AWS Big Data Blog
Category: Intermediate (200)

Announcing the AWS Well-Architected Data Analytics Lens
We are delighted to announce the latest version of the Data Analytics Lens, an AWS Well-Architected whitepaper. AWS Well-Architected provides a consistent approach to evaluate architectures and implement scalable designs. The AWS Well-Architected Framework is based on six pillars—operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability. With the framework, cloud architects, system architects, engineers, and developers can build secure, high-performance, resilient, and efficient infrastructure for their applications and workloads.

Run Trino queries 2.7 times faster with Amazon EMR 6.15.0
In this blog, we compare Amazon EMR 6.15.0 with open source Trino 426 and show that TPC-DS queries ran up to 2.7 times faster on Amazon EMR 6.15.0 Trino 426 compared to open source Trino 426. Later, we explain a few of the AWS-developed performance optimizations that contribute to these results.

Amazon Managed Service for Apache Flink now supports Apache Flink version 1.18
Apache Flink is an open source distributed processing engine, offering powerful programming interfaces for both stream and batch processing, with first-class support for stateful processing and event time semantics. Apache Flink supports multiple programming languages, Java, Python, Scala, SQL, and multiple APIs with different level of abstraction, which can be used interchangeably in the same […]

Measure performance of AWS Glue Data Quality for ETL pipelines
In this post, we provide benchmark results of running increasingly complex data quality rulesets over a predefined test dataset. As part of the results, we show how AWS Glue Data Quality provides information about the runtime of extract, transform, and load (ETL) jobs, the resources measured in terms of data processing units (DPUs), and how you can track the cost of running AWS Glue Data Quality for ETL pipelines by defining custom cost reporting in AWS Cost Explorer.

Build a pseudonymization service on AWS to protect sensitive data: Part 2
Part 1 of this two-part series described how to build a pseudonymization service that converts plain text data attributes into a pseudonym or vice versa. A centralized pseudonymization service provides a unique and universally recognized architecture for generating pseudonyms. Consequently, an organization can achieve a standard process to handle sensitive data across all platforms. Additionally, […]
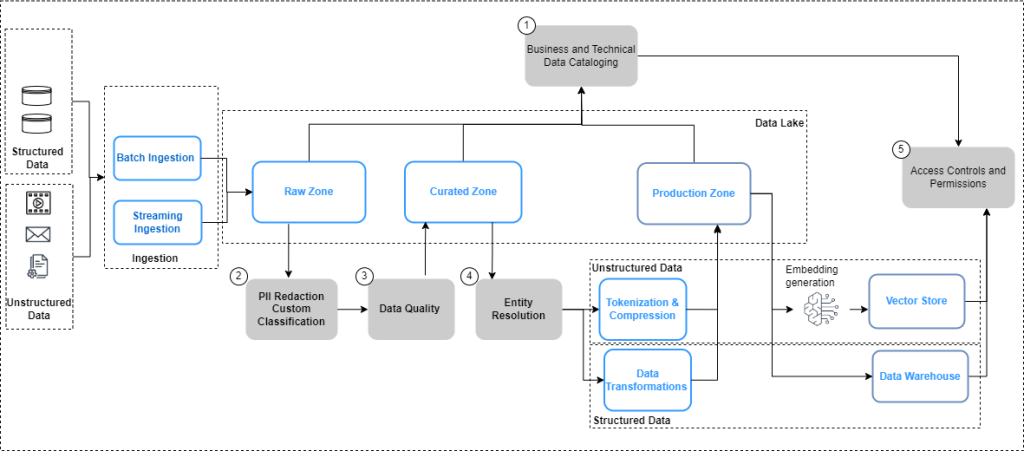
Data governance in the age of generative AI
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Working with large language models (LLMs) for enterprise use cases requires the implementation of quality and privacy considerations to drive responsible AI. However, enterprise data generated from siloed sources combined with […]

Use Amazon OpenSearch Ingestion to migrate to Amazon OpenSearch Serverless
Amazon OpenSearch Serverless is an on-demand auto scaling configuration for Amazon OpenSearch Service. Since its release, the interest for OpenSearch Serverless had been steadily growing. Customers prefer to let the service manage its capacity automatically rather than having to manually provision capacity. Until now, customers have had to rely on using custom code or third-party […]

Enhance monitoring and debugging for AWS Glue jobs using new job observability metrics, Part 2: Real-time monitoring using Grafana
Monitoring data pipelines in real time is critical for catching issues early and minimizing disruptions. AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics, which provide valuable insights into your data integration pipelines built on AWS Glue. However, you might need to track key performance indicators across multiple […]

Automate AWS Clean Rooms querying and dashboard publishing using AWS Step Functions and Amazon QuickSight – Part 2
Public health organizations need access to data insights that they can quickly act upon, especially in times of health emergencies, when data needs to be updated multiple times daily. For example, during the COVID-19 pandemic, access to timely data insights was critically important for public health agencies worldwide as they coordinated emergency response efforts. Up-to-date […]

Use multiple bookmark keys in AWS Glue JDBC jobs
AWS Glue is a serverless data integrating service that you can use to catalog data and prepare for analytics. With AWS Glue, you can discover your data, develop scripts to transform sources into targets, and schedule and run extract, transform, and load (ETL) jobs in a serverless environment. AWS Glue jobs are responsible for running […]