AWS Big Data Blog
Enhance data ingestion performance in Amazon Redshift with concurrent inserts
Amazon Redshift is a fully managed petabyte data warehousing service in the cloud. Its massively parallel processing (MPP) architecture processes data by distributing queries across compute nodes. Each node executes identical query code on its data portion, enabling parallel processing.
Amazon Redshift employs columnar storage for database tables, reducing overall disk I/O requirements. This storage method significantly improves analytic query performance by minimizing data read during queries. Data has become many organizations’ most valuable asset, driving demand for real-time or near real-time analytics in data warehouses. This demand necessitates systems that support simultaneous data loading while maintaining query performance. This post showcases the key improvements in Amazon Redshift concurrent data ingestion operations.
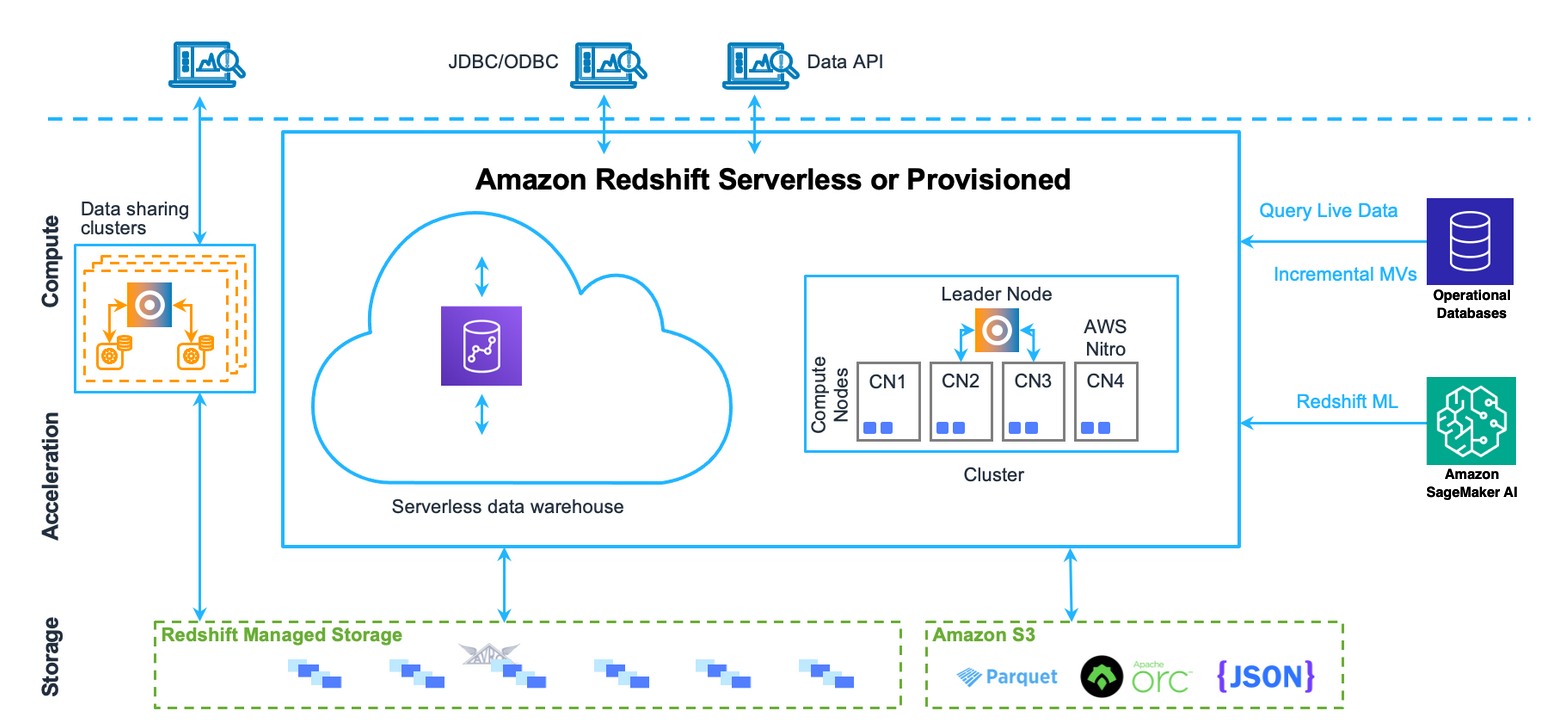
Challenges and pain points for write workloads
In a data warehouse environment, managing concurrent access to data is crucial yet challenging. Customers using Amazon Redshift ingest data using various approaches. For example, you might commonly use INSERT and COPY statements to load data to a table, which are also called pure write operations. You might have requirements for low-latency ingestions to maximize data freshness. To achieve this, you can submit queries concurrently to the same table. To enable this, Amazon Redshift implements snapshot isolation by default. Snapshot isolation provides data consistency when multiple transactions are running simultaneously. Snapshot isolation guarantees that each transaction sees a consistent snapshot of the database as it existed at the start of the transaction, preventing read and write conflicts that could compromise data integrity. With snapshot isolation, read queries are able to execute in parallel, so you can take advantage of the full performance that the data warehouse has to offer.
However, pure write operations execute sequentially. Specifically, pure write operations need to acquire an exclusive lock during the entire transaction. They only release the lock when the transaction has committed the data. In these cases, the performance of the pure write operations is constrained by the speed of serial execution of the writes across sessions.
To understand this better, let’s look at how a pure write operation works. Every pure write operation includes pre-ingestion tasks such as scanning, sorting, and aggregation on the same table. After the pre-ingestion tasks are complete, the data is written to the table while maintaining data consistency. Because the pure write operations run serially, even the pre-ingestion steps ran serially due to lack of concurrency. This means that when multiple pure write operations are submitted concurrently, they are processed one after another, with no parallelization even for the pre-ingestion steps. To improve the concurrency of ingestion to the same table and meet low latency requirements for ingestion, customers often use workarounds through the use of staging tables. Specifically, you can submit INSERT ... VALUES(..) statements into staging tables. Then, you perform joins with other tables, such FACT and DIMENSION tables, prior to appending data using ALTER TABLE APPEND into your target tables. This approach isn’t desirable because it requires you to maintain staging tables and potentially have a larger storage footprint due to data block fragmentation from the use of ALTER TABLE APPEND statements.
In summary, the sequential execution of concurrent INSERT and COPY statements, due to their exclusive locking behavior, creates challenges if you want to maximize the performance and efficiency of your data ingestion workflows in Amazon Redshift. To overcome these limitations, you must adopt workaround solutions, introducing additional complexity and overhead. The following section outlines how Amazon Redshift has addressed these pain points with improvements to concurrent inserts.
Concurrent inserts and its benefits
With Amazon Redshift patch 187, Amazon Redshift has introduced significant improvement in concurrency for data ingestion with support for concurrent inserts. This improves concurrent execution of pure write operations such as COPY and INSERT statements, accelerating the time for you to load data into Amazon Redshift. Specifically, multiple pure write operations are able to progress simultaneously and complete pre-ingestion tasks such as scanning, sorting, and aggregation in parallel.
To visualize this improvement, let’s consider an example of two queries, executed concurrently from different transactions.
The following is query 1 in transaction 1:
The following is query 2 in transaction 2:
The following figure illustrates a simplified visualization of pure write operations without concurrent inserts.

Without concurrent inserts, the key components are as follows:
- First, both pure write operations (INSERT) need to read data from
table bandtable c, respectively. - The segment in pink is the scan step (reading data) and the segment in green is write step (actually inserting the data).
- In the “Before concurrent inserts” state, both queries would run sequentially. Specifically, the scan step in query 2 waits for the insert step in query 1 to complete before it begins.
For example, consider two identically sized queries across different transactions. Both queries need to scan the same amount of data and insert the same amount of data into the target table. Let’s say both are issued at 10:00 AM. First, query 1 would spend from 10:00 AM to 10:50 AM scanning the data and 10:50 AM to 11:00 AM inserting the data. Next, because query 2 is identical in scan and insertion volumes, query 2 would spend from 11:00 AM to 11:50 AM scanning the data and 11:50 AM to 12:00 PM inserting the data. Both transactions started at 10:00 AM. The end-to-end runtime is 2 hours (transaction 2 ends at 12:00 PM).The following figure illustrates a simplified visualization of pure write operations with concurrent inserts, compared with the previous example.

With concurrent inserts enabled, the scan step of query 1 and query 2 can progress simultaneously. When either of the queries need to insert data, they now do so serially. Let’s consider the same example, with two identically sized queries across different transactions. Both queries need to scan the same amount of data and insert the same amount of data into the target table. Again, let’s say both are issued at 10:00 AM. At 10:00 AM, query 1 and query 2 begin executing concurrently. From 10:00 AM to 10:50 AM, query 1 and query 2 are able to scan the data in parallel. From 10:50 AM to 11:00 AM, query 1 inserts the data into the target table. Next, from 11:00 AM to 11:10 AM, query 2 inserts the data into the target table. The total end-to-end runtime for both transactions is now reduced to 1 hour and 10 minutes, with query 2 completing at 11:10 AM. In this scenario, the pre-ingestion steps (scanning the data) for both queries are able to run concurrently, taking the same amount of time as in the previous example (50 minutes). However, the actual insertion of data into the target table is now executed serially, with query 1 completing the insertion first, followed by query 2. This demonstrates the performance benefits of the concurrent inserts feature in Amazon Redshift. By allowing the pre-ingestion steps to run concurrently, the overall runtime is improved by 50 minutes compared to the sequential execution before the feature was introduced.
With concurrent inserts, pre-ingestion steps are able to progress simultaneously. Pre-ingestion tasks could be one or a combination of tasks, such as scanning, sorting, and aggregation. There are significant performance benefits achieved in the end-to-end runtime of the queries.
Benefits
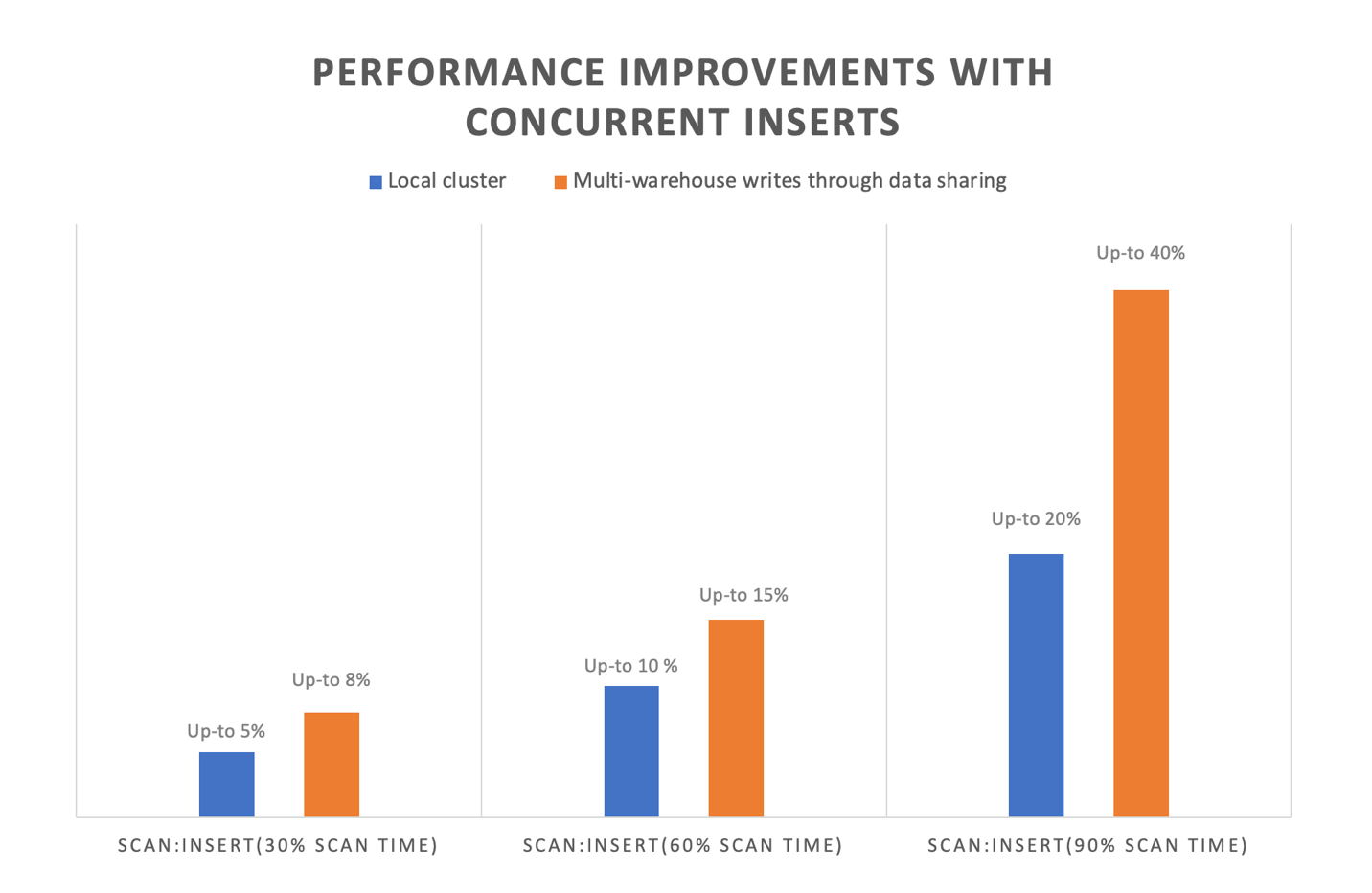
You can now benefit from these performance improvements without any additional configuration because the concurrent processing is handled automatically by the service. There are multiple benefits from the improvements in concurrent inserts. You can experience the improvement of end-to-end performance of ingestion workloads when you’re writing to the same table. Internal benchmarking shows that concurrent inserts can improve end-to-end runtime by up to 40% for concurrent insert transactions to the same tables. This feature is particularly beneficial for scan-heavy queries (queries that spend more time reading data than they spend time writing data). The higher the ratio of scan:insert in any query, higher the performance improvement expected.
This feature also improves the throughput and performance for multi-warehouse writes through data sharing. Multi-warehouse writes through data sharing helps you scale your write workloads across dedicated Redshift clusters or serverless workgroups, optimizing resource utilization and achieving more predictable performance for your extract, transform, and load (ETL) pipelines. Specifically, in multi-warehouse writes through data sharing, queries from different warehouses can write data on the same table. Concurrent inserts improve the end-to-end performance of these queries by reducing resource contention and enabling them to make progress simultaneously.
The following figure shows the performance improvements from internal tests from concurrent inserts, with the orange bar indicating the performance improvement for multi-warehouse writes through data sharing and the blue bar denoting the performance improvement for concurrent inserts on the same warehouse. As the graph indicates, queries with higher scan components relative to insert components benefit up to 40% with this new feature.
You can also experience additional benefits as a result of using concurrent inserts to manage your ingestion pipelines. When you directly write data to the same tables by using the benefit of concurrent inserts instead of using workarounds with ALTER TABLE APPEND statements, you can reduce your storage footprint. This comes in two forms: first from the elimination of temporary tables, and second from the reduction in table fragmentation from frequent ALTER TABLE APPEND statements. Additionally, you can avoid operational overhead of managing complex workarounds and rely on frequent background and customer-issued VACUUM DELETE operations to manage the fragmentation caused by appending temporary tables to your target tables.
Considerations
Although the concurrent insert enhancements in Amazon Redshift provide significant benefits, it’s important to be aware of potential deadlock scenarios that can arise in a snapshot isolation environment. Specifically, in a snapshot isolation environment, deadlocks can occur in certain conditions when running concurrent write transactions on the same table. The snapshot isolation deadlock happens when concurrent INSERT and COPY statements are sharing a lock and making progress, and another statement needs to perform an operation (UPDATE, DELETE, MERGE, or DDL operation) that requires an exclusive lock on the same table.
Consider the following scenario:
- Transaction 1:
- Transaction 2:
A deadlock can occur when multiple transactions with INSERT and COPY operations are running concurrently on the same table with a shared lock, and one of those transactions follows its pure write operation with an operation that requires an exclusive lock, such as an UPDATE, MERGE, DELETE, or DDL statement. To avoid the deadlock in these situations, you can separate statements requiring an exclusive lock (UPDATE, MERGE, DELETE, DDL statements) to a different transaction so that INSERT and COPY statements can progress simultaneously, and the statements requiring exclusive locks can execute after them. Alternatively, for transactions with INSERT and COPY statements and MERGE, UPDATE, and DELETE statements on same table, you can include retry logic in your applications to work around potential deadlocks. Refer to Potential deadlock situation for concurrent write transactions involving a single table for more information about deadlocks, and see Concurrent write examples for examples of concurrent transactions.
Conclusion
In this post, we demonstrated how Amazon Redshift has addressed a key challenge: improving concurrent data ingestion performance into a single table. This enhancement can help you meet your requirements for low latency and stricter SLAs when accessing the latest data. The update exemplifies our commitment to implementing critical features in Amazon Redshift based on customer feedback.
About the authors
 Raghu Kuppala is an Analytics Specialist Solutions Architect experienced working in the databases, data warehousing, and analytics space. Outside of work, he enjoys trying different cuisines and spending time with his family and friends.
Raghu Kuppala is an Analytics Specialist Solutions Architect experienced working in the databases, data warehousing, and analytics space. Outside of work, he enjoys trying different cuisines and spending time with his family and friends.
 Sumant Nemmani is a Senior Technical Product Manager at AWS. He is focused on helping customers of Amazon Redshift benefit from features that use machine learning and intelligent mechanisms to enable the service to self-tune and optimize itself, ensuring Redshift remains price-performant as they scale their usage.
Sumant Nemmani is a Senior Technical Product Manager at AWS. He is focused on helping customers of Amazon Redshift benefit from features that use machine learning and intelligent mechanisms to enable the service to self-tune and optimize itself, ensuring Redshift remains price-performant as they scale their usage.
 Gagan Goel is a Software Development Manager at AWS. He ensures that Amazon Redshift features meet customer needs by prioritising and guiding the team in delivering customer-centric solutions, monitor and enhance query performance for customer workloads.
Gagan Goel is a Software Development Manager at AWS. He ensures that Amazon Redshift features meet customer needs by prioritising and guiding the team in delivering customer-centric solutions, monitor and enhance query performance for customer workloads.
 Kshitij Batra is a Software Development Engineer at Amazon, specializing in building resilient, scalable, and high-performing software solutions.
Kshitij Batra is a Software Development Engineer at Amazon, specializing in building resilient, scalable, and high-performing software solutions.
 Sanuj Basu is a Principal Engineer at AWS, driving the evolution of Amazon Redshift into a next-generation, exabyte-scale cloud data warehouse. He leads engineering for Redshift’s core data platform — including managed storage, transactions, and data sharing — enabling customers to power seamless multi-cluster analytics and modern data mesh architectures.
Sanuj Basu is a Principal Engineer at AWS, driving the evolution of Amazon Redshift into a next-generation, exabyte-scale cloud data warehouse. He leads engineering for Redshift’s core data platform — including managed storage, transactions, and data sharing — enabling customers to power seamless multi-cluster analytics and modern data mesh architectures.