Containers
Fully Sharded Data Parallel with Ray on Amazon ECS
Fully Sharded Distributed Data Parallel (FSDP) is a machine learning (ML) training algorithm that splits a model across GPU workers. Sharding a model’s gradients, optimizer states, and parameters makes training of large models possible because it allows them to fit in multiple GPUs that otherwise do not have enough memory to process the entire model.
This post presents an implementation of an FSDP fine-tuning job of dolly-v2-7b using Amazon Elastic Container Service (Amazon ECS). Amazon ECS abstracts away container orchestration with transparent upgrades and a streamlined architecture, enabling teams to concentrate on model training and fine-tuning.
Solution overview
This solution consists of a single ECS cluster where the Ray Cluster is going to run. A Ray cluster is a set of worker processes connected to a common Ray head process. To accomplish this, two services are deployed on the ECS cluster: Ray head and Ray worker. Both services contain a single ECS task. Amazon S3 is used for shared storage between both tasks. The following figure shows the solution overview.
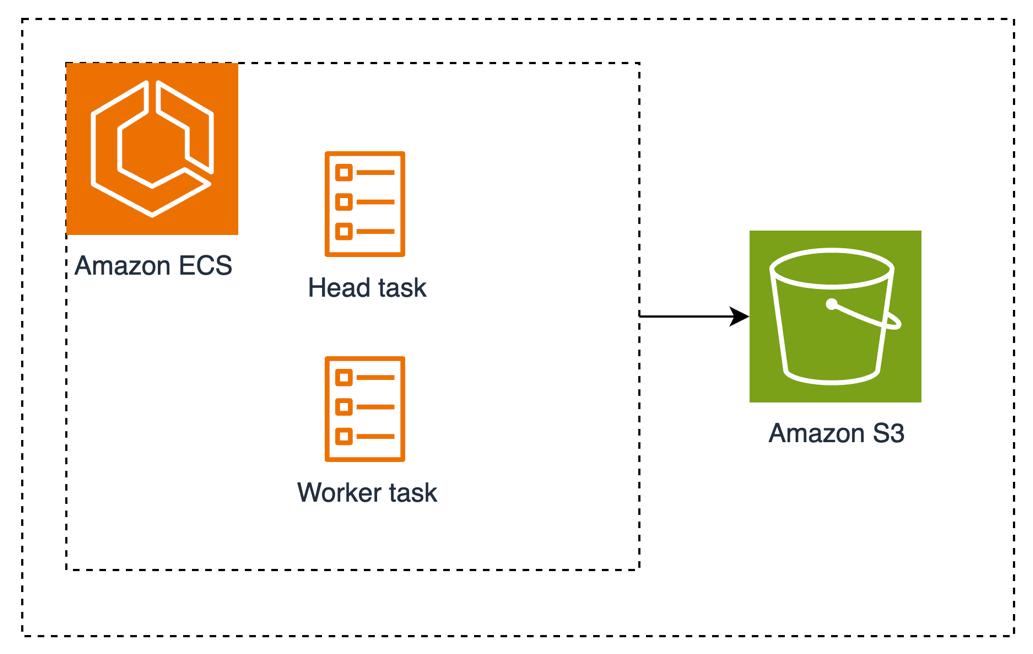
Figure 1: Amazon ECS with Head and Worker tasks connected to Amazon S3
Prerequisites
You need the following prerequisites to proceed with this post:
- An AWS account
- Terraform running version 1.8.5 or greater.
- AWS Command Line Interface (AWS CLI) with the session manager plugin
- Available Running On-Demand G and VT instances service quota equal or greater than 96 in the us-west-2 AWS Region. Two g5.12xlarge instances are created. VT instances are not used.
Walkthrough
During this walkthrough, we go over the steps to:
- Deploy the training infrastructure: Terraform is used to create the S3 bucket for shared storage and setup for the Ray Cluster to run on Amazon ECS using two services: head and worker. Each service has its own ECS Capacity Provider associated with Amazon Elastic Compute Cloud (Amazon EC2) Auto Scaling groups with g5.12xlarge instance types, each one having four NVIDIA A10 GPUs.We follow the best practices of running ML workloads in a private subnet. Internet connectivity is needed to download the model, datasets, and libraries, thus a NAT gateway and an internet gateway (IGW) are created. You use a single subnet to improve latency, resulting in all the instances launching in the same Availability Zone (AZ). This design also reduces inter-AZ data transfer charges.Furthermore, the instances are deployed with a cluster placement strategy enabling workloads to achieve a low-latency network performance. To keep costs low and because the cluster size is small, the Ray head task, which is usually dedicated to processes responsible for cluster management, is also used for training.For clarity, the container image is created and loaded when the instances start. For deployments that use large container images, it is a best practice to use a custom Amazon Machine Image (AMI) that has the container image preloaded.
- Run the training job: A fine tuning job of the databricks/dolly-v2-7b model using the tiny_shakespeare dataset is run in the Ray Cluster.The memory needed to fine-tune the databricks/dolly-v2-7b model in this setup is approximately 160 GB. Each A10 GPU has 24GB of memory, thus you use two g5.12xlarge that have four GPU each, providing a total of 192 GB of available memory (2 instances x 4 GPUs per instance x 24 GB of memory per GPU).
- Validate the distributed training with Amazon CloudWatch metrics: The CloudWatch agent is deployed on each instance to gather GPU metrics such as memory used and usage. This provides the data points to validate that all GPUs were used during training.
Deploy the infrastructure
- Clone the ecs-blueprints repository containing the Terraform plans that you use to create the training infrastructure.
- Deploy the core infrastructure plan. These files contain the Amazon Virtual Private Cloud (Amazon VPC) and service discovery components that the Ray Cluster uses.
- Deploy the FSDP distributed ML training blueprint. This Terraform plan creates the ECS cluster, ECS tasks, EC2 instances, and S3 bucket.
Note the bucket name in the output, because you use it in the next section.
Run training job
Connect to a container and run the script directly in bash. However, consider using JupyterLab with Amazon SageMaker because it provides a better user experience when running ML jobs in Python.
- Connect to the Ray head task using ECS exec. If the following commands return an error, then the task hasn’t started yet.
- Check ray status.
Example output:
If there are less than two active nodes, then the worker needs more time to startup. It can take several minutes until it joins the cluster.
- Run the FSDP script, passing the bucket name as a parameter. The bucket name is printed as an output of the
terraform applycommand executed previously. The script takes approximately one hour to complete.Example output:
Validate the distributed training with CloudWatch metrics
When the script finishes, you can check the metrics in CloudWatch to validate that multiple GPUs were used during the fine-tuning process. Navigate to the CloudWatch console, choose Dashboards in the left side menu, and choose distributed-ml-training-fsdp, as shown in the following figure. By default, the dashboard is deployed in the us-west-2 region.
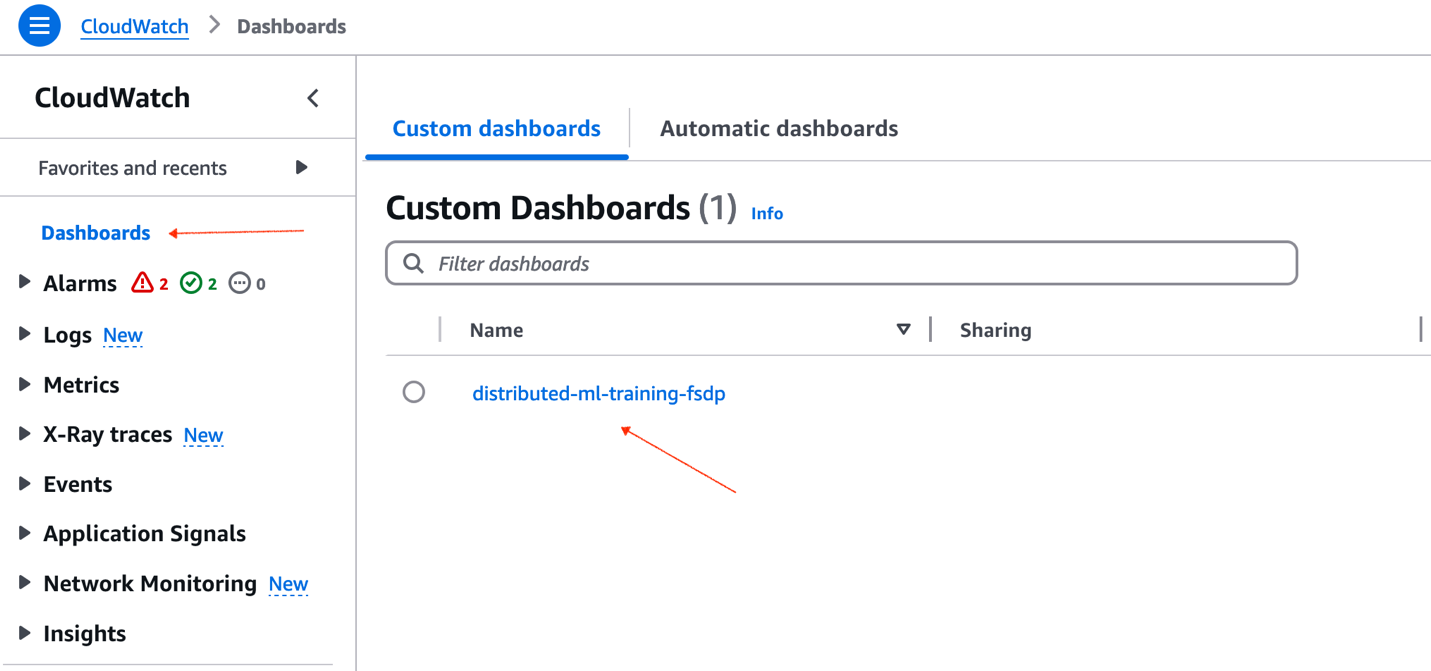
Figure 2: AWS CloudWatch custom dashboards
The dashboard includes two metrics: the GPU memory usage (GB) and the GPU usage percentage for each GPU in an EC2 instance. These metrics are useful to understand if the GPUs were used in parallel, and by how much, during training, as shown in the following figure.
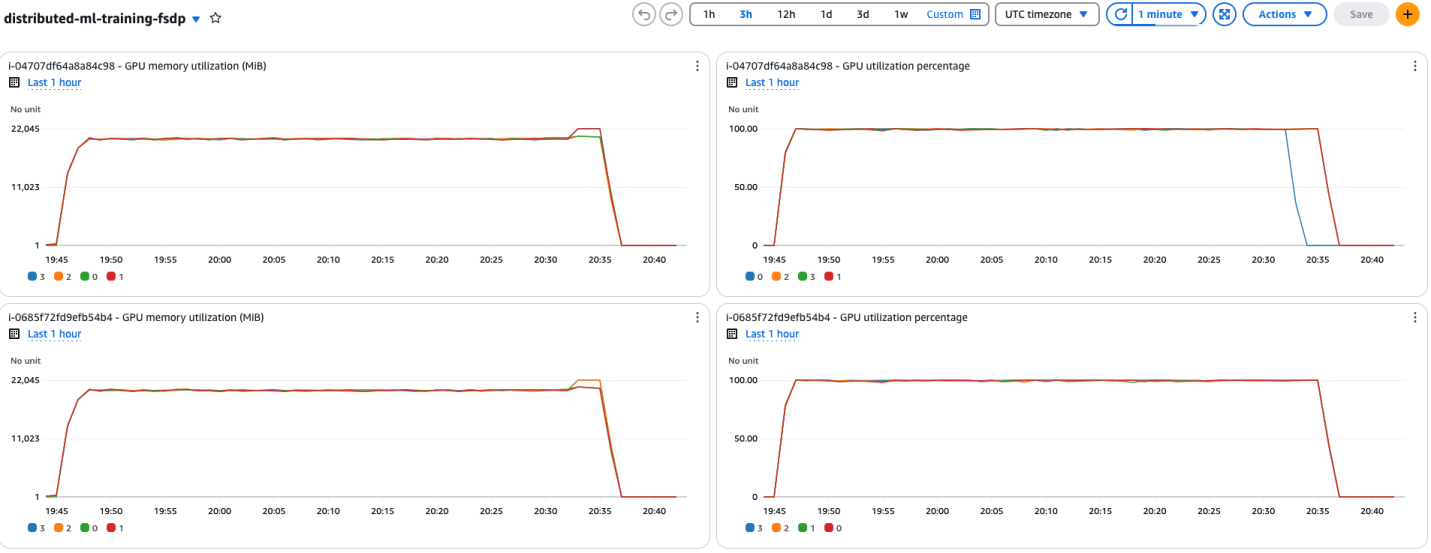
Figure 3: GPU memory and utilization metrics
As observed in the dashboard, all the GPUs were used consistently near 100%, and their memory usage was between 19 and 22 GB while the script was running, showing an efficient usage of resources across all instances. In this example, the script ran for 56 minutes and 15 seconds. At an on-demand rate of $5.672 per hour per g5.12xlarge instance, the cost for fine tuning the model is $10.70. There is no extra charge for using Amazon ECS.
Cleaning up
To avoid incurring more costs, remember to terminate the AWS resources.
- Stop the ECS tasks:
- Destroy the distributed FSDP infrastructure:
- Destroy the core infrastructure:
Conclusion
In this post, you ran a fully sharded data parallel fine-tuning script using Amazon ECS, a fully managed container orchestration service that helps you more efficiently deploy, manage, and scale containerized applications, such as artificial intelligence (AI) and ML workloads. Using model sharding techniques such as FSDP on Amazon ECS allows you to optimize your costs to run training for models with billions of parameters.
Thank you for reading this post. Before you go, we recommend to check the Amazon ECS GPU documentation to learn more about the different configurations supported and other capabilities of Amazon ECS.
About the authors

Santiago Flores Kanter is a Sr. Solutions Architect specialized in generative AI, data science and serverless at AWS. He designs and supports cloud solutions for digital native customers.

Ravi Yadav leads AppMod GTM & Architecture for North America at AWS. Prior to AWS, Ravi has experience in product management, product/corporate strategy, and engineering across companies such as Moody’s, Mesosphere, IBM, and Cerner.