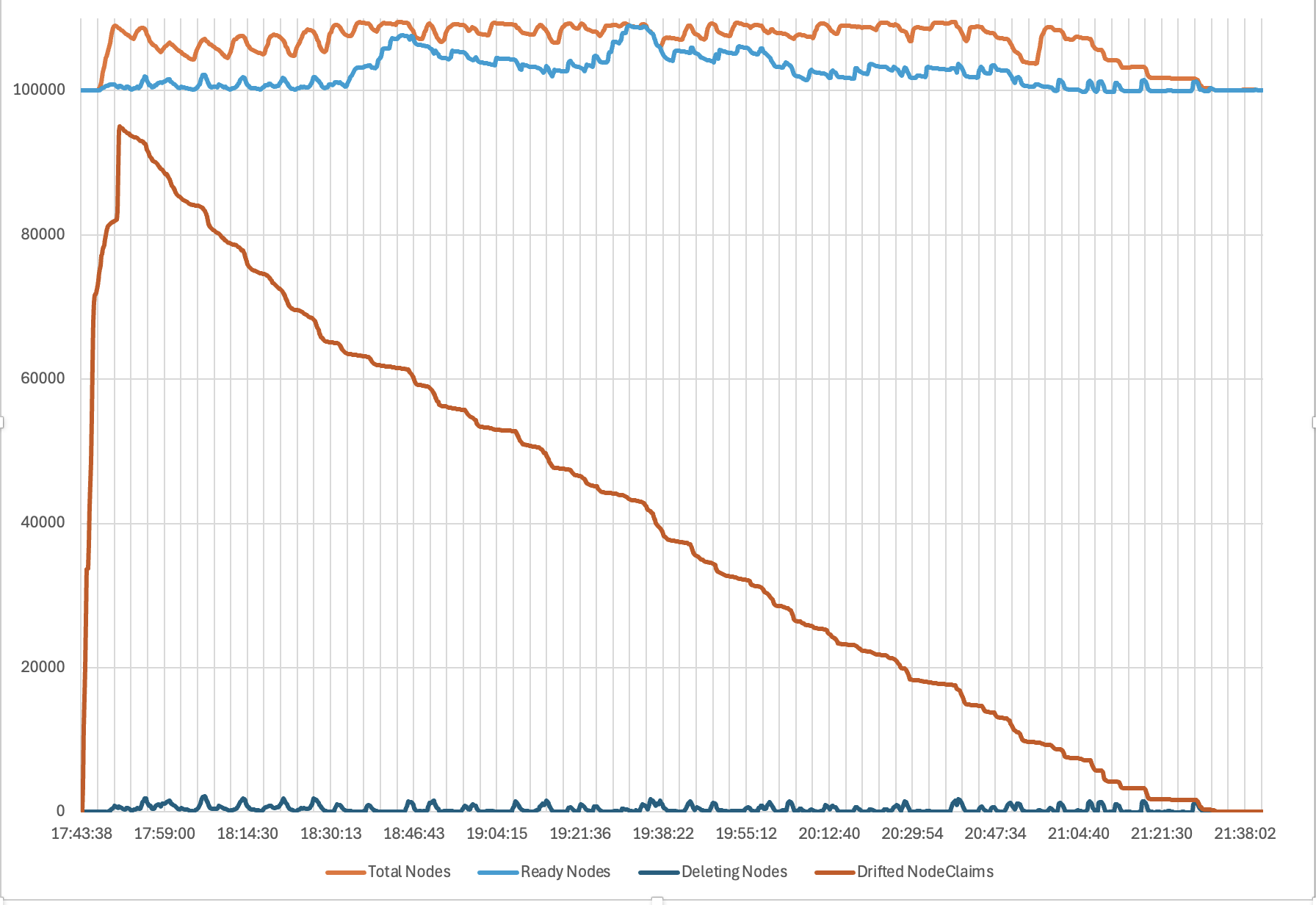
Figure 3 – Timeline of drift with Karpenter
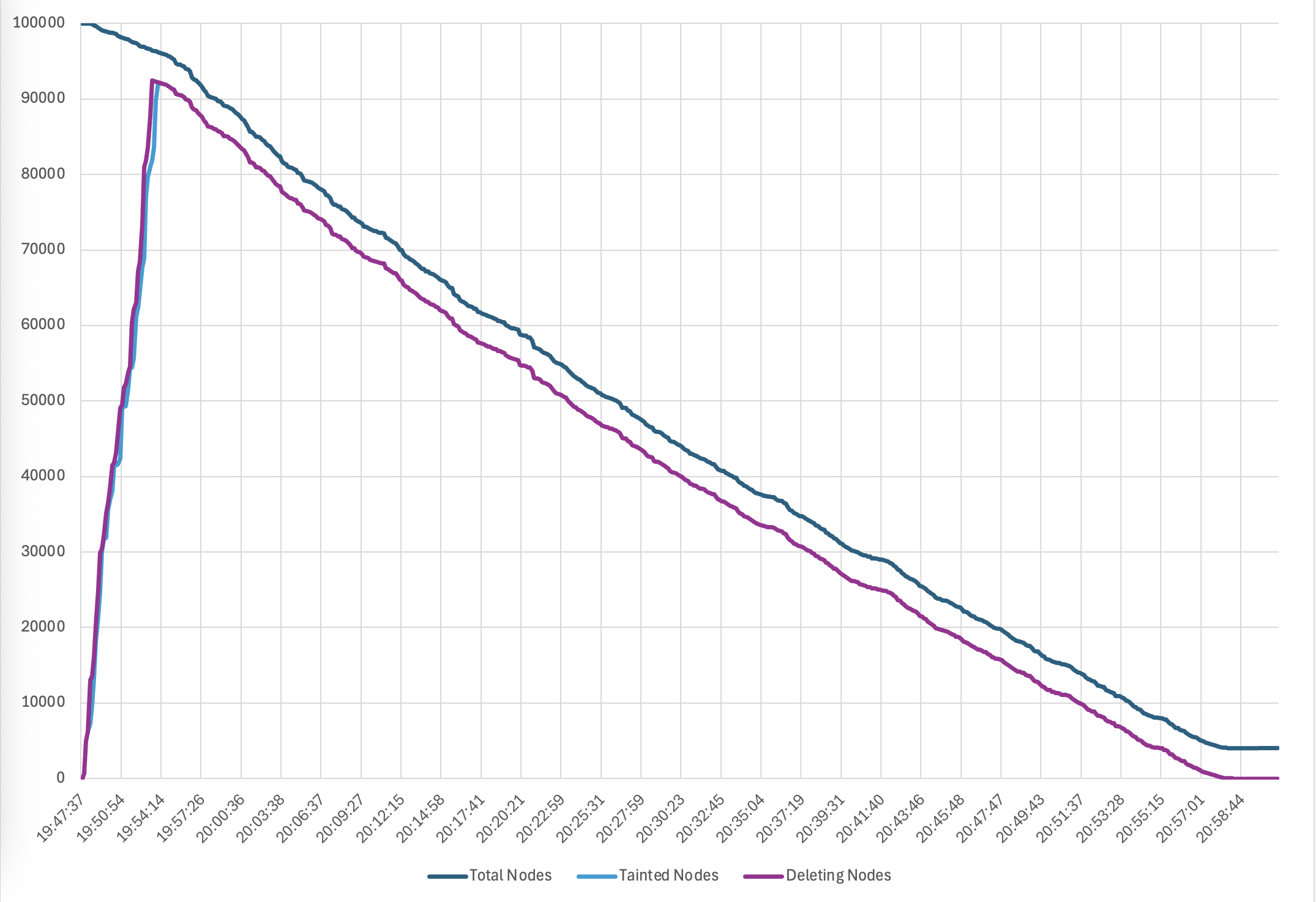
Figure 4 – Timeline for node termination
Workload testing
Our testing covered three scenarios – a massive pre-training job running on all 100K nodes, 10 parallel fine-tuning jobs each using 10K nodes, and a mixed-mode workload with 70K nodes running fine-tuning jobs and 30K nodes serving large-scale inference. We used LeaderWorkerSet to serve inference with Meta Llama-3.2-1B-Instruct using vLLM model servers pulled from Amazon ECR and the model weights loaded from Amazon FSx. Observe the cluster running with up to 100K heterogenous AI pods:
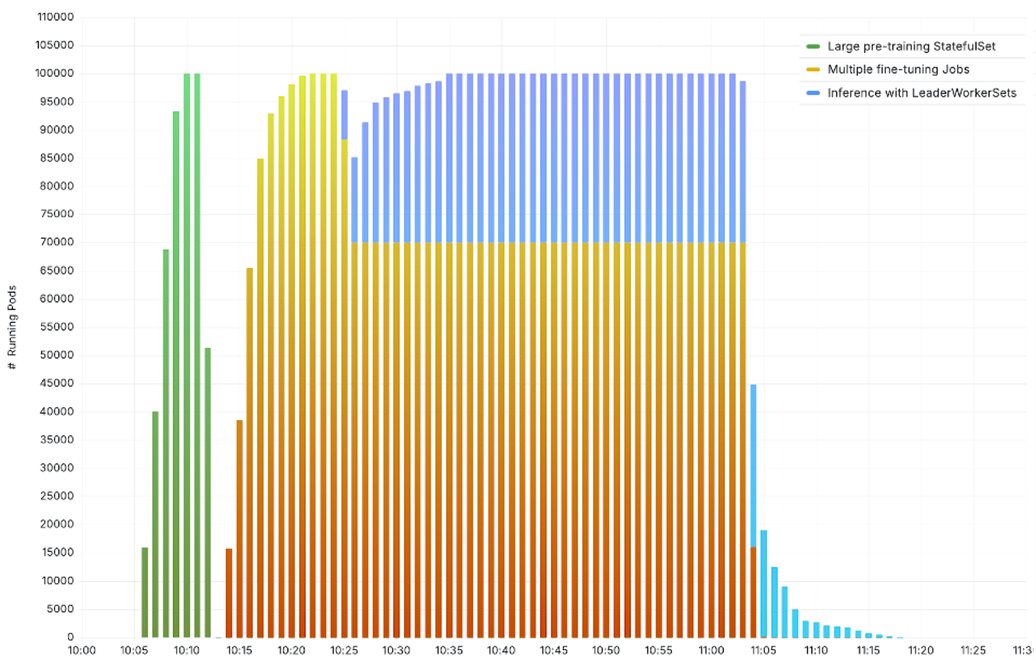
Figure 5 – AI/ML testing scenarios running on 100K nodes
As the cluster churns through these workloads, a high Kubernetes API read throughput (left) and write throughput (right) is served without failures:
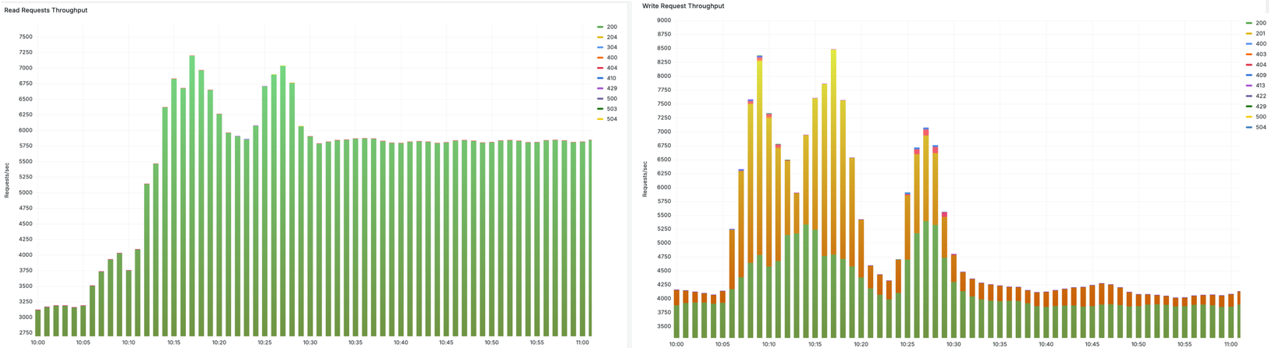
Figure 6 – High throughput read and write requests
And the p99 API latencies remain well within the Kubernetes SLO targets of 1 second for gets/writes (left) and 30 second for lists (right):
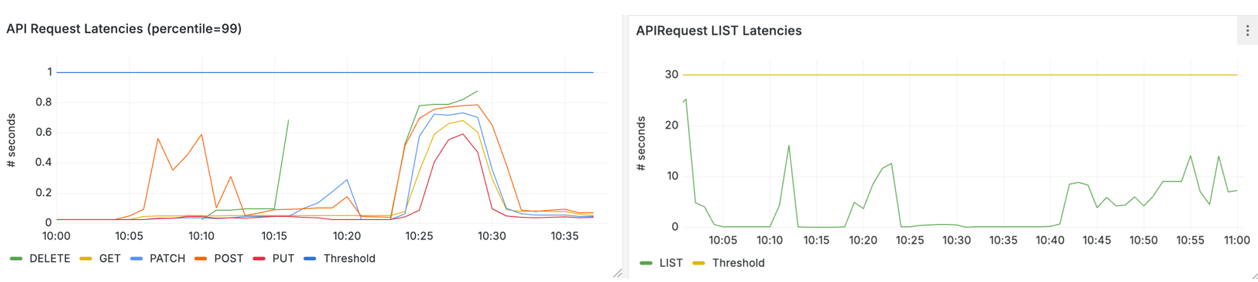
Figure 7 – Kubernetes API request latencies under SLO targets
The cluster contains more than 10 million Kubernetes objects, including 100K nodes and 900K pods (left) and the aggregate etcd database size across partitions reaching 32 GB (right):
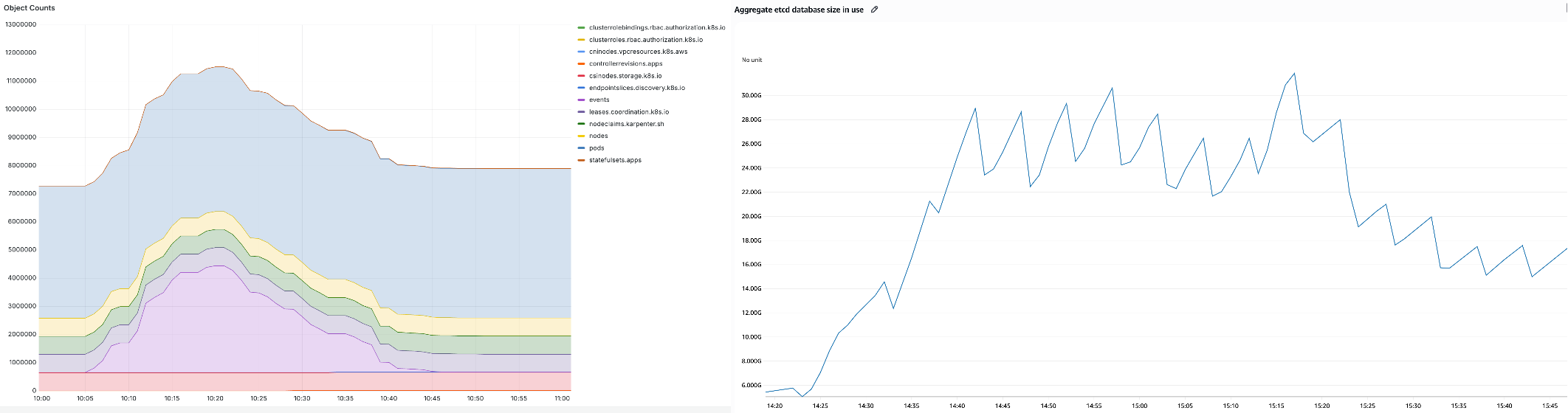
Figure 8 – 32 GB etcd database with more than 10 million objects
The Kubernetes scheduler consistently delivered throughput of up to 500 pods/second (left) and cluster controllers were able to keep up with the incoming operations at a low work-queue depth (right):
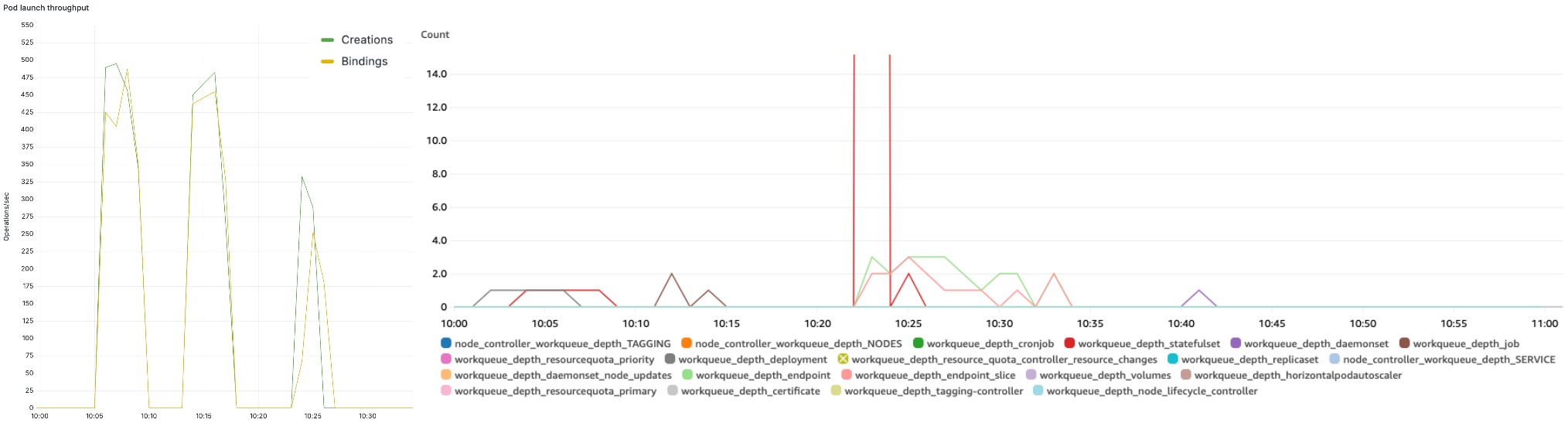
Figure 9 – Scheduler throughput of 500 pods/second and low controller work-queue depth
Cluster resiliency
To test cluster resiliency, we induced health degradations across a 1000 nodes and measured the time it took for the EKS node monitoring agent to detect and mark them as unhealthy, and for Karpenter to then perform node auto-repair by replacing them with healthy nodes. Overall, all the 1000 degraded nodes were replaced with healthy new nodes in under 5 minutes (left). We also induced cluster DNS queries at 1.5 million QPS. With the EKS CoreDNS autoscaler scaling deployment replicas to 4000, the p99 query latency stayed below 1 second (right).
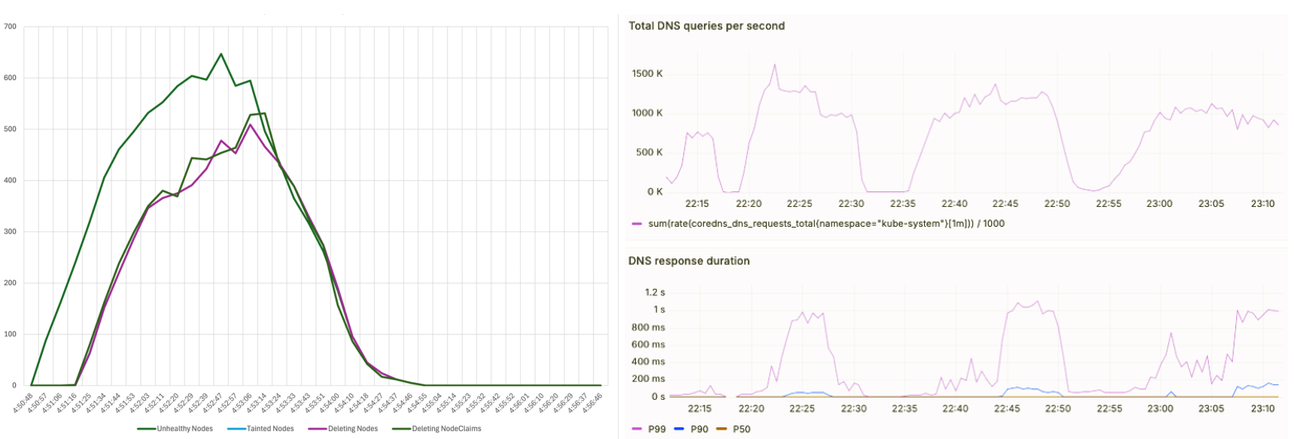
Figure 10 – Cluster resiliency across 1000 node failures and 1.5 million QPS DNS queries
Conclusion
Amazon EKS’s support for 100,000 node clusters represents a fundamental breakthrough in ultra scale AI/ML infrastructure, enabling customers to deploy up to 1.6 million AWS Trainium chips or 800,000 NVIDIA GPUs in a single coordinated system. Through a series of architectural improvements, such as offloading etcd consensus to AWS’s multi-AZ journal system, along with various optimizations, we achieved order-of-magnitude performance improvements while maintaining full Kubernetes conformance. These innovations not only empower customers like Anthropic to run cutting-edge model training and inference workloads at scale but also strengthen Amazon’s broader AI/ML services foundation, such as Amazon SageMaker HyperPod. As generative AI continues to push the envelope for computational requirements, we are ready to support the next generation of accelerated workloads with unprecedented reliability, performance, and scale.