AWS Big Data Blog
Accelerating development with the AWS Data Processing MCP Server and Agent
Data engineering teams face an increasingly complex landscape when building and maintaining analytics environments. From sourcing and organizing data to implementing transformation pipelines and managing access controls, the process of transforming raw data into actionable insights involves numerous interconnected components. While individual tools exist for each task, connecting them into cohesive workflows remains time-consuming and requires deep technical expertise across multiple AWS services.
To address these challenges and enhance developer productivity, we’re excited to introduce the AWS Data Processing MCP Server, an open-source tool that uses the Model Context Protocol (MCP) to simplify analytics environment setup on AWS. We’re also open sourcing a stand-alone Data Processing Agent implementation in AWS Strands SDK to use this MCP server to help customers further customize it for their use cases. This powerful integration enables AI assistants to understand your data processing environment and guide you through complex workflows using natural language interactions.
Understanding the Model Context Protocol advantage
The MCP is an emerging open standard that defines how AI models, particularly large language models (LLMs), can securely access and interact with external tools, data sources, and services. Rather than requiring developers to learn intricate API syntax across multiple services, MCP enables AI assistants to understand your environment contextually and provide intelligent guidance throughout your data processing journey.
The AWS Data Processing MCP Server harnesses this capability by providing AI code assistants with real-time visibility into your AWS data processing pipeline. This includes access to AWS Glue job statuses, Amazon Athena query results, Amazon EMR cluster metrics, and AWS Glue Data Catalog metadata through a unified interface that LLMs can understand and reason about.
AWS analytics integration
The AWS Data Processing MCP Server integrates deeply with AWS Glue for data cataloging and ETL operations, Amazon EMR for big data processing, and Athena for serverless analytics. This integration transforms how developers interact with these services by providing contextual awareness that enables AI assistants and Data Processing Strands Agent to make intelligent recommendations based on your actual infrastructure and data patterns.
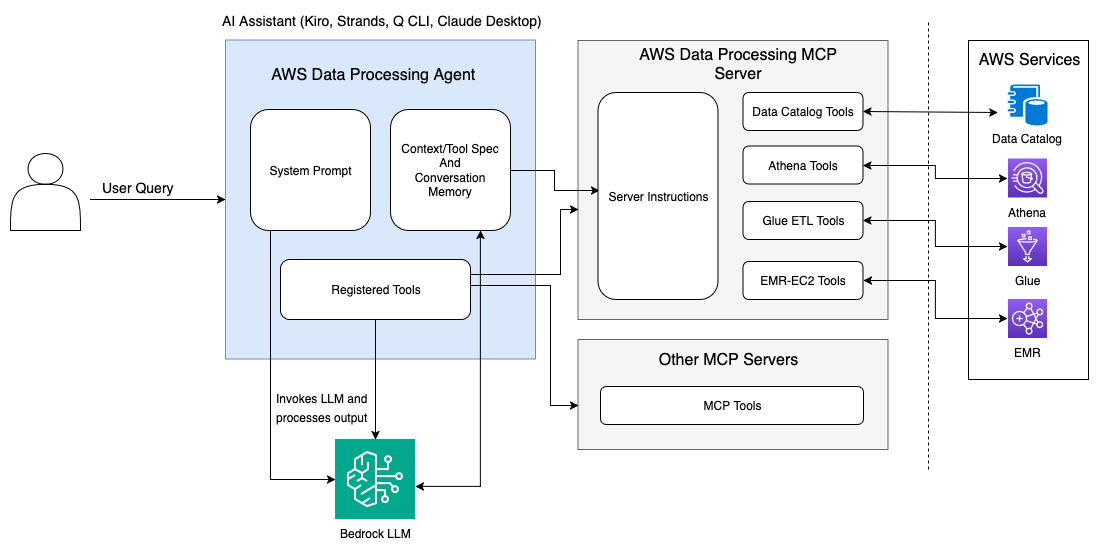
Rather than requiring manual navigation between service consoles or memorizing complex API parameters, the MCP server enables natural language interactions that automatically translate to appropriate service operations. This approach reduces the learning curve for new team members while accelerating productivity for experienced developers working across multiple AWS analytics services.
Getting started with the AWS Data Processing MCP Server
You’ll need to follow the steps in the prerequisites section before you can start using MCP servers.
Prerequisites
Before configuring the MCP server, ensure you have the following prerequisites in place:
System requirements:
- macOS or supported Linux environment
- Python 3.10 or higher
- UV package manager for Python dependency management
- AWS Command Line Interface (AWS CLI) installed and configured with appropriate credentials
IAM permissions: Review and configure your security policies for the IAM roles and permissions that would grant necessary access to the AWS Data Processing MCP Server and Agent to execute AWS data processing operations on your behalf. For read-only operations, attach policies that include permissions for Data Catalog access, Amazon CloudWatch metrics, Amazon EMR cluster descriptions, and Athena query operations. For write operations, make sure that your AWS Identity and Access Management (IAM) role includes the AWSGlueServiceRole managed policy along with permissions for creating and managing Amazon EMR clusters and Athena workgroups.
Set up using Amazon Q CLI
Amazon Q Developer CLI provides an intuitive way to interact with the AWS Data Processing MCP Server directly from your terminal. This integration combines the natural language processing capabilities of Amazon Q with the data processing tools, enabling you to manage complex analytics workflows through conversational commands.
Installation and configuration:
- Install the Amazon Q Developer CLI.
- Clone the MCP Server repository:
git clone https://github.com/awslabs/mcp
- Edit your Q Developer CLI’s MCP configuration file named
mcp.json:
- Verify your setup by running the /tools command in the Q Developer CLI to see the available Data Processing MCP tools.
Set up using Claude Desktop
Claude Desktop offers another powerful way to interact with the AWS Data Processing MCP Server through Anthropic’s Claude interface, providing a user-friendly chat experience for managing your data processing workflows.
Installation and configuration:
- Download and install Claude Desktop for your operating system.
- Open Claude Desktop and navigate to Settings (gear icon in the bottom left).
- Go to the Developer tab and configure your MCP server by adding same configuration as step 3 in Q CLI setup.
- Restart Claude Desktop to activate the MCP server connection.
- Test the integration by starting a new conversation and asking:
What data processing tools are available to me?
Enhanced developer experience
After being configured with either Amazon Q CLI or Claude Desktop, your workflow transforms dramatically. Instead of constructing complex AWS CLI commands with multiple parameters, you can use natural language requests. For example, rather than memorizing the syntax for creating AWS Glue crawlers, you can ask:
Accelerating development with MCP servers
Next, we explore the common patterns that emerge when using MCP in data processing development workflows.
Data onboarding and discovery
One of the most common challenges data teams face is efficiently onboarding new datasets and making them immediately useful for analysis. Consider a scenario where your marketing team receives a CSV file containing customer interaction data that needs to be quickly analyzed for campaign insights. Traditionally, this process involves multiple manual steps: uploading the file to Amazon Simple Storage Service (Amazon S3), configuring an AWS Glue crawler to discover the schema, creating appropriate table definitions, setting up proper partitioning, and finally making the data queriable through Athena.
With the AWS Data Processing MCP Server, this entire workflow becomes conversational. You can describe your goal using natural language:
The AI assistant, powered by the MCP server’s deep AWS integration, automatically handles the technical implementation details, guides you through uploading the file to an appropriate Amazon S3 location, configures and runs an AWS Glue crawler with optimal settings, creates properly formatted table definitions, and sets up Athena access with appropriate workgroup configurations for cost control.
The following video demonstration showcases how developers can use Amazon Q CLI with Data Processing MCP server for data onboarding.
Business insights and automated reporting
Modern organizations require timely, accurate insights to drive business decisions, but traditional analytics workflows often create bottlenecks between data availability and business consumption. Imagine you need to identify potentially fraudulent transactions across multiple data sources including cardholder information, credit card details, merchant data, and transaction records. Rather than manually writing complex SQL queries with multiple joins and filters, you can describe your analytical goal:
The MCP server interprets this request and automatically constructs the appropriate analytical workflow. It examines your data catalog to understand table relationships, generates optimized SQL queries with proper joins across your datasets, executes the analysis using Athena with cost-effective query patterns, and formats the results into actionable reports. The system can establish automated delivery mechanisms, such as email reports or dashboard updates, ensuring stakeholders receive timely insights without manual intervention while creating scheduled AWS Glue jobs that continuously monitor for emerging patterns.
We’re also releasing a stand-alone Data Processing Agent developed using AWS Strands SDK that you can customize further with your system prompts and context for your use cases. You can run it locally or deploy it using Amazon Bedrock AgentCore. The following video demonstration showcases how developers can use Data Processing Agent for driving business insights.
Observability and performance monitoring
Maintaining visibility across complex data processing environments requires sophisticated monitoring capabilities that traditional approaches often fail to provide. The AWS Data Processing MCP Server enables intelligent observability by synthesizing real-time telemetry from across your AWS analytics infrastructure into actionable insights. For AWS Glue environments, the MCP server continuously analyzes job metadata, execution logs, resource configurations, and data catalog statistics to provide operational intelligence. Rather than manually navigating CloudWatch dashboards or parsing log files, you can ask questions like Show me performance trends across my ETL jobs and identify optimization opportunities. The following video demonstration showcases how developers can use Claude Desktop with Data Processing MCP Server to monitor Glue jobs and catalogs.
For Amazon EMR clusters, the MCP server aggregates cluster metadata, instance usage patterns, and failure events into unified operational views. This enables proactive management where you can request Analyze my EMR environment for cost optimization opportunities and potential reliability risks. The system responds with detailed analysis of cluster utilization patterns, recommendations for right-sizing instance types, identification of long-running clusters that might represent cost leakage, and alerts about configuration patterns that could impact reliability. The observability capabilities extend beyond simple monitoring to predictive insights by analyzing historical patterns to forecasting resource needs and recommend preventive actions. The following video demonstration showcases how developers can use Claude Desktop with Data Processing MCP Server to monitor EMR clusters.
Security and architectural considerations
All MCP server operations occur within your AWS account boundaries, helping to ensure that sensitive data does not leave your controlled environment. The server provides contextual information to AI assistants through metadata and API responses based on IAM access permissions available to the role being used. Integration with IAM helps ensure that operations respect existing permission boundaries and organizational policies.
The architecture supports graduated autonomy where routine operations can proceed automatically while high-impact changes require human approval. This balanced approach enables productivity gains while maintaining appropriate oversight for critical business operations.
Conclusion
In this post, we explored how the AWS Data Processing MCP Server accelerates analytics solution development across our analytics services. We demonstrated how data engineers can transform raw data into business-ready insights through AI-assisted workflows, significantly reducing development time and complexity. The AWS Data Processing MCP Server offers extensive capabilities beyond these use cases. You can use the MCP’s context-rich APIs to develop customized solutions for observability, automation, and optimization. This flexibility allows you to create workflows tailored to your specific data environments and business needs.By bringing AWS data processing capabilities directly into development workflows—whether through AWS CLI, IDEs, or AI-assisted tools—teams can focus on solving business problems rather than managing infrastructure. We encourage you to explore innovative applications of the MCP Server, combining its powerful context engine with AI-driven analysis to uncover new opportunities for efficiency and insight across their data ecosystems.
Get started today by accessing the open source code, documentation, and setup instructions in the AWS Labs GitHub repository. Integrate the MCP Server into your development workflow and transform how you build analytics solutions on AWS. We’ll continue to iterate based on customer feedback and look forward to seeing how customers extend these capabilities to solve complex data challenges.
Acknowledgment: A special thanks to everyone who contributed to the development and open-sourcing of the AWS Data Processing MCP server and Agent: Raghavendhar Thiruvoipadi Vidyasagar, Chris Kha, Sandeep Adwankar, Nidhi Gupta, Xiaoxi Liu, Kathryn Lin, Alexa Perlov, Alain Krok, Xiaorun Yu, Maheedhar Reddy Chapiddi, and Rajendra Gujja.
About the authors
 Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
 Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies.
Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies.
 Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively.
Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively.
 Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
 Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI.
Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI.
 Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI.
Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI.
 Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.