AWS Big Data Blog
Build a streaming data mesh using Amazon Kinesis Data Streams
Organizations face an ever-increasing need to process and analyze data in real time. Traditional batch processing methods no longer suffice in a world where instant insights and immediate responses to market changes are crucial for maintaining competitive advantage. Streaming data has emerged as the cornerstone of modern data architectures, helping businesses capture, process, and act upon data as it’s generated.
As customers move from batch to real-time processing for streaming data, organizations are facing another challenge: scaling data management across the enterprise, because the centralized data platform can become the bottleneck. Data mesh for streaming data has emerged as a solution to address this challenge, building on the following principles:
- Distributed domain-driven architecture – Moving away from centralized data teams to domain-specific ownership
- Data as a product – Treating data as a first-class product with clear ownership and quality standards
- Self-serve data infrastructure – Enabling domains to manage their data independently
- Federated data governance – Following global standards and policies while allowing domain autonomy
A streaming mesh applies these principles to real-time data movement and processing. This mesh is a modern architectural approach that enables real-time data movement across decentralized domains. It provides a flexible, scalable framework for continuous data flow while maintaining the data mesh principles of domain ownership and self-service capabilities. A streaming mesh represents a modern approach to data integration and distribution, breaking down traditional silos and helping organizations create more dynamic, responsive data ecosystems.
AWS provides two primary solutions for streaming ingestion and storage: Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Amazon Kinesis Data Streams. These services are key to building a streaming mesh on AWS. In this post, we explore how to build a streaming mesh using Kinesis Data Streams.
Kinesis Data Streams is a serverless streaming data service that makes it straightforward to capture, process, and store data streams at scale. The service can continuously capture gigabytes of data per second from hundreds of thousands of sources, making it ideal for building streaming mesh architectures. Key features include automatic scaling, on-demand provisioning, built-in security controls, and the ability to retain data for up to 365 days for replay purposes.
Benefits of a streaming mesh
A streaming mesh can deliver the following benefits:
- Scalability – Organizations can scale from processing thousands to millions of events per second using managed scaling capabilities such as Kinesis Data Streams on-demand, while maintaining transparent operations for both producers and consumers.
- Speed and architectural simplification – Streaming mesh enables real-time data flows, alleviating the need for complex orchestration and extract, transform, and load (ETL) processes. Data is streamed directly from source to consumers as it’s produced, simplifying the overall architecture. This approach replaces intricate point-to-point integrations and scheduled batch jobs with a streamlined, real-time data backbone. For example, instead of running nightly batch jobs to synchronize inventory data of physical goods across regions, a streaming mesh allows for instant inventory updates across all systems as sales occur, significantly reducing architectural complexity and latency.
- Data synchronization – A streaming mesh captures source system changes one time and enables multiple downstream systems to independently process the same data stream. For instance, a single order processing stream can simultaneously update inventory systems, shipping services, and analytics platforms while maintaining replay capability, minimizing redundant integrations and providing data consistency.
The following personas have distinct responsibilities in the context of a streaming mesh:
- Producers – Producers are responsible for generating and emitting data products into the streaming mesh. They have full ownership over the data products they generate and must make sure these data products adhere to predefined data quality and format standards. Additionally, producers are tasked with managing the schema evolution of the streaming data, while also meeting service level agreements for data delivery.
- Consumers – Consumers are responsible for consuming and processing data products from the streaming mesh. They rely on the data products provided by producers to support their applications or analytics needs.
- Governance – Governance is responsible for maintaining both the operational health and security of the streaming mesh platform. This includes managing scalability to handle changing workloads, enforcing data retention policies, and optimizing resource usage for efficiency. They also oversee security and compliance, enforcing proper access control, data encryption, and adherence to regulatory standards.
The streaming mesh establishes a common platform that enables seamless collaboration between producers, consumers, and governance teams. By clearly defining responsibilities and providing self-service capabilities, it removes traditional integration barriers while maintaining security and compliance. This approach helps organizations break down data silos and achieve more efficient, flexible data utilization across the enterprise.A streaming mesh architecture consists of two key constructs: stream storage and the stream processor. Stream storage serves all three key personas—governance, producers, and consumers—by providing a reliable, scalable, on-demand platform for data retention and distribution.
The stream processor is essential for consumers reading and transforming the data. Kinesis Data Streams integrates seamlessly with various processing options. AWS Lambda can read from a Kinesis data stream through event source mapping, which is a Lambda resource that reads items from the stream and invokes a Lambda function with batches of records. Other processing options include the Kinesis Client Library (KCL) for building custom consumer applications, Amazon Managed Service for Apache Flink for complex stream processing at scale, Amazon Data Firehose, and more. To learn more, refer to Read data from Amazon Kinesis Data Streams.
This combination of storage and flexible processing capabilities supports the diverse needs of multiple personas while maintaining operational simplicity.
Common access patterns for building a streaming mesh
When building a streaming mesh, you should consider data ingestion, governance, access control, storage, schema control, and processing. When implementing the components that make up the streaming mesh, you must properly address the needs of the personas defined in the previous section: producer, consumer, and governance. A key consideration in streaming mesh architectures is the fact that producers and consumers can also exist outside of AWS entirely. In this post, we examine the key scenarios illustrated in the following diagram. Although the diagram has been simplified for clarity, it highlights the most important scenarios in a streaming mesh architecture:
- External sharing – This involves producers or consumers outside of AWS
- Internal sharing – This involves producers and consumers within AWS, potentially across different AWS accounts or AWS Regions
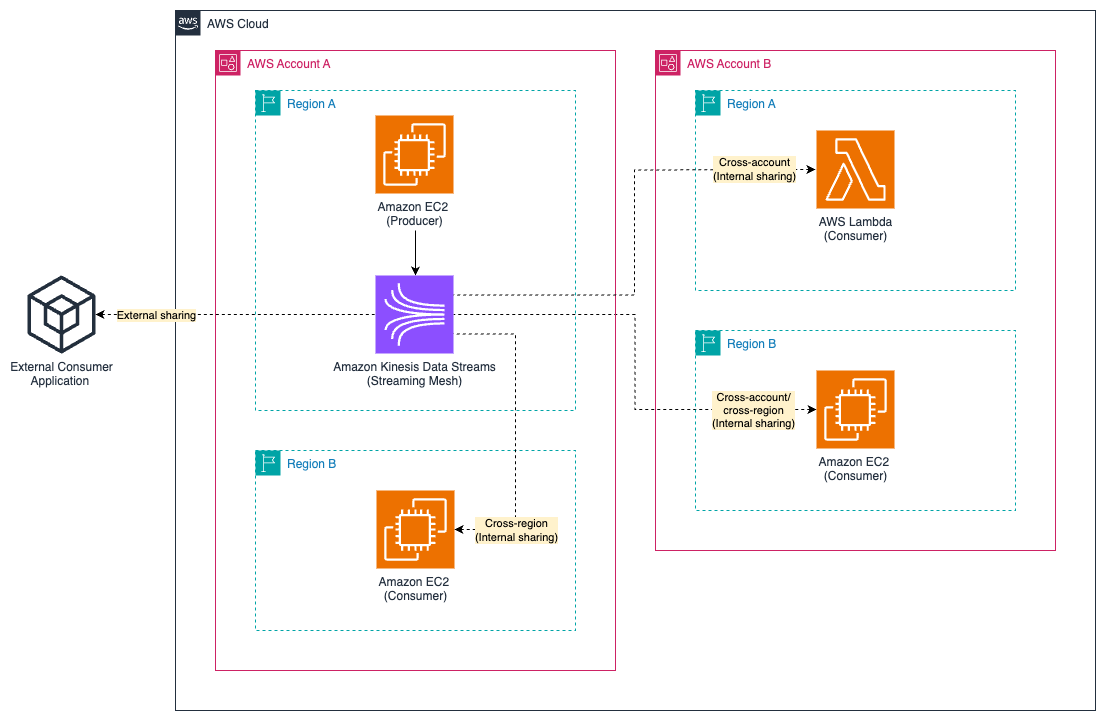
Building a streaming mesh on a self-managed streaming solution that facilitates internal and external sharing can be challenging because producers and consumers require the appropriate service discovery, network connectivity, security, and access control to be able to interact with the mesh. This can involve implementing complex networking solutions such as VPN connections with authentication and authorization mechanisms to support secure connectivity. In addition, you must consider the access pattern of the consumers when building the streaming mesh.The following are common access patterns:
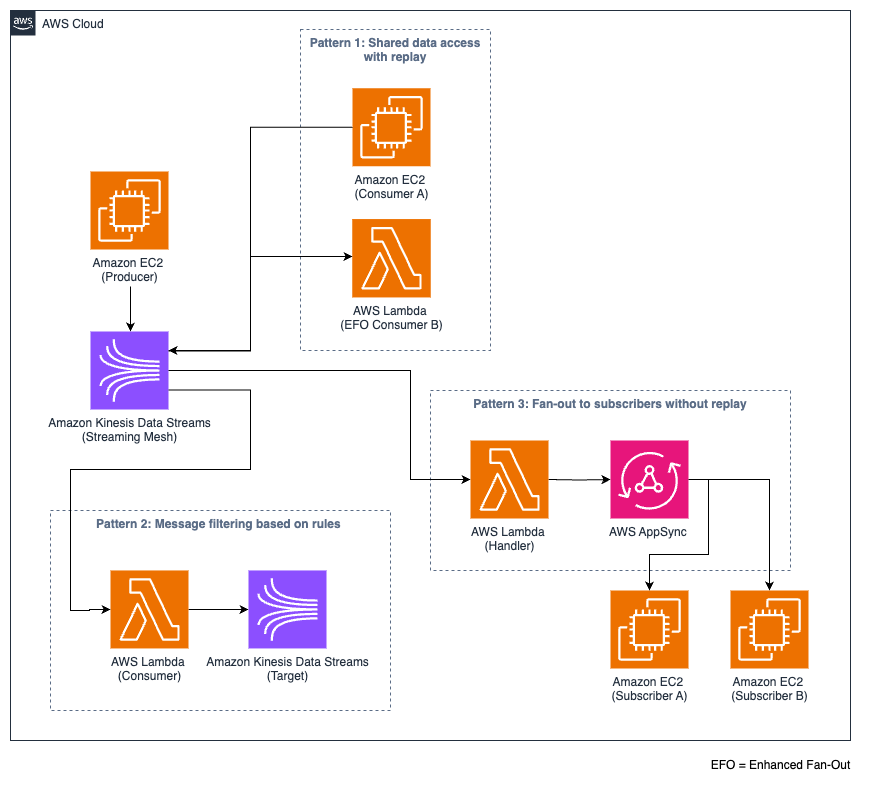
- Shared data access with replay – This pattern allows multiple (standard or enhanced fan-out) consumers to access the same data stream as well as the ability to replay data as needed. For example, a centralized log stream might serve various teams: security operations for threat detection, IT operations for system troubleshooting, or development teams for debugging. Each team can access and replay the same log data for their specific needs.
- Messaging filtering based on rules – In this pattern, you must filter the data stream, and consumers are only reading a subset of the data stream. The filtering is based on predefined rules at the column or row level.
- Fan-out to subscribers without replay – This pattern is designed for real-time distribution of messages to multiple subscribers with each subscriber or consumer. The messages are delivered under at-most-once semantics and can be dropped or deleted after consumption. The subscribers can’t replay the events. The data is consumed by services such as AWS AppSync or other GraphQL-based APIs using WebSockets.
The following diagram illustrates these access patterns.
Build a streaming mesh using Kinesis Data Streams
When building a streaming mesh that involves internal and external sharing, you can use Kinesis Data Streams. This service offers a built-in API layer that deliver secure and highly available HTTP/S endpoints accessible through the Kinesis API. Producers and consumers can securely write and read from the Kinesis Data Streams endpoints using the AWS SDK, the Amazon Kinesis Producer Library (KPL), or Kinesis Client Library (KCL), alleviating the need for custom REST proxies or additional API infrastructure.
Security is inherently integrated through AWS Identity and Access Management (IAM), supporting fine-grained access control that can be centrally managed. You can also use attribute-based access control (ABAC) with stream tags assigned to Kinesis Data Streams resources for managing access control to the streaming mesh, because ABAC is particularly helpful in complex and scaling environments. Because ABAC is attribute-based, it enables dynamic authorization for data producers and consumers in real time, automatically adapting access permissions as organizational and data requirements evolve. In addition, Kinesis Data Streams provides built-in rate limiting, request throttling, and burst handling capabilities.
In the following sections, we revisit the previously mentioned common access patterns for consumers in the context of a streaming mesh and discuss how to build the patterns using Kinesis Data Streams.
Shared data access with replay
Kinesis Data Stream has built-in support for the shared data access with replay pattern. The following diagram illustrates this access pattern, focusing on same-account, cross-account, and external consumers.
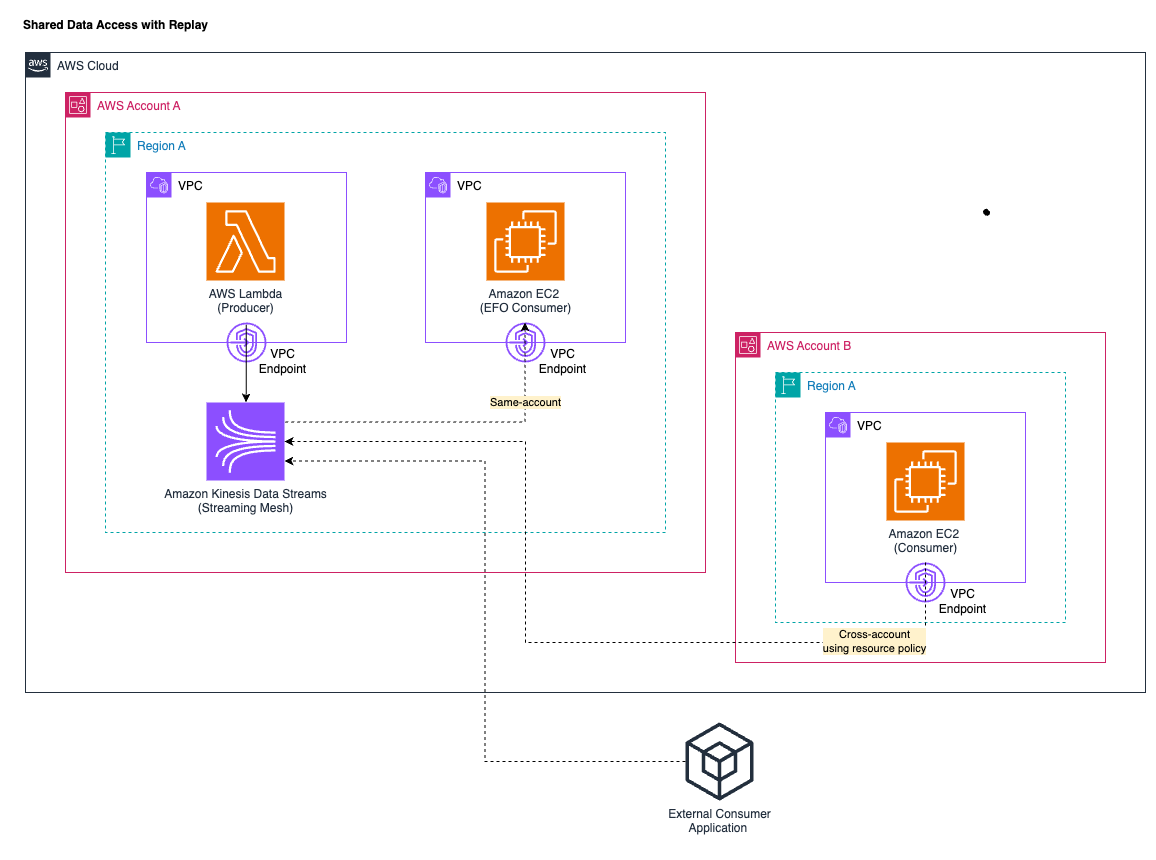
Governance
When you create your data mesh with Kinesis Data Streams, you should create a data stream with the appropriate number of provisioned shards or on-demand mode based on your throughput needs. On-demand mode should be considered for more dynamic workloads. Note that message ordering can only be guaranteed at the shard level.
Configure the data retention period of up to 365 days. The default retention period is 24 hours and can be modified using the Kinesis Data Streams API. This way, the data is retained for the specified retention period and can be replayed by the consumers. Note that there is an additional fee for long-term data retention fee beyond the default 24 hours.
To enhance network security, you can use interface VPC endpoints. They make sure the traffic between your producers and consumers residing in your virtual private cloud (VPC) and your Kinesis data streams remain private and don’t traverse the internet. To provide cross-account access to your Kinesis data stream, you can use resource policies or cross-account IAM roles. Resource-based policies are directly attached to the resource that you want to share access to, such as the Kinesis data stream, and a cross-account IAM role in one AWS account delegates specific permissions, such as read access to the Kinesis data stream, to another AWS account. At the time of writing, Kinesis Data Streams doesn’t support cross-Region access.
Kinesis Data Streams enforces quotas at the shard and stream level to prevent resource exhaustion and maintain consistent performance. Combined with shard-level Amazon CloudWatch metrics, these quotas help identify hot shards and prevent noisy neighbor scenarios that could impact overall stream performance.
Producer
You can build producer applications using the AWS SDK or the KPL. Using the KPL can facilitate the writing because it provides built-in functions such as aggregation, retry mechanisms, pre-shard rate limiting, and increased throughput. The KPL can incur an additional processing delay. You should consider integrating Kinesis Data Streams with the AWS Glue Schema Registry to centrally control discover, control, and evolve schemas and make sure produced data is continuously validated by a registered schema.
You must make sure your producers can securely connect to the Kinesis API whether from inside or outside the AWS Cloud. Your producer can potentially live in the same AWS account, across accounts, or outside of AWS entirely. Typically, you want your producers to be as close as possible to the Region where your Kinesis data stream is running to minimize latency. You can enable cross-account access by attaching a resource-based policy to your Kinesis data stream that grants producers in other AWS accounts permission to write data. At the time of writing, the KPL doesn’t support specifying a stream Amazon Resource Name (ARN) when writing to a data stream. You must use the AWS SDK to write to a cross-account data stream (for more details, see Share your data stream with another account). There are also limitations for cross-Region support if you want to produce data to Kinesis Data Streams from Data Firehose in a different Region using the direct integration.
To securely access the Kinesis data stream, producers need valid credentials. Credentials should not be stored directly in the client application. Instead, you should use IAM roles to provide temporary credentials using the AssumeRole API through AWS Security Token Service (AWS STS). For producers outside of AWS, you can also consider AWS IAM Roles Anywhere to obtain temporary credentials in IAM. Importantly, only the minimum permissions that are required to write the stream should be granted. With ABAC support for Kinesis Data Streams, specific API actions can be allowed or denied when the tag on the data stream matches the tag defined in the IAM role principle.
Consumer
You can build consumers using the KCL or AWS SDK. The KCL can simplify reading from Kinesis data streams because it automatically handles complex tasks such as checkpointing and load balancing across multiple consumers. This shared access pattern can be implemented using standard as well as enhanced fan-out consumers. In the standard consumption mode, the read throughput is shared by all consumers reading from the same shard. The maximum throughput for each shard is 2 MBps. Records are delivered to the consumers in a pull model over HTTP using the GetRecords API. Alternatively, with enhanced fan-out, consumers can use the SubscribeToShard API with data pushed over HTTP/2 for lower-latency delivery. For more details, see Develop enhanced fan-out consumers with dedicated throughput.
Both consumption methods allow consumers to specify the shard and sequence number from which to start reading, enabling data replay from different points within the retention period. Kinesis Data Streams recommends to be aware of the shard limit that is shared and use fan-out when possible. KCL 2.0 or later uses enhanced fan-out by default, and you must specifically set the retrieval mode to POLLING to use the standard consumption model. Regarding connectivity and access control, you should closely follow what is already suggested for the producer side.
Messaging filtering based on rules
Although Kinesis Data Streams doesn’t provide built-in filtering capabilities, you can implement this pattern by combining it with Lambda or Managed Service for Apache Flink. For this post, we focus on using Lambda to filter messages.
Governance and producer
Governance and producer personas should follow the best practices already defined for the shared data access with replay pattern, as described in the previous section.
Consumer
You should create a Lambda function that consumes (shared throughput or dedicated throughput) from the stream and create a Lambda event source mapping with your filter criteria. At the time of writing, Lambda supports event source mappings for Amazon DynamoDB, Kinesis Data Streams, Amazon MQ, Managed Streaming for Apache Kafka or self-managed Kafka, and Amazon Simple Queue Service (Amazon SQS). Both the ingested data records and your filter criteria for the data field must be in a valid JSON format for Lambda to properly filter the incoming messages from Kinesis sources.
When using enhanced fan-out, you configure a Kinesis dedicated-throughput consumer to act as the trigger for your Lambda function. Lambda then filters the (aggregated) records and passes only those records that meet your filter criteria.
Fan-out to subscribers without replay
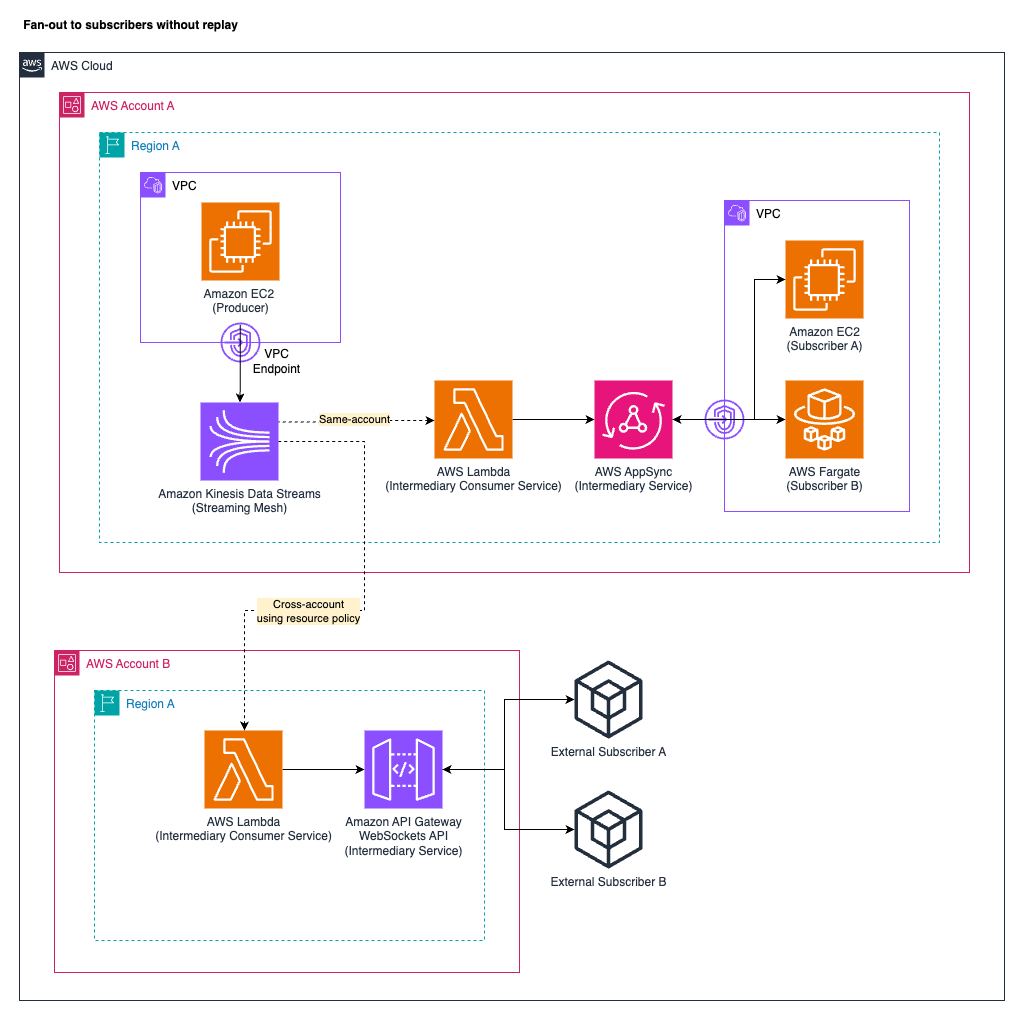
When distributing streaming data to multiple subscribers without the ability to replay, Kinesis Data Streams supports an intermediary pattern that’s particularly effective for web and mobile clients needing real-time updates. This pattern introduces an intermediary service to bridge between Kinesis Data Streams and the subscribers, processing records from the data stream (using a standard or enhanced fan-out consumer model) and delivering the data records to the subscribers in real time. Subscribers don’t directly interact with the Kinesis API.
A common approach uses GraphQL gateways such as AWS AppSync, WebSockets API services like the Amazon API Gateway WebSockets API, or other suitable services that make the data available to the subscribers. The data is distributed to the subscribers through networking connections such as WebSockets.
The following diagram illustrates the access pattern of fan-out to subscribers without replay. The diagram displays the managed AWS services AppSync and API Gateway as intermediary consumer options for illustration purposes.
Governance and producer
Governance and producer personas should follow the best practices already defined for the shared data access with replay pattern.
Consumer
This consumption model operates differently from traditional Kinesis consumption patterns. Subscribers connect through networking connections such as WebSockets to the intermediary service and receive the data records in real time without the ability to set offsets, replay historical data, or control data positioning. The delivery follows at-most-once semantics, where messages might be lost if subscribers disconnect, because consumption is ephemeral without persistence for individual subscribers. The intermediary consumer service must be designed for high performance, low latency, and resilient message distribution. Potential intermediary service implementations range from managed services such as AppSync or API Gateway to custom-built solutions like WebSocket servers or GraphQL subscription services. In addition, this pattern requires an intermediary consumer service such as Lambda that reads the data from the Kinesis data stream and immediately writes it to the intermediary service.
Conclusion
This post highlighted the benefits of a streaming mesh. We demonstrated why Kinesis Data Streams is particularly suited to facilitate a secure and scalable streaming mesh architecture for internal as well as external sharing. The reasons include the service’s built-in API layer, comprehensive security through IAM, flexible networking connection options, and versatile consumption models. The streaming mesh patterns demonstrated—shared data access with replay, message filtering, and fan-out to subscribers—showcase how Kinesis Data Streams effectively supports producers, consumers, and governance teams across internal and external boundaries.
For more information on how to get started with Kinesis Data Streams, refer to Getting started with Amazon Kinesis Data Streams. For other posts on Kinesis Data Streams, browse through the AWS Big Data Blog.