AWS Big Data Blog
How Ancestry optimizes a 100-billion-row Iceberg table
This is a guest post by Thomas Cardenas, Staff Software Engineer at Ancestry, in partnership with AWS.
Ancestry, the global leader in family history and consumer genomics, uses family trees, historical records, and DNA to help people on their journeys of personal discovery. Ancestry has the largest collection of family history records, consisting of 40 billion records. They serve more than 3 million subscribers and have over 23 million people in their growing DNA network. Their customers can use this data to discover their family story.
Ancestry is proud to connect users with their families past and present. They help people learn more about their own identity by learning about their ancestors. Users build a family tree through which we surface relevant records, historical documents, photos, and stories that might contain details about their ancestors. These artifacts are surfaced through Hints. The Hints dataset is one of the most interesting datasets at Ancestry. It’s used to alert users that potential new information is available. The dataset has multiple shards, and there are currently 100 billion rows being used by machine learning models and analysts. Not only is the dataset large, it also changes rapidly.
In this post, we share the best practices that Ancestry used to implement an Apache Iceberg-based hints table capable of handling 100 billion rows with 7 million hourly changes. The optimizations covered here resulted in cost reductions of 75%.
Overview of solution
Ancestry’s Enterprise Data Management (EDM) team faced a critical challenge—how to provide a unified, performant data ecosystem that could serve diverse analytical workloads across financial, marketing, and product analytics teams. The ecosystem needed to support everything from data scientists training recommendation models to geneticists developing population studies—all requiring access to the same Hints data.
The ecosystem around Hints data had been developed organically, without a well-defined architecture. Teams independently accessed Hints data through direct service calls, Kafka topic subscriptions, or warehouse queries, creating significant data duplication and unnecessary system load. To reduce cost and improve performance, EDM implemented a centralized Apache Iceberg data lake on Amazon Simple Storage Service (Amazon S3), with Amazon EMR providing the processing power. This architecture, shown in the following image, creates a single source of truth for the Hints dataset while using Iceberg’s ACID transactions, schema evolution, and partition evolution capabilities to handle scale and update frequency.
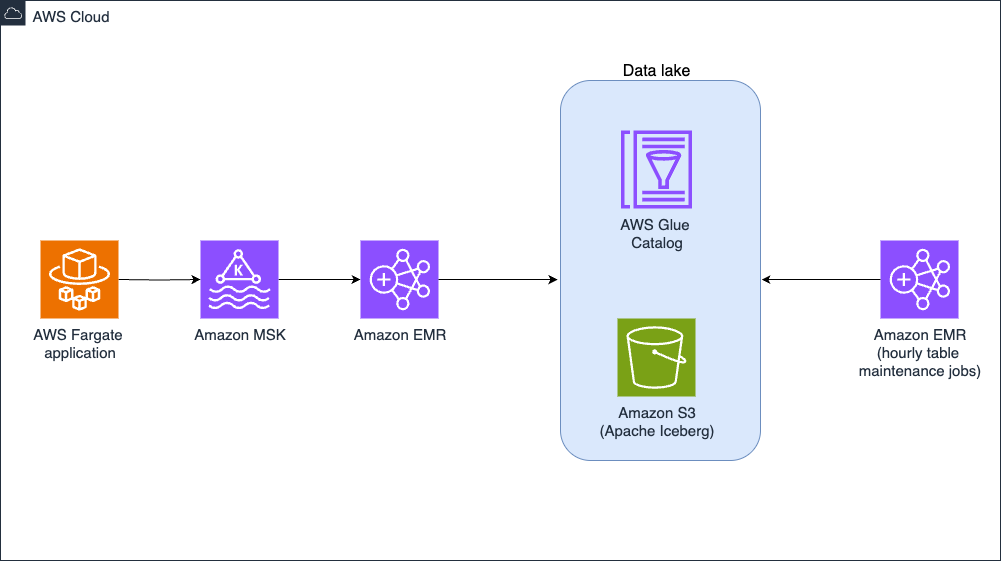
Hints table management architecture
Managing datasets exceeding one billion rows presents unique challenges, and Ancestry faced this challenge with the trees collection of 20–100 billion rows across multiple tables. At this scale, dataset updates require careful execution to control costs and prevent memory issues. To solve these challenges, EDM chose Amazon EMR on Amazon EC2 running Spark to write Iceberg tables on Amazon S3 for storage. With large and steady Amazon EMR workloads, running the clusters on Amazon EC2, as opposed to Serverless, proved cost effective. EDM has scheduled an Apache Spark job to run every hour on their Amazon EMR on EC2. This job uses the merge operation to update the Iceberg table with recently changed rows. Performing updates like this on such a large dataset can easily lead to runaway costs and out-of-memory errors.
Key optimization techniques
The engineers needed to enable fast, row-level updates without impacting query performance or incurring substantial cost. To achieve this, Ancestry used a combination of partitioning strategies, table configurations, Iceberg procedures, and incremental updates. The following is covered in detail:
- Partitioning
- Sorting
- Merge-on-read
- Compaction
- Snapshot management
- Storage-partitioned joins
Partitioning strategy
Developing an effective partitioning strategy was crucial for the 100-billion-row Hints table. Iceberg supports various partition transforms including column value, temporal functions (year, month, day, hour), and numerical transforms (bucket, truncate). Following AWS best practices, Ancestry carefully analyzed query patterns to identify a partitioning approach that would support these queries while balancing these two competing considerations:
- Too few partitions would force queries to scan excessive data, degrading performance and increasing costs.
- Too many partitions would create small files and excessive metadata, causing management overhead and slower query planning. It’s generally best to avoid parquet files smaller than 100 MB.
Through query pattern analysis, Ancestry discovered that most analytical queries filtered on hint status (particularly pending status) and hint type. This insight led us to implement a two-level partitioning strategy-first on status and then on type, which dramatically reduced the amount of data scanned during typical queries.
Sorting
To further optimize query performance, Ancestry implemented strategic data organization within partitions using Iceberg’s sort orders. While Iceberg doesn’t maintain perfect ordering, even approximate sorting significantly improves data locality and compression ratios.
For the Hints table with 100 billion rows, Ancestry faced a unique challenge: the primary identifiers (PersonId and HintId) are high-cardinality numeric columns that would be prohibitively expensive to sort completely. The solution uses Iceberg’s truncate transform function to support sorting on just a portion of the number, effectively creating another partition by grouping a collection of IDs together. For example, we can specify truncate(100_000_000, hintId) to create groups of 100 million hint IDs, greatly improving the performance of queries that specify that column.
Merge on read
With 7 million changes to the Hints table occurring hourly, optimizing write performance became critical to the architecture. In addition to making sure queries performed well, Ancestry also needed to make sure our frequent updates would perform well in both time and cost. It was quickly discovered that the default copy-on-write (CoW) strategy, which copies an entire file when any part of it changes, was too slow and expensive for their use case. Ancestry was able to get the performance we needed by instead specifying the merge-on-read (MoR) update strategy, which maintains new information in diff files that are reconciled on read. The large updates that happen every hour led us to choose faster updates at the cost of slower reads.
File compaction
The frequent updates mean files are constantly needing to be re-written to maintain performance. Iceberg provides the rewrite_data_files procedure for compaction, but default configurations proved insufficient for our scale. Leaving the default configuration in place, the rewrite operation wrote to five partitions at a time and didn’t meet our performance objective. We found that increasing the concurrent writes improved performance. We used the following set of parameters, setting a relatively high max-concurrent-file-group-rewrites value of 100 to more efficiently deal with our thousands of partitions. The default of rewriting only one file at a time couldn’t keep up with the frequency of our updates.
Key optimizations in Ancestry’s approach include:
- High concurrency: We increased
max-concurrent-file-group-rewritesfrom the default 5 to 100, enabling parallel processing of our thousands of partitions. This increased compute costs but was necessary to help ensure that the jobs finished. - Resilience at scale: We enabled
partial-progressto create compaction checkpoints, essential when operating at our scale where failures are particularly costly. - Comprehensive delta elimination: Setting
rewrite-alltotruehelps ensure that both data files and delete files are compacted, preventing the accumulation of delete files. By default, the delete files created as part of this strategy aren’t re-written and would continue to accumulate, slowing queries.
We arrived at these optimizations through successive trials and evaluations. For example, with our very large dataset, we discovered that we could use a WHERE clause to limit re-writes to a single partition. Based on the partitions, we see varied execution times and resource utilization. For some partitions, we needed to reduce concurrency to avoid running into out of memory errors.
Snapshot management
Iceberg tables maintain snapshots to preserve the history of the table, allowing you to time travel through the changes. As these snapshots accrue, they add to storage costs and degrade performance. This is why maintaining an Iceberg table requires you to periodically call the expire_snapshots procedure. We found we needed to enable concurrency for snapshot management so that it would complete in a timely manner:
Consider how to balance performance, cost, and the need to keep historical records depending on your use case. When you do so, note that there is a table-level setting for maximum snapshot age which can override the retain_last parameter and retain only the active snapshot.
Reducing shuffle with Storage-Partitioned Joins
We use Storage-Partitioned Joins (SPJ) in Iceberg tables to minimize expensive shuffles during data processing. SPJ is an advanced Iceberg feature (available in Spark 3.3 or later with Iceberg 1.2 or later) that uses the physical storage layout of tables to eliminate shuffle operations entirely. For our Hints update pipeline, this optimization was transformational.
SPJ is especially useful during MERGE INTO operations, where datasets have identical partitioning. Proper configuration helps ensure effective use of SPJ to optimize joins.
SPJ has a few requirements such as both tables must be Iceberg partitioned the same way and joined on the partition key. Then Iceberg will know that it doesn’t have to shuffle the data when the tables are loaded. This even works when there are a different number of partitions on either side.
Updates to the Hints database are first staged in the Hint Changes database where data is transformed from the original Kafka data format into how it will look in the target (Hints) table. This is a temporary Iceberg table where we are able to perform audits using Write-Audit-Publish (WAP) pattern. In addition to using the WAP pattern we are able to use the SPJ functionality.
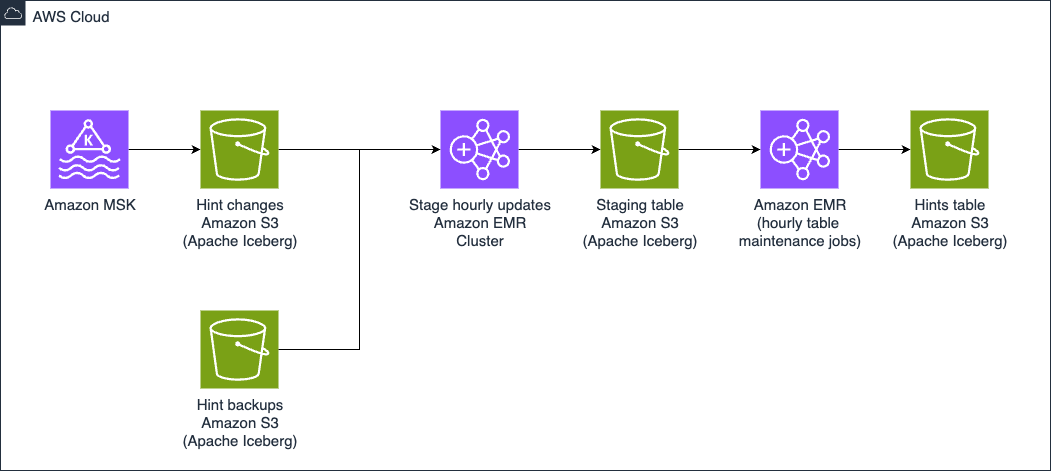
The Hints data pipeline
Reducing full-table scans
Another strategy to reduce shuffle is minimizing the data involved in joins by dynamically pushing down filters. In production, these filters vary between batches, so a multi-step operation is often necessary for setting up merges. The following example code first limits its scope by setting minimum and maximum values for the ID, then performs an update or delete to the target table depending on whether a target value exists.
This technique reduces cost in several ways: the bounded merge reduces the number of affected rows, it allows for predicate pushdown optimization, which filters at the storage layer, and it reduces shuffle operations when compared with a join.
Additional insights
Apart from the Hints table, we have implemented over 1,000 Iceberg tables in our data ecosystem. The following are some key insights that we observed:
- Updating a table using
MERGEis typically the most expensive action, so this is where we spent the most time optimizing. It was still our best option. - Using complex data types can help co-locate similar data in the table.
- Monitor costs of each pipeline because while following good practice you can stumble across things you miss that are causing costs to increase.
Conclusion
Organizations can use Apache Iceberg tables on Amazon S3 with Amazon EMR to manage massive datasets with frequent updates. Many customers will be able to achieve excellent performance with a low maintenance burden by using the AWS Glue table optimizer for automatic, asynchronous compaction. Some customers, like Ancestry, will require custom optimizations of their maintenance procedures to meet their cost and performance goals. These customers should start with a careful assessment of query patterns to develop a partitioning strategy to minimize the amount of data that needs to be read and processed. Update frequency and latency requirements will dictate other choices, like whether merge-on-read or copy-on-write is the better strategy.
If your organization faces similar challenges with high volumes of data requiring frequent updates, you can use a combination of Apache Iceberg’s advanced features with AWS services like Amazon EMR Serverless, Amazon S3, and AWS Glue to build a truly modern data lake that delivers the scale, performance, and cost-efficiency you need.
Further reading
- How Iceberg works
- Build a high-performance, ACID compliant, evolving data lake using Apache Iceberg on Amazon EMR