AWS Big Data Blog
Introducing MCP Server for Apache Spark History Server for AI-powered debugging and optimization
Organizations running Apache Spark workloads, whether on Amazon EMR, AWS Glue, Amazon Elastic Kubernetes Service (Amazon EKS), or self-managed clusters, invest countless engineering hours in performance troubleshooting and optimization. When a critical extract, transform, and load (ETL) pipeline fails or runs slower than expected, engineers end up spending hours navigating through multiple interfaces such as logs or Spark UI, correlating metrics across different systems and manually analyzing execution patterns to identify root causes. Although Spark History Server provides detailed telemetry data, including job execution timelines, stage-level metrics, and resource consumption patterns, accessing and interpreting this wealth of information requires deep expertise in Spark internals and navigating through multiple interconnected web interface tabs.
Today, we’re announcing the open source release of Spark History Server MCP, a specialized Model Context Protocol (MCP) server that transforms this workflow by enabling AI assistants to access and analyze your existing Spark History Server data through natural language interactions. This project, developed collaboratively by AWS open source and Amazon SageMaker Data Processing, turns complex debugging sessions into conversational interactions that deliver faster, more accurate insights without requiring changes to your current Spark infrastructure. You can use this MCP server with your self-managed or AWS managed Spark History Servers to analyze Spark applications running in the cloud or on-premises deployments.
Understanding Spark observability challenge
Apache Spark has become the standard for large-scale data processing, powering critical ETL pipelines, real-time analytics, and machine learning (ML) workloads across thousands of organizations. Building and maintaining Spark applications is, however, still an iterative process, where developers spend significant time testing, optimizing, and troubleshooting their code. Spark application developers focused on data engineering and data integration use cases often encounter significant operational challenges due to a few different reasons:
- Complex connectivity and configuration options to a variety of resources with Spark – Although this makes it a popular data processing platform, it often makes it challenging to find the root cause of inefficiencies or failures when Spark configurations aren’t optimally or correctly configured.
- Spark’s in-memory processing model and distributed partitioning of datasets across its workers – Although good for parallelism, this often makes it difficult for users to identify inefficiencies. This results in slow application execution or root cause of failures caused by resource exhaustion issues such as out of memory and disk exceptions.
- Lazy evaluation of Spark transformations – Although lazy evaluation optimizes performance, it makes it challenging to accurately and quickly identify the application code and logic that caused the failure from the distributed logs and metrics emitted from different executors.
Spark History Server
Spark History Server provides a centralized web interface for monitoring completed Spark applications, serving comprehensive telemetry data including job execution timelines, stage-level metrics, task distribution, executor resource consumption, and SQL query execution plans. Although Spark History Server assists developers for performance debugging, code optimization, and capacity planning, it still has challenges:
- Time-intensive manual workflows – Engineers spend hours navigating through the Spark History Server UI, switching between multiple tabs to correlate metrics across jobs, stages, and executors. Engineers must constantly switch between the Spark UI, cluster monitoring tools, code repositories, and documentation to piece together a complete picture of application performance, which often takes days.
- Expertise bottlenecks – Effective Spark debugging requires deep understanding of execution plans, memory management, and shuffle operations. This specialized knowledge creates dependencies on senior engineers and limits team productivity.
- Reactive problem-solving – Teams typically discover performance issues only after they impact production systems. Manual monitoring approaches don’t scale to proactively identify degradation patterns across hundreds of daily Spark jobs.
How MCP transforms Spark observability
The Model Context Protocol provides a standardized interface for AI agents to access domain-specific data sources. Unlike general-purpose AI assistants operating with limited context, MCP-enabled agents can access technical information about specific systems and provide insights based on actual operational data rather than generic recommendations.With the help of Spark History Server accessible through MCP, instead of manually gathering performance metrics from multiple sources and correlating them to understand application behavior, engineers can engage with AI agents that have direct access to all Spark execution data. These agents can analyze execution patterns, identify performance bottlenecks, and provide optimization recommendations based on actual job characteristics rather than general best practices.
Introduction to Spark History Server MCP
The Spark History Server MCP is a specialized bridge between AI agents and your existing Spark History Server infrastructure. It connects to one or more Spark History Server instances and exposes their data through standardized tools that AI agents can use to retrieve application metrics, job execution details, and performance data.
Importantly, the MCP server functions purely as a data access layer, enabling AI agents such as Amazon Q Developer CLI, Claude desktop, Strands Agents, LlamaIndex, and LangGraph to access and reason about your Spark data. The following diagram shows this flow.
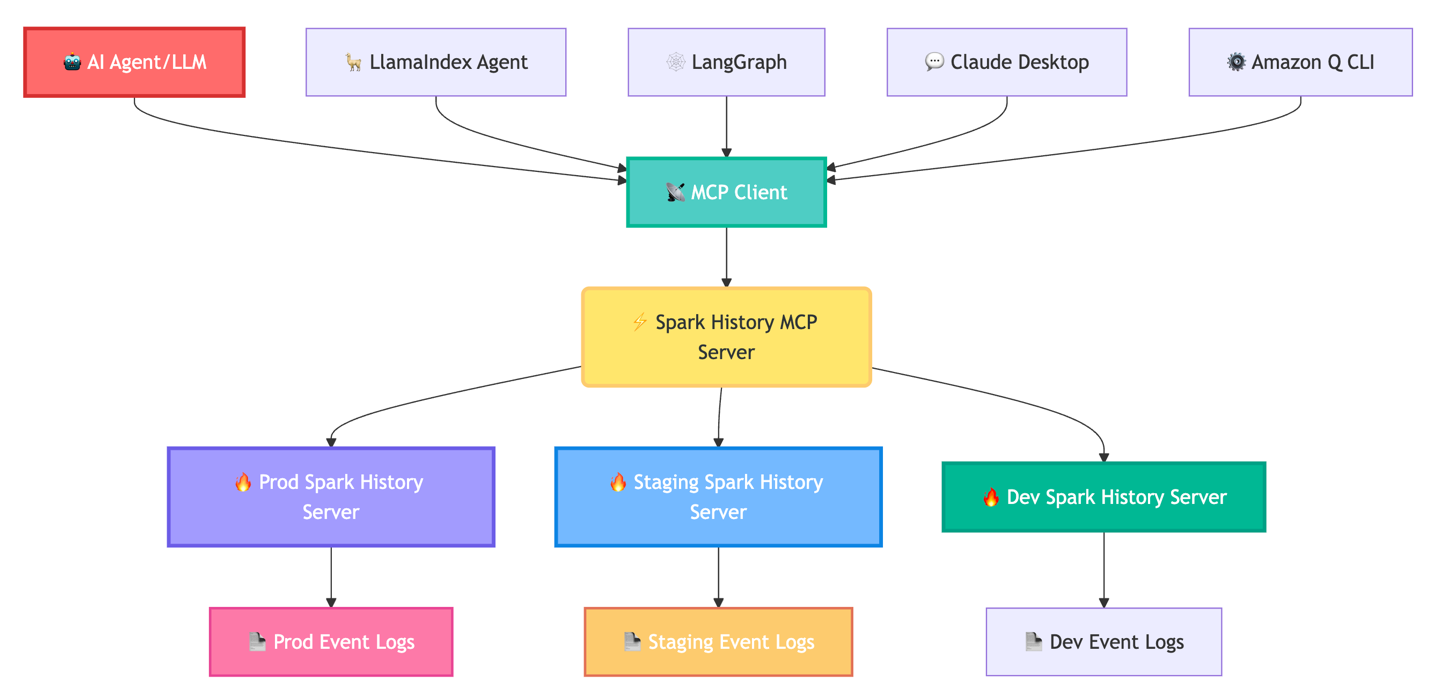
The Spark History Server MCP directly addresses these operational challenges by enabling AI agents to access Spark performance data programmatically. This transforms the debugging experience from manual UI navigation to conversational analysis. Instead of hours in the UI, ask, “Why did job spark-abcd fail?” and receive root cause analysis of the failure. This allows users to use AI agents for expert-level performance analysis and optimization recommendations, without requiring deep Spark expertise.
The MCP server provides comprehensive access to Spark telemetry across multiple granularity levels. Application-level tools retrieve execution summaries, resource utilization patterns, and success rates across job runs. Job and stage analysis tools provide execution timelines, stage dependencies, and task distribution patterns for identifying critical path bottlenecks. Task-level tools expose executor resource consumption patterns and individual operation timings for detailed optimization analysis. SQL-specific tools provide query execution plans, join strategies, and shuffle operation details for analytical workload optimization. You can review the complete set of tools available in the MCP server in the project README.
How to use the MCP server
The MCP is an open standard that enables secure connections between AI applications and data sources. This MCP server implementation supports both Streamable HTTP and STDIO protocols for maximum flexibility.
The MCP server runs as a local service within your infrastructure either on Amazon Elastic Compute Cloud (Amazon EC2) or Amazon EKS, connecting directly to your Spark History Server instances. You maintain complete control over data access, authentication, security, and scalability.
All the tools are available with streamable HTTP and STDIO protocol:
- Streamable HTTP – Full advanced tools for LlamaIndex, LangGraph, and programmatic integrations
- STDIO mode – Core functionality of Amazon Q CLI and Claude Desktop
For deployment, it supports multiple Spark History Server instances and provides deployments with AWS Glue, Amazon EMR, and Kubernetes.
Quick local setup
To set up Spark History MCP server locally, execute the following commands in your terminal:
For comprehensive configuration examples and integration guides, refer to the project README.
Integration with AWS managed services
The Spark History Server MCP integrates seamlessly with AWS managed services, offering enhanced debugging capabilities for Amazon EMR and AWS Glue workloads. This integration adapts to various Spark History Server deployments available across these AWS managed services while providing a consistent, conversational debugging experience:
- AWS Glue – Users can use the Spark History Server MCP integration with self-managed Spark History Server on an EC2 instance or launch locally using Docker container. Setting up the integration is straightforward. Follow the step-by-step instructions in the README to configure the MCP server with your preferred Spark History Server deployment. Using this integration, AWS Glue users can analyze AWS Glue ETL job performance regardless of their Spark History Server deployment approach.
- Amazon EMR – Integration with Amazon EMR uses the service-managed Persistent UI feature for EMR on Amazon EC2. The MCP server requires only an EMR cluster Amazon Resource Name (ARN) to discover the available Persistent UI on the EMR cluster or automatically configure a new one for cases its missing with token-based authentication. This eliminates the need for manually configuring Spark History Server setup while providing secure access to detailed execution data from EMR Spark applications. Using this integration, data engineers can ask questions about their Spark workloads, such as “Can you get job bottle neck for spark-<emr-applicationId>? ” The MCP responds with detailed analysis of execution patterns, resource utilization differences, and targeted optimization recommendations, so teams can fine-tune their Spark applications for optimal performance across AWS services.
For comprehensive configuration examples and integration details, refer to the AWS Integration Guides.
Looking ahead: The future of AI-assisted Spark optimization
This open-source release establishes the foundation for enhanced AI-powered Spark capabilities. This project establishes the foundation for deeper integration with AWS Glue and Amazon EMR to simplify the debugging and optimization experience for customers using these Spark environments. The Spark History Server MCP is open source under the Apache 2.0 license. We welcome contributions including new tool extensions, integrations, documentation improvements, and deployment experiences.
Get started today
Transform your Spark monitoring and optimization workflow today by providing AI agents with intelligent access to your performance data.
- Explore the GitHub repository
- Review the comprehensive README for setup and integration instructions
- Join discussions and submit issues for enhancements
- Contribute new features and deployment patterns
Acknowledgment: A special thanks to everyone who contributed to the development and open-sourcing of the Apache Spark history server MCP: Vaibhav Naik, Akira Ajisaka, Rich Bowen, Savio Dsouza.
About the authors
 Manabu McCloskey is a Solutions Architect at Amazon Web Services. He focuses on contributing to open source application delivery tooling and works with AWS strategic customers to design and implement enterprise solutions using AWS resources and open source technologies. His interests include Kubernetes, GitOps, Serverless, and Souls Series.
Manabu McCloskey is a Solutions Architect at Amazon Web Services. He focuses on contributing to open source application delivery tooling and works with AWS strategic customers to design and implement enterprise solutions using AWS resources and open source technologies. His interests include Kubernetes, GitOps, Serverless, and Souls Series.
 Vara Bonthu is a Principal Open Source Specialist SA leading Data on EKS and AI on EKS at AWS, driving open source initiatives and helping AWS customers to diverse organizations. He specializes in open source technologies, data analytics, AI/ML, and Kubernetes, with extensive experience in development, DevOps, and architecture. Vara focuses on building highly scalable data and AI/ML solutions on Kubernetes, enabling customers to maximize cutting-edge technology for their data-driven initiatives
Vara Bonthu is a Principal Open Source Specialist SA leading Data on EKS and AI on EKS at AWS, driving open source initiatives and helping AWS customers to diverse organizations. He specializes in open source technologies, data analytics, AI/ML, and Kubernetes, with extensive experience in development, DevOps, and architecture. Vara focuses on building highly scalable data and AI/ML solutions on Kubernetes, enabling customers to maximize cutting-edge technology for their data-driven initiatives
 Andrew Kim is a Software Development Engineer at AWS Glue, with a deep passion for distributed systems architecture and AI-driven solutions, specializing in intelligent data integration workflows and cutting-edge feature development on Apache Spark. Andrew focuses on re-inventing and simplifying solutions to complex technical problems, and he enjoys creating web apps and producing music in his free time.
Andrew Kim is a Software Development Engineer at AWS Glue, with a deep passion for distributed systems architecture and AI-driven solutions, specializing in intelligent data integration workflows and cutting-edge feature development on Apache Spark. Andrew focuses on re-inventing and simplifying solutions to complex technical problems, and he enjoys creating web apps and producing music in his free time.
 Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
 Kartik Panjabi is a Software Development Manager on the AWS Glue team. His team builds generative AI features for the Data Integration and distributed system for data integration.
Kartik Panjabi is a Software Development Manager on the AWS Glue team. His team builds generative AI features for the Data Integration and distributed system for data integration.
 Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.