AWS Big Data Blog
Workload management in OpenSearch-based multi-tenant centralized logging platforms
Modern architectures use many different technologies to achieve their goals. Service-oriented architectures, cloud services, distributed tracing, and more create streams of telemetry and other signal data. Each of these data streams becomes a tenant in your logging backend. If your company runs more than one application, the IT team will frequently centralize the storage and processing of log data, making each application a tenant in the overall observability system.
When you use Amazon OpenSearch Service to store and analyze log data, whether as a developer or an IT admin, you must balance these tenants to make sure you deliver the resources to each tenant so they can ingest, store, and query their data. In this post, we present a multi-layered workload management framework with a rules-based proxy and OpenSearch workload management that can effectively address these challenges.
Example use case
In this post, we discuss GlobalLog, a fictional company supporting healthcare, finance, retail, security, and internal tenants, that built a centralized logging system with OpenSearch Service. Each tenant has unique logging patterns based on their business requirements. Financial tenants generate complex, high-volume queries, healthcare tenants focus on compliance with moderate volume logs and queries, and retail tenants experience seasonal spikes with heavy dashboard usage. Internal operation has steady, low-volume logs and infrequent, simple queries. Security monitoring has a constant, high-volume presence throughout the system.
As the GlobalLog’s tenants scaled, operational challenges emerged: high-priority tenant performance suffered during peak hours, resource-intensive queries caused node crashes, and unpredictable traffic created instability. Limited visibility into tenant resource usage complicated troubleshooting and cross-domain security investigations. The platform required robust handling of varied workload patterns and peak usage times, strong performance isolation to prevent tenant interference, and scalability to manage 30% annual data growth.
Solution overview
GlobalLog implemented a comprehensive workload management strategy to handle the diverse demands of its tenants. The solution manages the tenancy with a tiered tenant placement, a rule-based proxy layer that shapes incoming traffic based on the tenant profile and the status of the OpenSearch cluster, and an OpenSearch workload management plugin that provides granular resource governance, allocating resources such as CPU and memory proportionally to each tenant’s tier. The monitoring component provides the intelligence that the solution needs to do its assessment and make reactive and proactive scaling and performance-related decisions by adjusting the traffic governance rules and policies in a timely manner.
The following diagram illustrates the architecture.
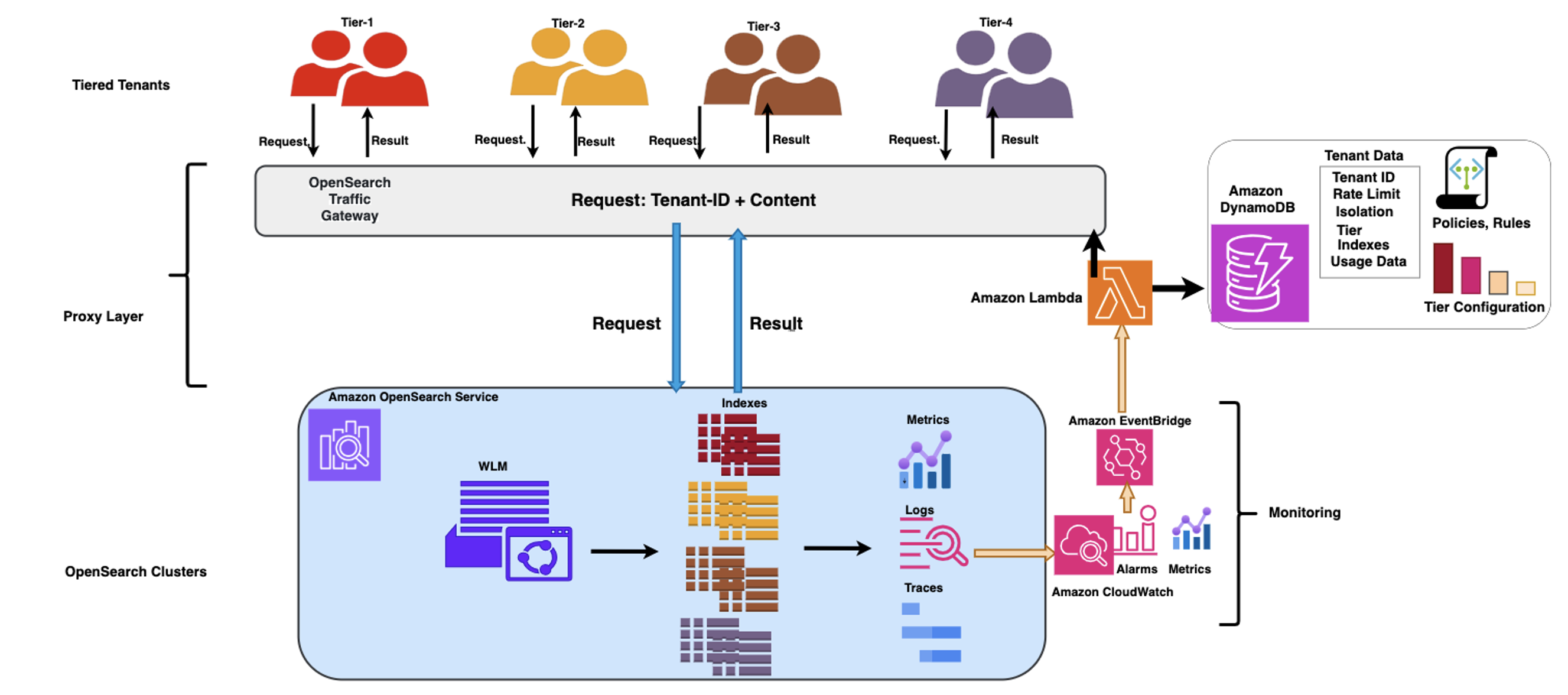
GlobalLog multi tier workload management
Tenant tiering and placement
GlobalLog categorized tenants into four tiers based on their logging requirements (volume, retention, query frequency) and allocated resources accordingly. The tiering system, enforced through the integrated proxy layer and OpenSearch workload management, prevents resource over-allocation while making sure service levels match business priorities. The specification for each tier is detailed in the following table.
| Tier | SLA | Resources | Limits | Behavior |
|
Tier 1 (Enterprise Critical) High-volume complex queries (over 100 concurrent) |
24/7 SLA with 99.99% availability |
50% CPU 50% Memory |
100 concurrent requests 20 MB request size 180-second timeout |
Priority query routing and dedicated search threads |
|
Tier 2 (Business Critical) Moderate volume compliance-oriented queries |
Business hours SLA with 99.9% availability |
30% CPU 25% memory |
50 concurrent requests 10 MB request size 120-second timeout |
Compliance-optimized search pipelines |
|
Tier 3 (Business Standard) Variable volume dashboard-heavy usage |
Standard business hours support no SLA |
10% CPU 20% Memory |
25 concurrent requests 5 MB request size 60-second timeout |
Burst capacity for seasonal peaks |
|
Tier 4 (Basic) Internal IT operations development environments |
Best-effort support no SLA |
10% CPU 5%Memory |
10 concurrent requests, 2 MB request size 30-second timeout |
Automated query optimization for efficiency Operations, seasonal businesses |
GlobalLog’s integrated architecture streamlines its cost allocation and resource distribution model. Financial industry tenants pay premium rates for their guaranteed high-performance resources, effectively subsidizing the infrastructure that supports more variable workloads. These tenants are categorized into Tier 1. Healthcare tenants benefit from isolation that enforces compliance without bearing the full cost of dedicated infrastructure. These tenants are categorized into Tier 2. Retail tenants are categorized into Tier 3 because they appreciate the elastic capacity during peak seasons without maintaining excess capacity year-round. Tier 4 includes the administrative tenants with access to enterprise-grade logging at affordable rates through efficient resource sharing.
This balanced ecosystem helps GlobalLog maintain profitability while delivering appropriate service levels to every tenant regardless of their industry-specific workload characteristics.
In the next sections, we discuss GlobalLog’s workload management system.
Proxy layer
GlobalLog’s continuous feedback loop architecture creates a dynamic ecosystem that optimizes resource allocation across diverse tenant workloads in OpenSearch Service. Rather than depending on static configurations, the architecture monitors performance metrics and tenant usage patterns to drive scaling and remediation decisions. This makes sure the system evolves as workloads change over time.
The proxy layer core component is the OpenSearch Traffic Gateway, which functions as an intermediary between clients and OpenSearch clusters. It features the following key capabilities:
- Rule-based traffic shaping through pattern matching for request paths and parameters
- Metrics for resource cost allocation
- Traffic replay
GlobalLog expanded the capabilities of their OpenSearch Traffic Gateway through a comprehensive set of enhancements focused on centralization, dynamism, and adaptability. At the core of this evolution, they used Amazon DynamoDB as the centralized repository for critical gateway data. This central database houses the complete ecosystem of rules, policies, and tenant profiles, alongside crucial operational data including metrics, usage patterns, SLA requirements, tier configurations, and real-time cluster status information.
Beyond this centralization effort, GlobalLog transformed the gateway with a dynamic mechanism capable of real-time adjustments and responsive decision-making. This architectural shift allows the gateway to react intelligently to changing conditions rather than following predetermined pathways.
Additionally, GlobalLog implemented an adaptive rule system with sophisticated contextual awareness. The system now activates specific rules based on current cluster states and tenant usage patterns, enabling precise resource allocation and protection mechanisms that respond to actual conditions rather than hypothetical scenarios. The system implements time-based rule scheduling, providing flexibility by allowing different limits and policies to automatically engage during specific periods such as maintenance windows. This provides optimal performance while accommodating necessary system operations.
The solution implements a continuous feedback loop between the monitoring system, the OpenSearch cluster, and the proxy layer, where the flow of performance metrics and tenant usage patterns drive automated, rule-based scaling and optimization decisions, helping the system evolve as workloads change over time. In this architecture, Amazon EventBridge triggers an AWS Lambda function when predefined criteria are met (for example, an anomaly is detected in OpenSearch Service), resulting in the Lambda function taking steps to remediate the issues by adjusting the traffic shaping rules and uploading them to the OpenSearch Traffic Gateway. To stabilize the feedback loop, GlobalLog took the following steps:
- Added dampening mechanisms to prevent rapid rule changes
- Implemented gradual adjustment patterns instead of binary switches
- Created circuit breakers for automatic fallback to baseline rules
OpenSearch workload management layer
GlobalLog implemented tenant-level admission control and reactive query management through OpenSearch workload management. The system uses workload management to define resource limits, based on tenant criticality, providing efficient resource allocation and preventing bottlenecks.
A key component of OpenSearch’s workload management is its workload groups. A workload group refers to a logical grouping of queries, typically used for managing resources and prioritizing workloads. GlobalLog uses workload groups to manage resource allocation based on the previously defined tenant tiers. Enterprise-critical workloads receive substantial CPU and memory guarantees, providing consistent performance for financial operations. Business Critical tenants operate with moderate resource guarantees, and Standard and Basic tiers function with more constrained resources, reflecting their lower priority status. The following example shows the workload group setup for Enterprise Critical and Business Critical tiers:
OpenSearch responds with the set resource limits and the ID for the workload group for Enterprise Critical tier tenants:
To use a workload group, use the following code:
Real-world use cases
In this section, we discuss two scenarios where GlobalLog’s workload management system helped the company overcome various challenges.
Scenario 1: Security incident response
During a critical security incident, GlobalLog faced a complex challenge of managing simultaneous log access requests from multiple business units, each with different priority levels. At the highest tier were security and financial operations (Tier 1), followed by healthcare operations (Tier 2), retail operations (Tier 3), and internal operations (Tier 4).
At the proxy layer, GlobalLog gave precedence to security and financial tenant queries while implementing specific limitations for other units. Healthcare operations were capped at 15 concurrent queries, retail operations were restricted to 5 queries per minute, and internal operations had their date ranges narrowed.
OpenSearch workload management and the proxy layer played a crucial role by maintaining the security team’s query priority while managing resource pressure, including the cancellation of complex retail queries during high CPU usage.
Scenario 2: End-of-month reporting
During month-end reporting periods, GlobalLog successfully handled intensive analytical workloads from multiple tenants. The implementation of time-based rules proved particularly effective, with prioritizing Tier 4 tenants for batch reporting during regular end-of-month off-peak business hours. The following code shows an example of GlobalLog rules in this context. The first rule allows Tier 4 tenants to run reports during off-peak business hours, and the second rule denies Tier 4 tenants’ requests during business hours:
The system dynamically adjusted resource allocation for Tier 4 tenants for the off-peak hours (6:00 PM – 8:00 AM) using the OpenSearch workload management API.
This comprehensive approach proved highly successful in managing peak reporting periods, facilitating both system stability and optimal performance across all tenant tiers.
Conclusion
The integration of proxy-layer traffic shaping with the OpenSearch workload management plugin in a continuous feedback loop architecture achieved resiliency, stable performance, and fair resource allocation while supporting diverse business priorities. The implementation discussed in this post demonstrates that large-scale, multi-tenant logging environments can effectively serve diverse business needs on shared infrastructure while maintaining performance and cost-efficiency.
Try out these workload management techniques for your own use case and share your feedback and questions in the comments.
About the Authors
 Ezat Karimi is a Senior Solutions Architect at AWS, based in Austin, TX. Ezat specializes in designing and delivering modernization solutions and strategies for database applications. Working closely with multiple AWS teams, Ezat helps customers migrate their database workloads to the AWS Cloud.
Ezat Karimi is a Senior Solutions Architect at AWS, based in Austin, TX. Ezat specializes in designing and delivering modernization solutions and strategies for database applications. Working closely with multiple AWS teams, Ezat helps customers migrate their database workloads to the AWS Cloud.
 Jon Handler is a Senior Principal Solutions Architect at AWS based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have vector, search, and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor’s of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at AWS based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have vector, search, and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor’s of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.