AWS Big Data Blog
Integrating Amazon OpenSearch Ingestion with Amazon RDS and Amazon Aurora
Unlocking powerful search capabilities for millions of items should be fast, accurate, and effortless while maintaining high relevance. Relational databases are a popular storage method for structured data, and organizations use them extensively to store their core business information. Although relational databases excel at storing and retrieving structured data, they often struggle with searching through large blocks of unstructured text and, for performance reasons, typically don’t index all columns.
In contrast, search engines such as OpenSearch index all fields, enabling rich search capabilities, including semantic search, and powerful aggregations for summarizing and analyzing numeric data. Traditionally, organizations have managed complex, inefficient, and expensive data synchronization processes, including extract, transform, and load (ETL) pipelines, to keep their search indices up to date with their databases. Those looking to enhance their applications with advanced search features need a simpler solution that can maintain search index synchronization with their databases without the overhead of managing custom data sync processes.
We are happy to announce the general availability of the integration of Amazon OpenSearch Service with Amazon Relational Database Service (Amazon RDS) and Amazon Aurora. This new integration eliminates complex data pipelines and enables near real-time data synchronization between Amazon Aurora (including Amazon Aurora MySQL-Compatible Edition and Amazon Aurora PostgreSQL-Compatible Edition) and Amazon RDS databases (including Amazon RDS for MySQL and Amazon RDS for PostgreSQL), and Amazon OpenSearch Service, unlocking advanced search capabilities such as hybrid search, ranked results, and faceted search on transactional databases. You can now deliver low-latency, high-throughput search results, live inventory updates, and personalized recommendations while focusing on creating exceptional customer experiences instead of managing data synchronization. This integration reduces the operational burden of maintaining complex ETL pipelines, reducing costs while providing instant data availability for search operations.
Amazon OpenSearch Ingestion provides near real-time data synchronization between Amazon Aurora or Amazon RDS and OpenSearch Service. Select your Aurora or RDS database, and OpenSearch Ingestion handles the rest, supporting both Aurora MySQL or RDS for MySQL (8.0 and above) and Aurora PostgreSQL or RDS for PostgreSQL (16 and above).
Solution overview
Here’s how these services work together:
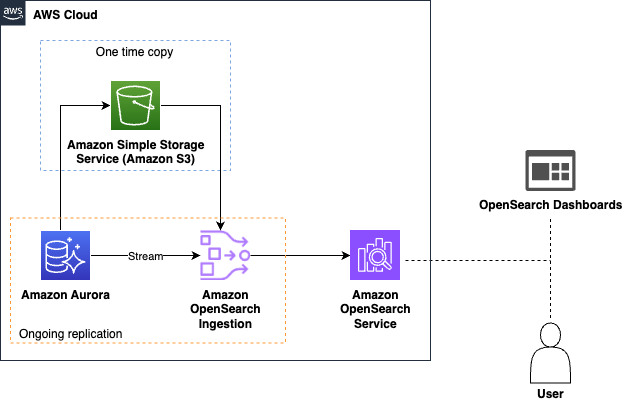
- Data ingestion – OpenSearch Ingestion first loads your database snapshot from Amazon Simple Storage Service (Amazon S3), where Aurora or Amazon RDS has exported the initial data. It then uses Aurora or Amazon RDS change data capture (CDC) streams to replicate further changes in near real time and indexes them into OpenSearch Service. This automated process keeps your data is consistently up to date in OpenSearch, making it readily available for search and analysis without manual intervention.
- Real-time querying – OpenSearch Service offers powerful query capabilities that enable you to perform complex searches and aggregations on your data. Whether you need to analyze trends, detect anomalies, or perform search queries to return relevant results for your application, OpenSearch Service provides the tools you need.
The following diagram illustrates the solution architecture for Amazon Aurora as a source:
Getting Started
Configuring Your Database Source
Before setting up synchronization, you need to configure your source database’s logging settings. For Aurora MySQL, configure your cluster parameter group with enhanced binary log settings. For Amazon RDS, enable basic binary logging or logical replication through your instance parameter group settings. These logging configurations enable OpenSearch Ingestion to capture and replicate data changes from your database.
The sample HR database with Aurora MySQL is a good example to show how this integration works.
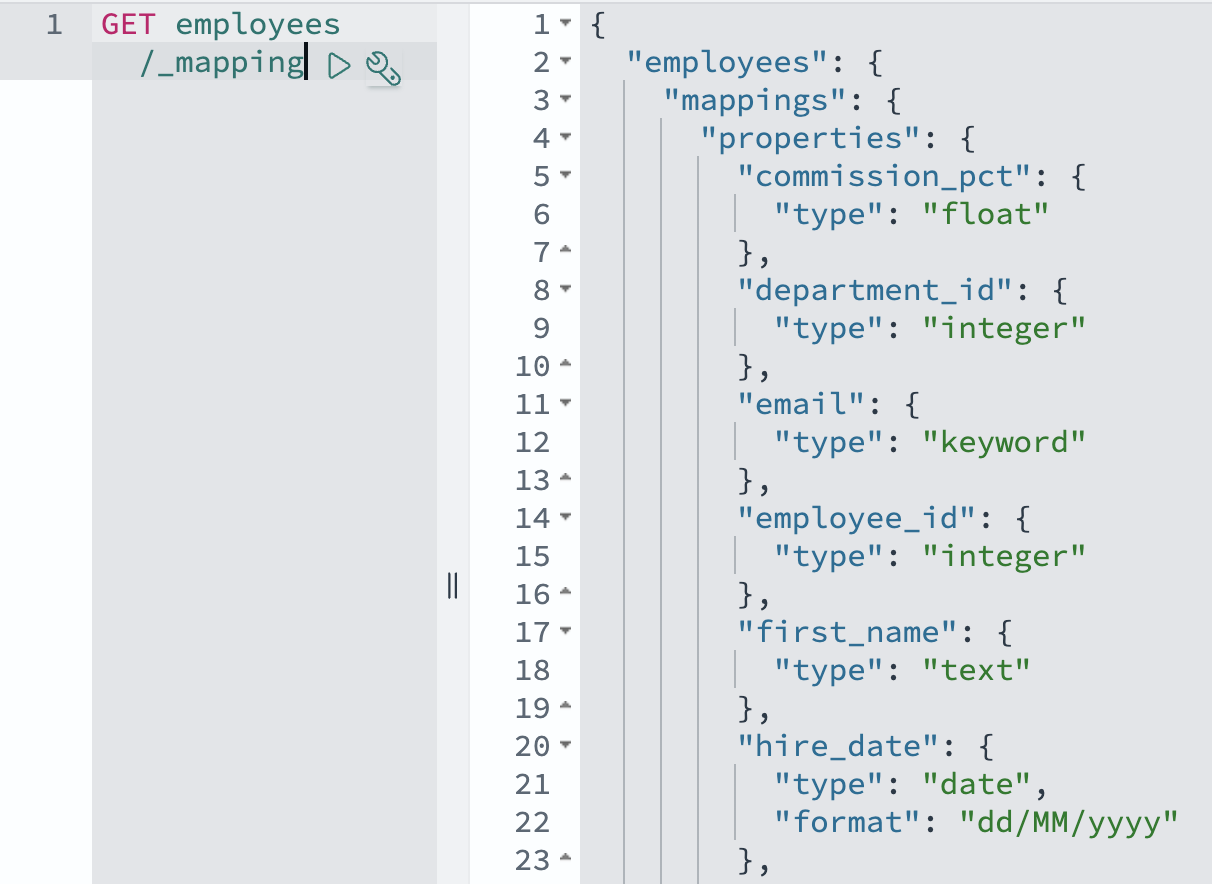
Before creating the view, we now explain how OpenSearch will represent this data. OpenSearch mappings define how documents and their fields are stored and indexed, similar to how a database schema defines tables and columns. The OpenSearch Ingestion pipeline uses dynamic mappings by default, automatically converting Aurora or Amazon RDS data types to appropriate OpenSearch field types. For example, database DATE fields become OpenSearch date types, and numeric fields are mapped to corresponding OpenSearch numeric types. Although you can customize these mappings using index templates, the default mappings typically handle common data types correctly, including dates, numbers, and text fields.
GET employees/_mapping
To demonstrate the integration’s ability to handle complex data relationships, we now examine how OpenSearch Ingestion handles joined data. We create a view in the sample HR database that combines information from multiple related tables into a single, searchable document in OpenSearch. This approach shows how you can transform normalized database structures into denormalized documents that are optimized for search operations.
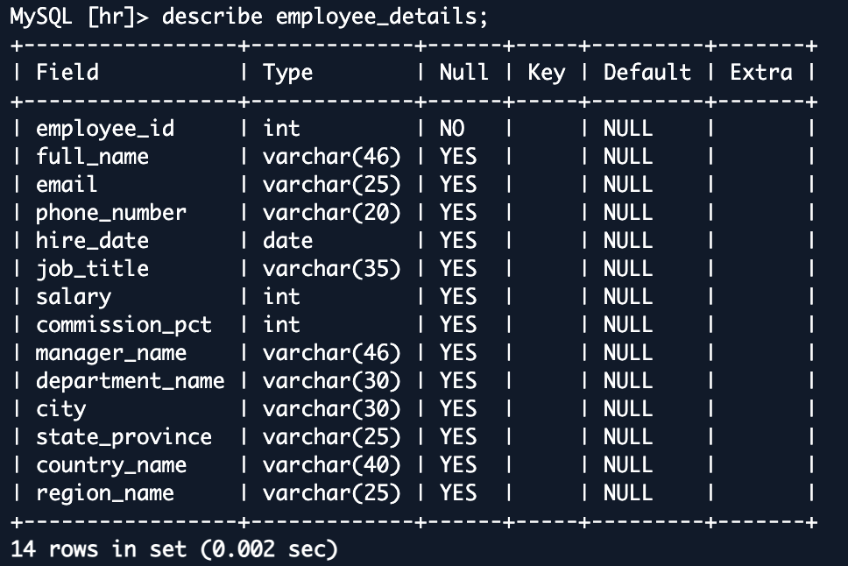
This employee_details view combines data from multiple tables, creating a rich, denormalized representation of employee information. When replicated to OpenSearch, this view becomes a single, comprehensive document for each employee. This structure is ideal for search operations, allowing for fast and complex queries across what were originally separate tables. For example, you could easily search for employees in a specific department and country or analyze salary distributions across regions—queries that would be more complex and potentially slower in the original normalized database structure.
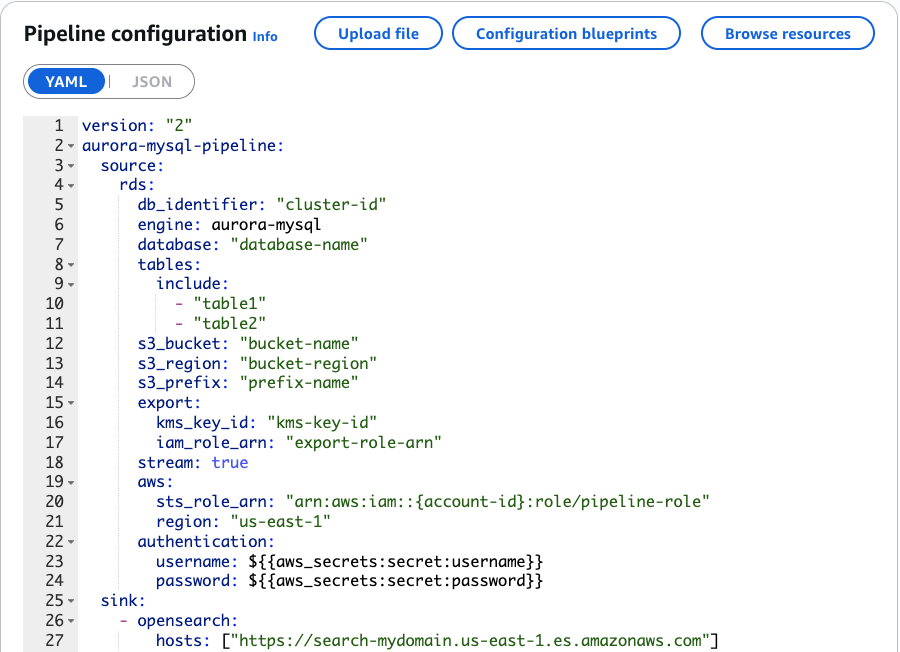
In the pipeline configuration shown in the following screenshot, you can check how OpenSearch Ingestion connects to the HR database. The configuration identifies the source database and the specific tables we want to replicate. While we created a view to understand the data relationships, the pipeline tracks changes from the underlying base tables (employees, departments, locations, and regions). OpenSearch Ingestion automatically maintains these relationships, which means that changes to these tables are properly reflected in your OpenSearch index, keeping your search data consistent with your source database.
In the gif shown below, you can see a demo of setting up this integration using the visual editor of OpenSearch Ingestion.
You can also specify index mapping templates to map your Aurora or Amazon RDS fields to the correct fields in your OpenSearch Service indexes.
For a comprehensive overview of configuration settings for the pipeline, refer to the OpenSearch Data Prepper documentation. You must set up AWS Identity and Access Management (IAM) roles for the pipeline. For instructions, refer to Configure the pipeline role.
After you configure the integration in OpenSearch Ingestion, the pipeline automatically creates indexes that you can view in OpenSearch Dashboards. OpenSearch Ingestion first triggers an automatic export of your Aurora or Amazon RDS database to Amazon S3, then loads this snapshot data from S3 into your OpenSearch cluster to create the initial indices. After this initial load, OpenSearch Ingestion continually captures changes using binary logs (binlog) for MySQL-based databases or write-ahead logs (WAL) for PostgreSQL-based databases. This way, your OpenSearch indices stay synchronized with your source database in near real time. You can view your indices in OpenSearch Dashboards by invoking:
GET _cat/indices
Example response:

Demonstrating near real time data synchronization
Consider the first five entries in the employee table:

When you make changes to your database, OpenSearch Ingestion updates Amazon OpenSearch Service with the change data. For example, the following code updates an employee’s salary:
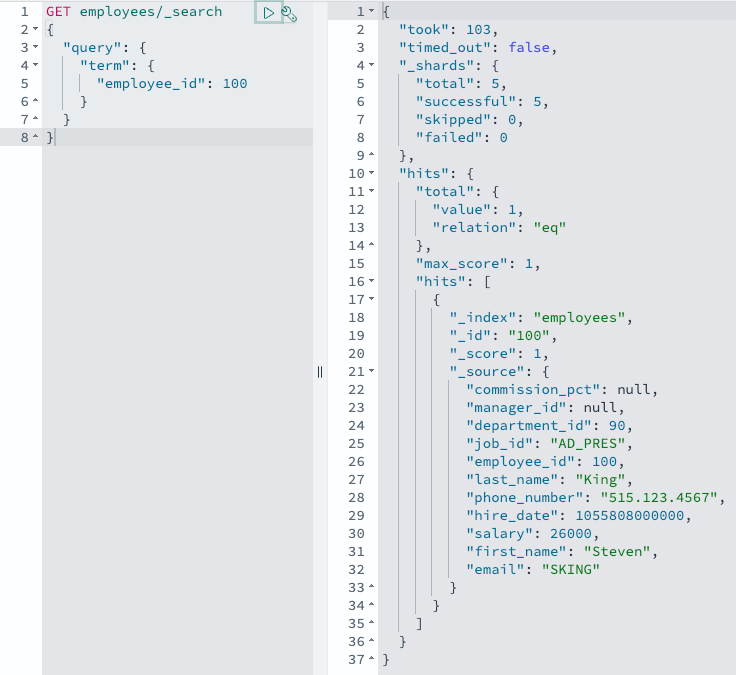
UPDATE hr.employees SET SALARY = 26000 WHERE EMPLOYEE_ID = 100;

Amazon Aurora sends out a change notice, your OpenSearch Ingestion pipeline picks it up, and OpenSearch Ingestion sends the changed record to OpenSearch in near real time. You can verify this with an OpenSearch query:
GET employees/_search
Important details about this feature:
- Monitoring – Track pipeline performance and data synchronization through CloudWatch metrics and the OpenSearch Ingestion dashboard
- Limitations – Requires same-Region and same-account deployment, primary keys for optimal synchronization, and currently has no data definition language (DDL) statement support
Conclusion
Amazon Aurora or Amazon RDS integration with Amazon OpenSearch Service is now generally available in all AWS Regions where OpenSearch Ingestion is available.
To learn more, refer to the AWS documentation for Aurora or Amazon RDS integration with Amazon OpenSearch Service:
- Using an OpenSearch Ingestion pipeline with Amazon Aurora – Amazon OpenSearch Service
- Using an OpenSearch Ingestion pipeline with Amazon RDS – Amazon OpenSearch Service
About the authors
 Michael Torio is an Associate Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Mountain View, CA. Michael enjoys helping customers leverage cloud technologies to solve their business challenges.
Michael Torio is an Associate Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Mountain View, CA. Michael enjoys helping customers leverage cloud technologies to solve their business challenges.
 Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
 Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington.
Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington.