Containers
Amazon EKS enables ultra scale AI/ML workloads with support for 100K nodes per cluster
We’re excited to announce that Amazon Elastic Kubernetes Service (Amazon EKS) now supports up to 100,000 worker nodes in a single cluster, enabling customers to scale up to 1.6 million AWS Trainium accelerators or 800K NVIDIA GPUs to train and run the largest AI/ML models. This capability empowers customers to pursue their most ambitious AI goals, from training trillion-parameter models to advancing artificial general intelligence (AGI). Amazon EKS provides this industry-leading scale with Kubernetes conformance, ensuring that customers can achieve these breakthroughs with their choice of open source tools and frameworks.
Kubernetes has emerged as a key enabler for customers to run large scale AI/ML workloads given its ability to efficiently scale to meet varying computational demands and its rich collection of AI/ML frameworks and tools. However, as AI/ML models continue to evolve in complexity, they require highly advanced capabilities beyond Kubernetes’ traditional boundaries. By leveraging AWS’s leading capabilities in resilience, security, and availability augmented with technical innovations and open source collaboration, Amazon EKS has made transformative enhancements to provide customers with the scale, performance, and reliability required for their most advanced and large-scale AI/ML workloads, all while preserving the familiar Kubernetes experience.
Driving highly performant ultra scale AI infrastructure with Amazon EKS
State-of-the-art (SOTA) models follow empirical scaling laws – as they increase in size with more training data, they display significantly enhanced capabilities in understanding context, reasoning, and autonomously solving complex tasks. Leading builders of these frontier models – Anthropic, with Claude, and Amazon, with Amazon Nova, have adopted Amazon EKS and its ultra scale capabilities to now scale a single cluster up to 100K nodes. With Amazon EC2’s accelerated computing instance types, this translates to harnessing the performance of up to 1.6 million Trn2 instances or 800K NVIDIA H200/Blackwell GPUs with P5e/P6 instances. This level of scale, in a single Amazon EKS cluster, provides customers with unique benefits:
Accelerating AI/ML innovation: Ability to run the largest AI/ML training jobs that demand unprecedented scale by efficiently coordinating hundreds of thousands of GPUs and AI accelerators as a single system.
Reducing costs: Consolidate diverse workloads, ranging from large scale training to fine-tuning and inference in a unified environment to reduce operational overhead and improve overall resource utilization. This helps optimize investments in expensive AI accelerators.
Providing choice and flexibility: Freedom to use preferred AI/ML frameworks, workflows and tools, both proprietary and open source, per specific needs while maintaining full compatibility with standard Kubernetes APIs.
Amazon EKS has implemented architectural changes across the stack, including enhancements to core Kubernetes components, to support AI/ML workloads at this ultra scale. With a reimagined etcd storage layer for efficient state management and an optimized control plane to handle millions of operations, Amazon EKS can now consistently deliver significantly higher performance. These enhancements also enable more efficient resource orchestration by supporting thousands of concurrent pod operations and advanced monitoring and recovery capabilities, delivering high resiliency at this ultra scale.
Empowering the next generation of AI models with Anthropic
Leading AI innovator and AWS partner, Anthropic runs their flagship Claude family of foundation models on Amazon EKS and operates some of the largest EKS clusters in production, consisting of AWS Trainium (trn2) instances and NVIDIA GPUs for AI workloads alongside AWS Graviton processors for CPU intensive data processing. This consolidated environment enables them to shift workloads between different AI/ML use cases and optimize resource allocation for their research teams.
Achieving reliable operations at very large scales with a multi-cluster architecture presented Anthropic with some unique challenges across networking, control plane operations, and resource management. By leveraging Amazon EKS’ new ultra scale capabilities, including optimizations at the networking layer and in the Kubernetes control plane, Anthropic has realized significant performance improvements, with end user latency KPIs improving from an average of 35% to consistently above 90%.
“Working with AWS, we’ve enhanced our AI infrastructure capabilities with Amazon EKS support for clusters of up to 100K nodes. This combination of EKS’ industry-leading scale and AWS accelerated compute options helps strengthen our foundation for safe and scalable AI” – Nova DasSarma, Technical Lead for Anthropic Infrastructure
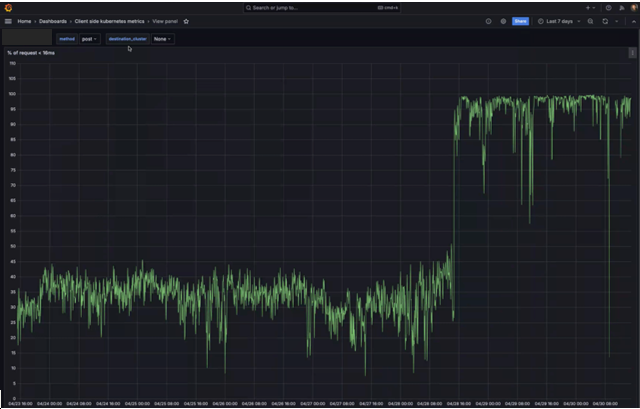
Figure 1: Percentage of write API calls completing within 15ms increased from 35% to 90% with EKS ultra scale capabilities
Propelling Artificial General Intelligence (AGI) within Amazon
Amazon’s AGI infrastructure team builds and operates the infrastructure for the Nova family of foundation models. Their use cases range from massive training jobs orchestrating thousands of nodes in parallel, to complex post-training workflows including model evaluation, distillation, and reinforcement learning. These workloads require sophisticated infrastructure orchestration at a massive scale and rapid recovery abilities to maintain high resiliency and performance.
To meet these needs, the team uses a combination of Amazon EKS and Amazon SageMaker HyperPod, which enhances their ability to run extended training jobs with automated health monitoring and failure recovery leading to reduced down times and high performance. The team leverages Amazon EKS’ ultra scale capabilities and integration with key AWS services for security and monitoring, to maintain consistent performance across their compute intensive training and inference workflows.
“Amazon EKS and SageMaker HyperPod have been instrumental in helping us push the boundaries of foundational AI model training at unprecedented scale, while delivering the high resiliency our workloads demand. This technological foundation has not only accelerated our innovation timeline but has become the cornerstone of our strategy to build the next generation of AGI capabilities that will transform how the world interacts with AI” – Rohit Prasad, SVP & Head Scientist, AGI
Building for tomorrow
AI/ML technologies are evolving at an unprecedented pace, but their effectiveness is directly impacted by the computational power they can efficiently harness. With support for ultra scale clusters, Amazon EKS has evolved many foundational capabilities across the compute stack to enable customers to continue advancing their scale of operations while driving higher performance, resilience, security, and efficiency. With these advancements, customers can utilize the power of Kubernetes and leverage AWS’ broadest and deepest set of cloud capabilities to build their most sophisticated and intelligent applications yet.
To fully explore the technical advancements enabling this scale, read the comprehensive deep dive blog that details the architectural decisions, implementation challenges, and solutions developed. Please reach out to your AWS account team to learn more about this new capability.