At AWS re:Invent 2024, we introduced a no code zero-ETL integration between Amazon DynamoDB and Amazon SageMaker Lakehouse, simplifying how organizations handle data analytics and AI workflows. This integration alleviates the traditional challenges of building and maintaining complex extract, transform, and load (ETL) pipelines for transforming NoSQL data into analytics-ready formats, which previously required significant time and resources while introducing potential system vulnerabilities. Organizations can now seamlessly combine the strength of DynamoDB in handling rapid, concurrent transactions with immediate analytical processing through the zero-ETL integration. For example, an ecommerce platform storing user session data and cart information in DynamoDB can now analyze this data in near real time without building custom pipelines. Gaming companies using DynamoDB for player data can instantly analyze user behavior as events occur, enabling real-time insights into game balance and player engagement patterns.
The zero-ETL capability uses built-in change data capture (CDC) to automatically synchronize data updates and schema changes between DynamoDB and SageMaker Lakehouse tables. By using Apache Iceberg format, the integration provides reliable performance with ACID transaction support and efficient large-scale data handling. Data scientists can train ML models on fresh data and data analysts can generate reports using current information, with typical synchronization latency in minutes rather than hours.
In this post, we share how to set up this zero-ETL integration from DynamoDB to your SageMaker Lakehouse environment.
Solution overview
We use a SageMaker Lakehouse catalog, AWS Lake Formation, Amazon Athena, AWS Glue, and Amazon SageMaker Unified Studio for this integration. The following is the reference data flow diagram for the zero-ETL integration.

The workflow consists of the following components:
- The recently launched zero-ETL integration capability within the AWS Glue console enables direct integration between DynamoDB and SageMaker Lakehouse, storing data in Iceberg format. This streamlined approach opens up new possibilities for data teams by creating a large-scale open and secure data ecosystem without traditional ETL processing overhead.
- When building a SageMaker Lakehouse architecture, you can use an Amazon Simple Storage Service (Amazon S3) based managed catalog as your zero-ETL target, providing seamless data integration without transformation overhead. This approach creates a robust foundation for your SageMaker Lakehouse implementation while maintaining the cost-effectiveness and scalability inherent to Amazon S3 storage, enabling efficient analytics and machine learning workflows.
- Organizations can use a Redshift Managed Storage (RMS) based managed catalog when they need high-performance SQL analytics and multi-table transactions. This approach uses RMS for storage while maintaining data in the Iceberg format, providing an optimal balance of performance and flexibility.
- After you establish your Lakehouse infrastructure, you can access it through diverse analytics engines, including AWS services like Athena, Amazon Redshift, AWS Glue, and Amazon EMR as independent services. For a more streamlined experience, SageMaker Unified Studio offers centralized analytics management, where you can query your data from a single unified interface.
Prerequisites
In this section, we walk through the steps to set up your solution resources and confirm your permission settings.
Create a SageMaker Unified Studio domain, project, and IAM role
Before you begin, you need an AWS Identity and Access Management (IAM) role for enabling the zero-ETL integration. In this post, we use SageMaker Unified Studio, which offers a unified data platform experience. It automatically manages required Lake Formation permissions on data and catalogs for you.
You have to first create a SageMaker Unified Studio domain, an administrative entity that controls user access, permissions, and resources for teams working within the SageMaker Unified Studio environment. Note down the SageMaker Unified Studio URL after you create the domain. You will be using this URL later to log in to the SageMaker Unified Studio portal and query our data across multiple engines.
Then, you create a SageMaker Unified Studio project, an integrated development environment (IDE) that provides a unified experience for data processing, analytics, and AI development. As part of project creation, an IAM role is automatically generated. This role will be used when you access SageMaker Unified Studio later. For more details on how to create a SageMaker Unified Studio project and domain, refer to An integrated experience for all your data and AI with Amazon SageMaker Unified Studio.
Prepare a sample dataset within DynamoDB
To implement this solution, you need a DynamoDB table that can either be used from your existing resources, or created using the sample data file that you can import from an S3 bucket. For this post, we guide you through importing sample data from an S3 bucket into a new DynamoDB table, providing a practical foundation for the concepts discussed.
To create a sample table in DynamoDB, complete the following steps:
- Download the fictitious ecommerce_customer_behavior.csv dataset. This dataset captures customer behavior and interactions on an ecommerce platform.
- On the Amazon S3 console, open the S3 bucket used by the SageMaker Unified Studio project.
- Upload the CSV file you downloaded.

- Select the uploaded file to view its details page.

- Copy the value for S3 URI and make a note of it; you will use this path for the subsequent DynamoDB table creation step.

Create a Dynamo DB table
Complete the following steps to create a DynamoDB table from a file from Amazon S3, using the import from Amazon S3 functionality. Then you can enable the settings on the DynamoDB table required to enable zero-ETL integration.
- On the DynamoDB console, select Imports from S3 in the navigation pane.
- Select Import from S3.

- Enter the S3 URI from previous step for Source S3 URL, select CSV for Import file format, and select Next.

- Provide the table name as
ecommerce_customer_behavior, the partition key as customer_id, and the sort key as product_id, then select Next.

- Use the default table settings, then select Next to review the details.

- Review the settings and select Import.

It will take a few minutes for the import status to change from Importing to Completed.


When the import is complete, you should be able to see the table created on the Tables page.

- Select the
ecommerce_customer_behavior table and select Edit PITR.

- Select Turn on point in time recovery and select Save changes.
This is required for setting up zero-ETL using DynamoDB as source.
On the Backups tab, you should see the status for PITR as On.

- Additionally, you need to use a table policy to enable access for zero-ETL integration. On the Permissions tab, and copy the following code under Resource-based policy for table:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "TablePolicy01",
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": [
"dynamodb:ExportTableToPointInTime",
"dynamodb:DescribeExport",
"dynamodb:DescribeTable"
],
"Resource": "*"
}
]
}
 This policy uses all the resources, which shouldn’t be used in production workload. To deploy this setup in production, restrict it to only specific zero-ETL integration resources by adding a condition to the resource-based policy.
This policy uses all the resources, which shouldn’t be used in production workload. To deploy this setup in production, restrict it to only specific zero-ETL integration resources by adding a condition to the resource-based policy.
Now that you have used the Amazon S3 import method to load a CSV file to create a DynamoDB table, you can enable zero-ETL integration on the table.
Validate permission settings
To validate if the catalog permission setting is appropriate, complete the following steps:
- On the AWS Glue console, select Databases in the navigation pane.

- Check for the database
salesmarketing_XXX.

- Select Catalog settings in the navigation pane, and save the permissions.
 The following code is an example of permissions for catalog settings:
The following code is an example of permissions for catalog settings:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<Account-id>:root"
},
"Action": "glue:CreateInboundIntegration",
"Resource": "arn:aws:glue:<region>:<Account-id>:database/salesmarketing_XXX"
},
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "glue:AuthorizeInboundIntegration",
"Resource": "arn:aws:glue:<region>:<Account-id>:database/salesmarketing_XXX"
}
]
}
Now you’re ready to create your zero-ETL integration.
Create a zero-ETL integration
Complete the following steps to create a zero-ETL integration:
- On the AWS Glue console, select Zero-ETL integrations in the navigation pane.

- Select “Create zero-ETL integration” to create a new configuration.

- Select Amazon DynamoDB as the source type.

- Under Source details, select
ecommerce_customer_behavior for DynamoDB table.


- Under Target details, provide the following information:
- For AWS account, select Use the current account.
- For Data warehouse or catalog, enter the account ID of your default catalog.
- For Target database, enter
salesmarketing_XXX.
- For Target IAM role, enter
datazone_usr_role_XXX.

- Under Output settings, select Unnest all fields and Use primary keys from DynamoDB tables, leave Configure target table name as the default value (
ecommerce_customer_behavior), then select Next.

- Enter zetl-ecommerce-customer-behavior for Name under Integration details, then select Next.

- Select Create and launch integration to launch the integration.

The status should be Creating after the integration is successfully initiated.
The status will change to Active in approximately a minute.
Verify that the SageMaker Lakehouse table exists. This process might take up to 15 minutes to complete, because the default refresh interval from DynamoDB is set to 15 minutes.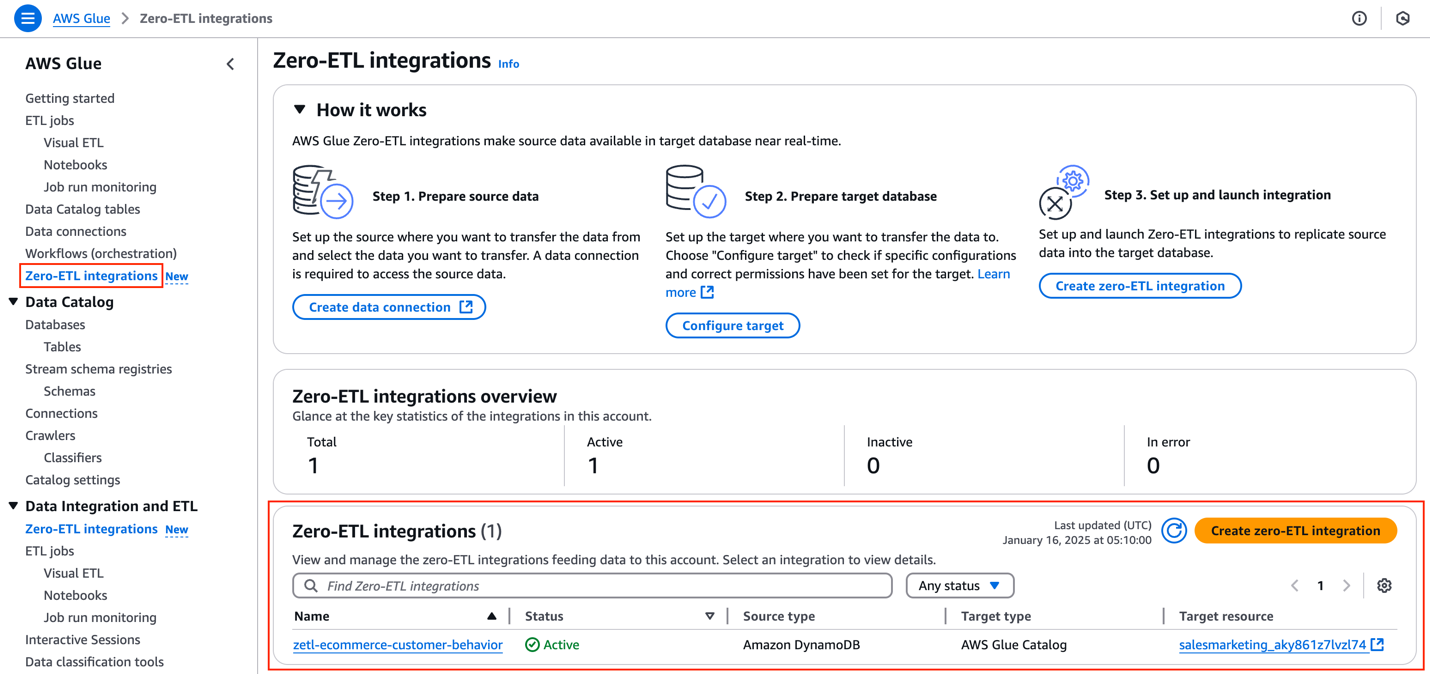

Validate the SageMaker Lakehouse table
You can now query your SageMaker Lakehouse table, created through zero-ETL integration, using various query engines. Complete the following steps to verify you can you see the table in SageMaker Unified Studio:
- Log in to the SageMaker Unified Studio portal using the single sign-on (SSO) option.

- Select your project to view its details page.

- Select Data in the navigation pane.

- Verify that you can see the Iceberg table in the SageMaker Lakehouse catalog.

Query with Athena
In this section, we show how to use Athena to query the SageMaker Lakehouse table from SageMaker Unified Studio. On the project page, locate the ecommerce_customer_behavior table in the catalog, and on the options menu (three dots), select Query with Athena.
This creates a SELECT query against the SageMaker Lakehouse table in a new window, and you should see the query results as shown in the following screenshot.
Query with Amazon Redshift
You can also query the SageMaker Lakehouse table from SageMaker Unified Studio using Amazon Redshift. Complete the following steps:
- Select the connection on the top right.
- Select Redshift (Lakehouse) from the list of connections.
- Select the
awsdatacatalog database.
- Select the
salesmarketing schema.
- Select Choose button.

The results will be shown in the Amazon Redshift Query Editor.
Query with Amazon EMR Serverless
You can query the Lakehouse table using Amazon EMR Serverless, which uses Apache Spark’s processing capabilities. Complete the following steps:
- On the project page, select Compute in the navigation pane.
- Select Add compute on the Data processing tab to create an EMR Serverless compute associated to the project.

- You can create new compute resources or connect to existing resources. For this example, select Create new compute resources.

- Select EMR Serverless.

- Enter a compute name (for example, Sales-Marketing), select the most recent release of EMR Serverless, and select Add compute.
It will take some time to create the compute.
You should see the status as Started for the compute. Now it’s ready to be used as your compute option for querying through a Jupyter notebook.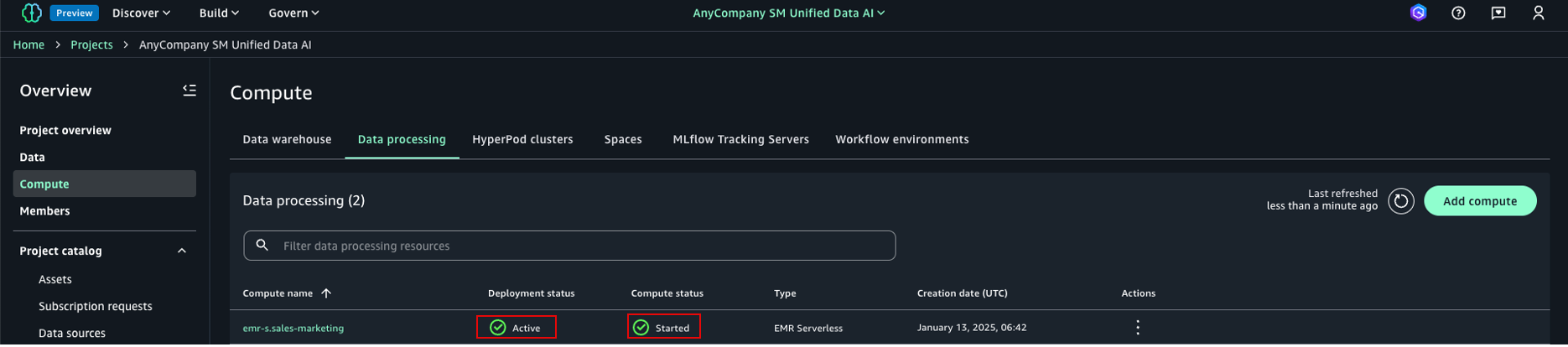
- Select the Build menu and select JupyterLab.
It will take some time to set up the workspace for running JupyterLab.
After the Jupyter Lab space is set up, you should see a page similar to the following screenshot.
- Select the new folder icon to create a new folder.

- Name the folder
lakehouse_zetl_lab.

- Navigate to the folder you just created and create a notebook under this folder.
- Select the notebook Python3 (ipykernel) on the Launcher tab, and rename the notebook to
query_lakehouse_table.

You can observe that the notebook is showing local Python as default language and compute. The two drop down menus show the connection type and compute for the selected connection type, just above the first cell within the Jupyter notebook.
- Select PySpark as the connection, and select the EMR Serverless application as compute.

- Enter the following sample code to query the table using Spark SQL:
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# Set the current database
spark.catalog.setCurrentDatabase("salesmarketing_XXX")
# Execute SQL query and store results in DataFrame
df = spark.sql("select * from ecommerce_customer_behavior limit 10")
# Display the results
df.show()

You can see the Spark DataFrame results.
Clean up
To avoid incurring future charges, delete the SageMaker domain, DynamoDB table, AWS Glue resources, and other objects created from this post.
Conclusion
This post demonstrated how you can establish a zero-ETL connection from DynamoDB to SageMaker Lakehouse, making your data available in Iceberg format without building custom data pipelines. We showed how you can analyze this DynamoDB data through various compute engines within SageMaker Unified Studio. This streamlined approach alleviates traditional data movement complexities, and enables more efficient data analysis workflows directly from your DynamoDB tables.
Try out this solution for your own use case, and share your feedback in the comments.
About the authors
 Narayani Ambashta is an Analytics Specialist Solutions Architect at AWS, focusing on the automotive and manufacturing sector, where she guides strategic customers in developing modern data and AI strategies. With over 15 years of cross-industry experience, she specializes in big data architecture, real-time analytics, and AI/ML technologies, helping organizations implement modern data architectures. Her expertise spans across lakehouse, generative AI, and IoT platforms, enabling customers to drive digital transformation initiatives. When not architecting modern solutions, she enjoys staying active through sports and yoga.
Narayani Ambashta is an Analytics Specialist Solutions Architect at AWS, focusing on the automotive and manufacturing sector, where she guides strategic customers in developing modern data and AI strategies. With over 15 years of cross-industry experience, she specializes in big data architecture, real-time analytics, and AI/ML technologies, helping organizations implement modern data architectures. Her expertise spans across lakehouse, generative AI, and IoT platforms, enabling customers to drive digital transformation initiatives. When not architecting modern solutions, she enjoys staying active through sports and yoga.
 Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with AWS. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life sciences, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with AWS. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life sciences, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
 Yadgiri Pottabhathini is a Senior Analytics Specialist Solutions Architect in the media and entertainment sector. He specializes in assisting enterprise customers with their data and analytics cloud transformation initiatives, while providing guidance on accelerating their Generative AI adoption through the development of data foundations and modern data strategies that leverage open-source frameworks and technologies.
Yadgiri Pottabhathini is a Senior Analytics Specialist Solutions Architect in the media and entertainment sector. He specializes in assisting enterprise customers with their data and analytics cloud transformation initiatives, while providing guidance on accelerating their Generative AI adoption through the development of data foundations and modern data strategies that leverage open-source frameworks and technologies.
 Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at AWS in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including Data Mesh, Data Lakehouse, and Generative AI, enabling customers to build scalable and innovative solutions on AWS.
Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at AWS in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including Data Mesh, Data Lakehouse, and Generative AI, enabling customers to build scalable and innovative solutions on AWS.