AWS Big Data Blog
Reduce time to access your transactional data for analytical processing using the power of Amazon SageMaker Lakehouse and zero-ETL
As the lines between analytics and AI continue to blur, organizations find themselves dealing with converging workloads and data needs. Historical analytics data is now being used to train machine learning models and power generative AI applications. This shift requires shorter time to value and tighter collaboration among data analysts, data scientists, machine learning (ML) engineers, and application developers. However, the reality of scattered data across various systems—from data lakes to data warehouses and applications—makes it difficult to access and use data efficiently. Moreover, organizations attempting to consolidate disparate data sources into a data lakehouse have historically relied on extract, transform, and load (ETL) processes, which have become a significant bottleneck in their data analytics and machine learning initiatives. Traditional ETL processes are often complex, requiring significant time and resources to build and maintain. As data volumes grow, so do the costs associated with ETL, leading to delayed insights and increased operational overhead. Many organizations find themselves struggling to efficiently onboard transactional data into their data lakes and warehouses, hindering their ability to derive timely insights and make data-driven decisions. In this post, we address these challenges with a two-pronged approach:
- Unified data management: Using Amazon SageMaker Lakehouse to get unified access to all your data across multiple sources for analytics and AI initiatives with a single copy of data, regardless of how and where the data is stored. SageMaker Lakehouse is powered by AWS Glue Data Catalog and AWS Lake Formation and brings together your existing data across Amazon Simple Storage Service (Amazon S3) data lakes and Amazon Redshift data warehouses with integrated access controls. In addition, you can ingest data from operational databases and enterprise applications to the lakehouse in near real-time using zero-ETL which is a set of fully-managed integrations by AWS that eliminates or minimizes the need to build ETL data pipelines.
- Unified development experience: Using Amazon SageMaker Unified Studio to discover your data and put it to work using familiar AWS tools for complete development workflows, including model development, generative AI application development, data processing, and SQL analytics, in a single governed environment.
In this post, we demonstrate how you can bring transactional data from AWS OLTP data stores like Amazon Relational Database Service (Amazon RDS) and Amazon Aurora flowing into Redshift using zero-ETL integrations to SageMaker Lakehouse Federated Catalog (Bring your own Amazon Redshift into SageMaker Lakehouse). With this integration, you can now seamlessly onboard the changed data from OLTP systems to a unified lakehouse and expose the same to analytical applications for consumptions using Apache Iceberg APIs from new SageMaker Unified Studio. Through this integrated environment, data analysts, data scientists, and ML engineers can use SageMaker Unified Studio to perform advanced SQL analytics on the transactional data.
Architecture patterns for a unified data management and unified development experience
In this architecture pattern, we show you how to use zero-ETL integrations to seamlessly replicate transactional data from Amazon Aurora MySQL-Compatible Edition, an operational database, into the Redshift Managed Storage layer. This zero-ETL approach eliminates the need for complex data extraction, transformation, and loading processes, enabling near real-time access to operational data for analytics. The transferred data is then cataloged using a federated catalog in the SageMaker Lakehouse Catalog and exposed through the Iceberg Rest Catalog API, facilitating comprehensive data analysis by consumer applications.
You then use SageMaker Unified Studio, to perform advanced analytics on the transactional data bridging the gap between operational databases and advanced analytics capabilities.

Prerequisites
Make sure that you have the following prerequisites:
- An AWS account with permission to create AWS Identity and Access Management (IAM) roles and policies
- Administrator access to one or more of the following sources: Aurora MySQL-Compatible and Amazon Redshift
- An AWS Identity and Access Management (IAM) user with an access key and secret key to configure the AWS Command Line Interface (AWS CLI). We recommend that you use temporary credentials using AWS IAM Identity Center as a security best practice for accessing your AWS accounts because these credentials are generated every time you sign in. See Getting IAM Identity Center user credentials for the AWS CLI or AWS SDKs steps to configure IAM Identity Center authentication.
Deployment steps
In this section, we share steps for deploying resources needed for Zero-ETL integration using AWS CloudFormation.
Setup resources with CloudFormation
This post provides a CloudFormation template as a general guide. You can review and customize it to suit your needs. Some of the resources that this stack deploys incur costs when in use. The CloudFormation template provisions the following components:
- An Aurora MySQL provisioned cluster (source).
- An Amazon Redshift Serverless data warehouse (target).
- Zero-ETL integration between the source (Aurora MySQL) and target (Amazon Redshift Serverless). See Aurora zero-ETL integrations with Amazon Redshift for more information.
Create your resources
To create resources using AWS Cloudformation, follow these steps:
- Sign in to the AWS Management Console.
- Select the
us-east-1AWS Region in which to create the stack. - Open the AWS CloudFormation
- Choose Launch Stack

- Choose Next.
This automatically launches CloudFormation in your AWS account with a template. It prompts you to sign in as needed. You can view the CloudFormation template from within the console. - For Stack name, enter a stack name, for example
UnifiedLHBlogpost. - Keep the default values for the rest of the Parameters and choose Next.
- On the next screen, choose Next.
- Review the details on the final screen and select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Submit.
Stack creation can take up to 30 minutes.
- After the stack creation is complete, go to the Outputs tab of the stack and record the values of the keys for the following components, which you will use in a later step:
- NamespaceName
- PortNumber
- RDSPassword
- RDSUsername
- RedshiftClusterSecurityGroupName
- RedshiftPassword
- RedshiftUsername
- VPC
- Workgroupname
- ZeroETLServicesRoleNameArn
Implementation steps
To implement this solution, follow these steps:
Setting up zero-ETL integration
A zero-ETL integration is already created as a part of CloudFormation template provided. Use the following steps from the Zero-ETL integration post to complete setting up the integration.:
- Create a database from integration in Amazon Redshift
- Populate source data in Aurora MySQL
- Validate the source data in your Amazon Redshift data warehouse
Bring Amazon Redshift metadata to the SageMaker Lakehouse catalog
Now that transactional data from Aurora MySQL is replicating into Redshift tables through zero-ETL integration, you next bring the data into SageMaker Lakehouse, so that operational data can co-exist and be accessed and governed together with other data sources in the data lake. You do this by registering an existing Amazon Redshift Serverless namespace that has Zero-ETL tables as a federated catalog in SageMaker Lakehouse.
Before starting the next steps, you need to configure data lake administrators in AWS Lake Formation.
- Go to the Lake Formation console and in the navigation pane, choose Administration roles and then choose Tasks under Administration. Under Data lake administrators, choose Add.
- In the Add administrators page, under Access type, select Data Lake administrator.
- Under IAM users and roles, select Admin. Choose Confirm.

- On the Add administrators page, for Access type, select Read-only administrators. Under IAM users and roles, select AWSServiceRoleForRedshift and choose Confirm. This step enables Amazon Redshift to discover and access catalog objects in AWS Glue Data Catalog.

With the data lake administrators configured, you’re ready to bring your existing Amazon Redshift metadata to SageMaker Lakehouse catalog:
- From the Amazon Redshift Serverless console, choose Namespace configuration in the navigation pane.
- Under Actions, choose Register with AWS Glue Data Catalog. You can find more details on registering a federated Amazon Redshift catalog in Registering namespaces to the AWS Glue Data Catalog.

- Choose Register. This will register the namespace to AWS Glue Data Catalog

- After registration is complete, the Namespace register status will change to Registered to AWS Glue Data Catalog.
- Navigate to the Lake Formation console and choose Catalogs New under Data Catalog in the navigation pane. Here you can see a pending catalog invitation is available for the Amazon Redshift namespace registered in Data Catalog.

- Select the pending invitation and choose Approve and create catalog. For more information, see Creating Amazon Redshift federated catalogs.

- Enter the Name, Description, and IAM role (created by the CloudFormation template). Choose Next.

- Grant permissions using a principal that is eligible to provide all permissions (an admin user).
- Select IAM users and rules and choose Admin.
- Under Catalog permissions, select Super user to grant super user permissions.

- Assigning super user permissions grants the user unrestricted permissions to the resources (databases, tables, views) within this catalog. Follow the principal of least privilege to grant users only the permissions required to perform a task wherever applicable as a security best practice.

- As final step, review all settings and choose Create Catalog

After the catalog is created, you will see two objects under Catalogs. dev refers to the local dev database inside Amazon Redshift, and aurora_zeroetl_integration is the database created for Aurora to Amazon Redshift ZeroETL tables

Fine-grained access control
To set up fine-grained access control, follow these steps:
- To grant permission to individual objects, choose Action and then select Grant.

- On the Principals page, grant access to individual objects or more than one object to different principals under the federated catalog.

Access lakehouse data using SageMaker Unified Studio
SageMaker Unified Studio provides an integrated experience outside the console to use all your data for analytics and AI applications. In this post, we show you how to use the new experience through the Amazon SageMaker management console to create a SageMaker platform domain using the quick setup method. To do this, you set up IAM Identity Center, a SageMaker Unified Studio domain, and then access data through SageMaker Unified Studio.
Set up IAM Identity Center
Before creating the domain, makes sure that your data admins and data workers are ready to use the Unified Studio experience by enabling IAM Identity Center for single sign-on following the steps in Setting up Amazon SageMaker Unified Studio. You can use Identity Center to set up single sign-on for individual accounts and for accounts managed through AWS Organizations. Add users or groups to the IAM instance as appropriate. The following screenshot shows an example email sent to a user through which they can activate their account in IAM Identity Center.

Set up SageMaker Unified domain
Follow steps in Create a Amazon SageMaker Unified Studio domain – quick setup to set up a SageMaker Unified Studio domain. You need to choose the VPC that was created by the CloudFormation stack earlier.
The quick setup method also has a Create VPC option that sets up a new VPC, subnets, NAT Gateway, VPC endpoints, and so on, and is meant for testing purposes. There are charges associated with this, so delete the domain after testing.

If you see the No models accessible, you can use the Grant model access button to grant access to Amazon Bedrock serverless models for use in SageMaker Unified Studio, for AI/ML use-cases
- Fill in the sections for Domain Name. For example,
MyOLTPDomain. In the VPC section, select the VPC that was provisioned by the CloudFormation stack, for example UnifiedLHBlogpost-VPC. Select subnets and choose Continue.

- In the IAM Identity Center User section, look up the newly created user from (for example, Data User1) and add them to the domain. Choose Create Domain. You should see the new domain along with a link to open Unified Studio.

Access data using SageMaker Unified Studio
To access and analyze your data in SageMaker Unified Studio, follow these steps:
-
- Select the URL for SageMaker Unified Studio. Choose Sign in with SSO and sign in using the IAM user, for example datauser1, and you will be prompted to select a multi-factor authentication (MFA) method.
- Select Authenticator App and proceed with next steps. For more information about SSO setup, see Managing users in Amazon SageMaker Unified Studio.After you have signed in to the Unified Studio domain, you need to set up a new project. For this illustration, we created a new sample project called MyOLTPDataProject using the project profile for SQL Analytics as shown here.A project profile is a template for a project that defines what blueprints are applied to the project, including underlying AWS compute and data resources. Wait for the new project to be set up, and when status is Active, open the project in Unified Studio.By default, the project will have access to the default Data Catalog (
AWSDataCatalog). For the federated redshift catalog redshift-consumer-catalog to be visible, you need to grant permissions to the project IAM role using Lake Formation. For this example, using the Lake Formation console, we have granted below access to the demodb database that is part of the Zero-ETL catalog to the Unified Studio project IAM role. Follow steps in Adding existing databases and catalogs using AWS Lake Formation permissions.In your SageMaker Unified Studio Project’s Data section, connect to the Lakehouse Federated catalog that you created and registered earlier (for exampleredshift-zetl-auroramysql-catalog/aurora_zeroetl_integration). Select the objects that you want to query and execute them using the Redshift Query Editor integrated with SageMaker Unified Studio.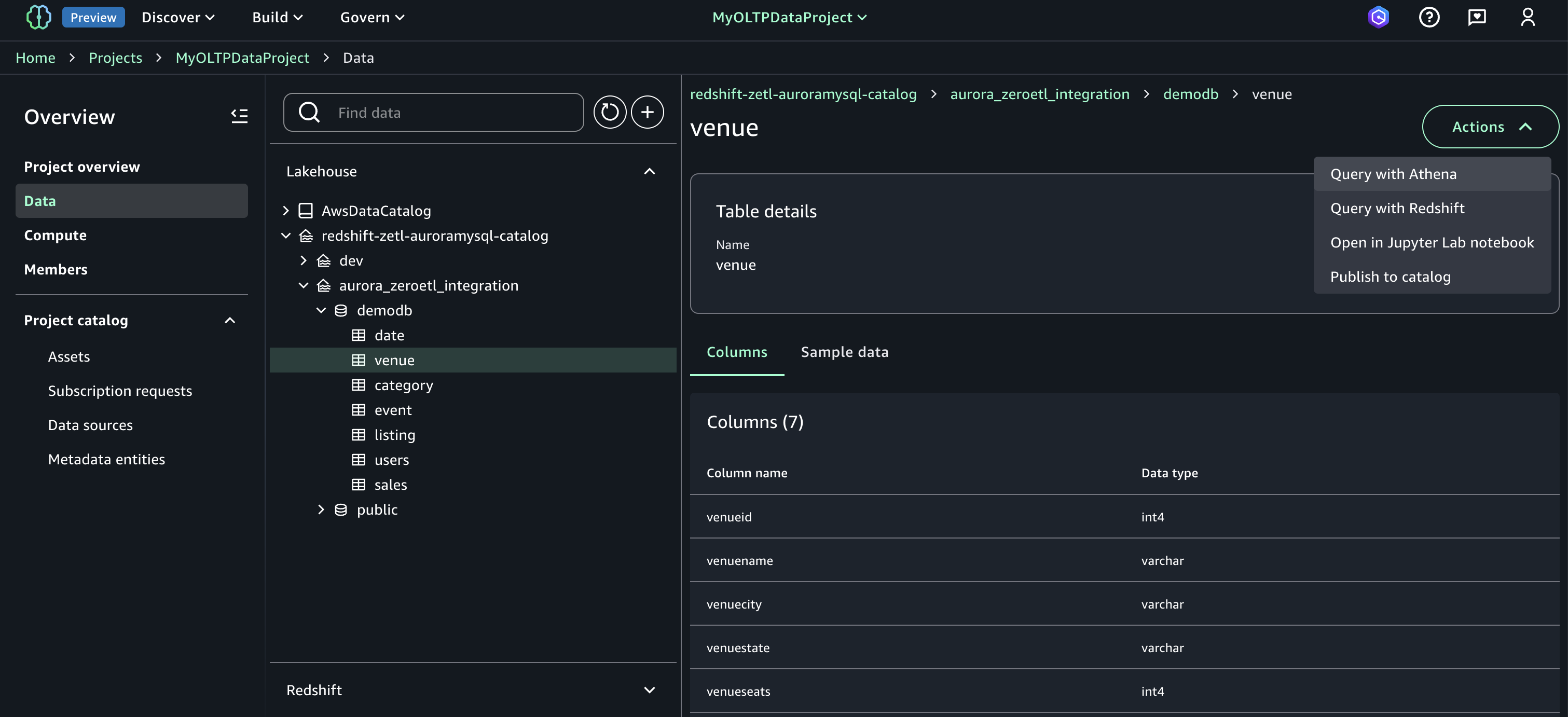 If you select Redshift, you will be transferred to the Query editor where you can execute the SQL and see the results as shown in the following figure.
If you select Redshift, you will be transferred to the Query editor where you can execute the SQL and see the results as shown in the following figure.
With this integration of Amazon Redshift metadata with SageMaker Lakehouse federated catalog, you have access to your existing Redshift data warehouse objects in your organizations centralized catalog managed by SageMaker Lakehouse catalog and join the existing Redshift data seamlessly with the data stored in your Amazon S3 data lake. This solution helps you avoid unnecessary ETL processes to copy data between the data lake and the data warehouse and minimize data redundancy.
You can further integrate more data sources serving transactional workloads such as Amazon DynamoDB and enterprise applications such as Salesforce and ServiceNow. The architecture shared in this post for accelerated analytical processing using Zero-ETL and SageMaker Lakehouse can be further expanded by adding Zero-ETL integrations for DynamoDB using DynamoDB zero-ETL integration with Amazon SageMaker Lakehouse and for enterprise applications by following the instructions in Simplify data integration with AWS Glue and zero-ETL to Amazon SageMaker Lakehouse
Clean up
When you’re finished, delete the CloudFormation stack to avoid incurring costs for some of the AWS resources used in this walkthrough incur a cost. Complete the following steps:
- On the CloudFormation console, choose Stacks.
- Choose the stack you launched in this walkthrough. The stack must be currently running.
- In the stack details pane, choose Delete.
- Choose Delete stack.
- On the Sagemaker console, choose Domains and delete the domain created for testing.
Summary
In this post, you’ve learned how to bring data from operational databases and applications into your lake house in near real-time through Zero-ETL integrations. You’ve also learned about a unified development experience to create a project and bring in the operational data to the lakehouse, which is accessible through SageMaker Unified Studio, and query the data using integration with Amazon Redshift Query Editor. You can use the following resources in addition to this post to quickly start your journey to make your transactional data available for analytical processing.
- AWS zero-ETL
- SageMaker Unified Studio
- SageMaker Lakehouse
- Getting started with Amazon SageMaker Lakehouse
About the authors
 Avijit Goswami is a Principal Data Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music.
Avijit Goswami is a Principal Data Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music.
 Saman Irfan is a Senior Specialist Solutions Architect focusing on Data Analytics at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies.
Saman Irfan is a Senior Specialist Solutions Architect focusing on Data Analytics at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies.
 Sudarshan Narasimhan is a Principal Solutions Architect at AWS specialized in data, analytics and databases. With over 19 years of experience in Data roles, he is currently helping AWS Partners & customers build modern data architectures. As a specialist & trusted advisor he helps partners build & GTM with scalable, secure and high performing data solutions on AWS. In his spare time, he enjoys spending time with his family, travelling, avidly consuming podcasts and being heartbroken about Man United’s current state.
Sudarshan Narasimhan is a Principal Solutions Architect at AWS specialized in data, analytics and databases. With over 19 years of experience in Data roles, he is currently helping AWS Partners & customers build modern data architectures. As a specialist & trusted advisor he helps partners build & GTM with scalable, secure and high performing data solutions on AWS. In his spare time, he enjoys spending time with his family, travelling, avidly consuming podcasts and being heartbroken about Man United’s current state.