AWS Big Data Blog
Category: AWS Lambda
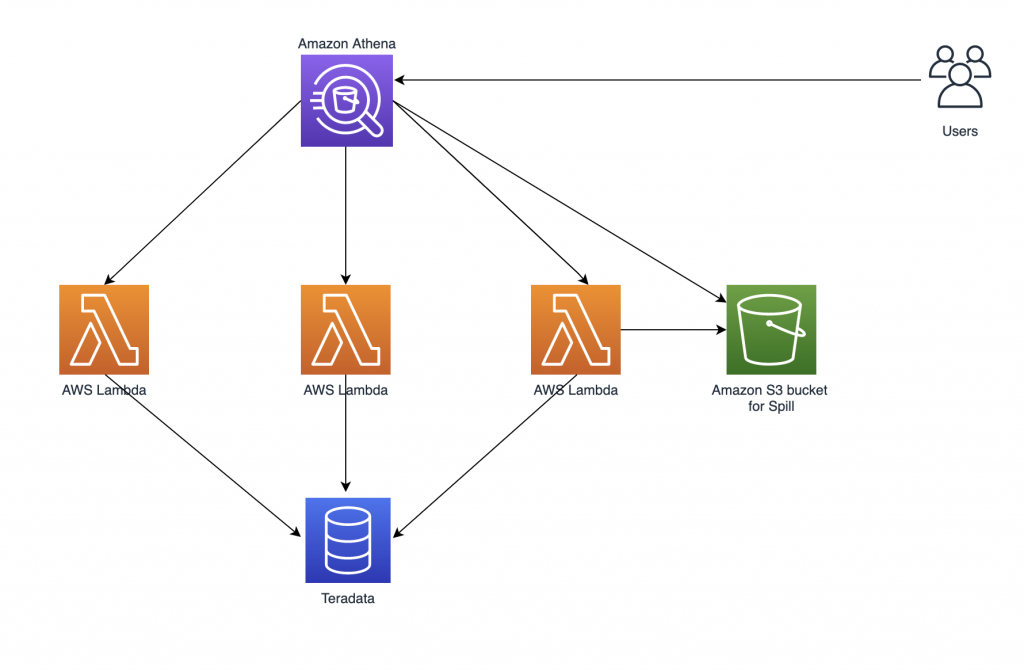
Query a Teradata database using Amazon Athena Federated Query and join with data in your Amazon S3 data lake
If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Teradata as your transactional data store, you may need to join the data in your data lake with Teradata in the cloud, Teradata running on Amazon Elastic Compute Cloud (Amazon EC2), or with an on-premises Teradata database, for example to build […]
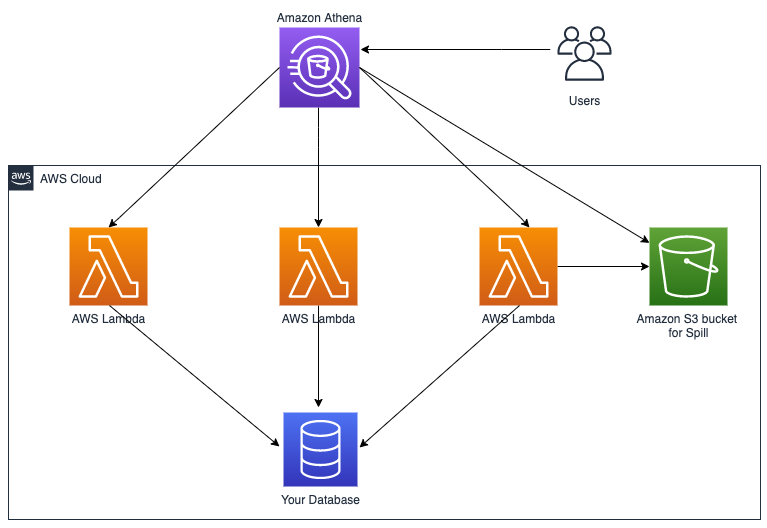
Query Snowflake using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Snowflake as your data warehouse solution, you may need to join your data in your data lake with Snowflake. For example, you may want to build […]

Auto scaling Amazon Kinesis Data Streams using Amazon CloudWatch and AWS Lambda
This post is co-written with Noah Mundahl, Director of Public Cloud Engineering at United Health Group. Update (12/1/2021): Amazon Kinesis Data Streams On-Demand mode is now the recommended way to natively auto scale your Amazon Kinesis Data Streams. In this post, we cover a solution to add auto scaling to Amazon Kinesis Data Streams. Whether […]

Query your Oracle database using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Oracle as your transactional data store, you may need to join the data in your data lake with Oracle on Amazon Relational Database Service (Amazon RDS), Oracle running on Amazon […]

Create a secure data lake by masking, encrypting data, and enabling fine-grained access with AWS Lake Formation
You can build data lakes with millions of objects on Amazon Simple Storage Service (Amazon S3) and use AWS native analytics and machine learning (ML) services to process, analyze, and extract business insights. You can use a combination of our purpose-built databases and analytics services like Amazon EMR, Amazon OpenSearch Service, and Amazon Redshift as […]

Automate Amazon ES synonym file updates
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Search engines provide the means to retrieve relevant content from a collection of content. However, this can be challenging if certain exact words aren’t entered. You need to find the right item from a catalog of products, or the correct […]
Build a serverless tracking pixel solution in AWS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Let’s describe the typical use case where a tracking pixel solution, also known as a web beacon, might help you: Analyzing web traffic is critical to understanding […]

Automate dynamic mapping and renaming of column names in data files using AWS Glue: Part 1
A common challenge ETL and big data developers face is working with data files that don’t have proper name header records. They’re tasked with renaming the columns of the data files appropriately so that downstream application and mappings for data load can work seamlessly. One example use case is while working with ORC files and […]

Automate dynamic mapping and renaming of column names in data files using AWS Glue: Part 2
In Part 1 of this two-part post, we looked at how we can create an AWS Glue ETL job that is agnostic enough to rename columns of a data file by mapping to column names of another file. The solution focused on using a single file that was populated in the AWS Glue Data Catalog […]

Data monetization and customer experience optimization using telco data assets: Part 2
Part 1 of this series explains the importance of building and implementing a customer experience (CX) management and data monetization strategy for telecom service providers (TSPs), and the major challenges driving these initiatives. It also includes an AWS CloudFormation template to set up a demonstration of the solution using AWS services. It covers transforming and enriching […]