AWS Big Data Blog
Category: Analytics

Run Jupyter Notebook and JupyterHub on Amazon EMR
NOTE: Please note that as of EMR 5.14.0, JupyterHub is an officially supported application. We recommend you use the most recent version of EMR if you would like to run JupyterHub on EMR. In addition, EMR Notebooks allow you to create and open Jupyter notebooks with the Amazon EMR console. We will not provide any […]
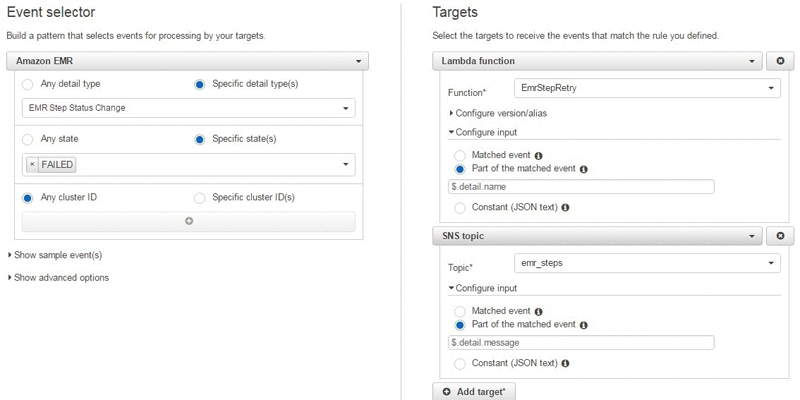
Respond to State Changes on Amazon EMR Clusters with Amazon CloudWatch Events
Jonathan Fritz is a Senior Product Manager for Amazon EMR Customers can take advantage of the Amazon EMR API to create and terminate EMR clusters, scale clusters using Auto Scaling or manual resizing, and submit and run Apache Spark, Apache Hive, or Apache Pig workloads. These decisions are often triggered from cluster state-related information. Previously, […]

Building an Event-Based Analytics Pipeline for Amazon Game Studios’ Breakaway
All software developers strive to build products that are functional, robust, and bug-free, but video game developers have an extra challenge: they must also create a product that entertains. When designing a game, developers must consider how the various elements—such as characters, story, environment, and mechanics—will fit together and, more importantly, how players will interact […]
Using SaltStack to Run Commands in Parallel on Amazon EMR
Miguel Tormo is a Big Data Support Engineer in AWS Premium Support Amazon EMR provides a managed Hadoop framework that makes it easy, fast, and cost-effective to process vast amounts of data across dynamically scalable Amazon EC2 instances. Amazon EMR defines three types of nodes: master node, core nodes, and task nodes. It’s common to […]

Joining and Enriching Streaming Data on Amazon Kinesis
Are you trying to move away from a batch-based ETL pipeline? You might do this, for example, to get real-time insights into your streaming data, such as clickstream, financial transactions, sensor data, customer interactions, and so on. If so, it’s possible that as soon as you get down to requirements, you realize your streaming data […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Table Data Durability
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings Part 5: Table Data Durability (Translated into Japanese) In the fifth and final installment of the Advanced Table Design Playbook, I’ll discuss how to use two simple table durability properties to […]

Interactive Analysis of Genomic Datasets Using Amazon Athena
Aaron Friedman is a Healthcare and Life Sciences Solutions Architect with Amazon Web Services The genomics industry is in the midst of a data explosion. Due to the rapid drop in the cost to sequence genomes, genomics is now central to many medical advances. When your genome is sequenced and analyzed, raw sequencing files are […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Compression Encodings
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings (Translated into Japanese) Part 5: Table Data Durability In part 4 of this blog series, I’ll be discussing when and when not to apply column encoding for compression, methods for determining ideal […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Compound and Interleaved Sort Keys
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys (Translated into Japanese) Part 4: Compression Encodings Part 5: Table Data Durability In this installment, I’ll cover different sort key options, when to use sort keys, and how to identify the most optimal sort key […]

Amazon Redshift Engineering’s Advanced Table Design Playbook: Distribution Styles and Distribution Keys
Part 1: Preamble, Prerequisites, and Prioritization Part 2: Distribution Styles and Distribution Keys (Translated into Japanese) Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings Part 5: Table Data Durability The first table and column properties we discuss in this blog series are table distribution styles (DISTSTYLE) and distribution keys (DISTKEY). This blog […]