AWS Big Data Blog
Accelerate AWS Glue zero-ETL data ingestion using Salesforce Bulk API
Efficiently integrating and analyzing Salesforce data is essential in today’s business environment. AWS Glue zero ETL (extract, transform, and load) now supports Salesforce Bulk API, delivering substantial performance gains compared to Salesforce REST API for large-scale data integration for targets such as Amazon SageMaker lakehouse and Amazon Redshift. You can use this enhancement to process millions of Salesforce records in minutes while efficiently handling wide-column entities with hundreds of fields. In this blog post, we show you how to use zero-ETL powered by AWS Glue with Salesforce Bulk API to accelerate your data integration processes.
Zero-ETL represents a modern approach to data integration that eliminates the need for traditional ETL processes by establishing direct connections between data sources and destinations. Rather than explicitly extracting data, transforming it, and loading it in separate steps, zero-ETL handles these operations in the background. Zero-ETL enables direct integration with software as a service (SaaS) applications like Salesforce, automatically synchronizing data while maintaining consistency and eliminating the complexity of manual ETL pipeline development. This approach reduces development time, maintenance overhead, and the potential for errors in data movement processes.
Solution overview
Traditionally, zero-ETL used Salesforce REST API for data ingestion. While the REST API provides a straightforward way to interact with Salesforce data, it comes with certain limitations, especially when dealing with large datasets. These include request limits, data volume constraints, performance overhead, and concurrency limitations. As of August 2025, depending on the Salesforce edition and license type, you might be limited to between 15,000 and 100,000 API calls per 24-hour period. When retrieving large volumes of data, multiple API calls are required, leading to inefficiency and extended processing times.
To address these limitations and enhance performance, AWS Glue zero-ETL now supports Salesforce Bulk API. The Bulk API is designed for processing large datasets, offering several advantages over the REST API. It uses asynchronous processing, so you can process much larger data volumes without timing out. Data is processed in batches, which can be parallelized for faster processing. As of August 2025, the Bulk API also has more generous limits; up to 150,000,000 API calls, which is 15,000 batches, per 24-hour period, with each batch containing up to 10,000 records. The following diagram shows a Salesforce zero-ETL architecture ingesting data through Salesforce Bulk and REST APIs and writing to Amazon SageMaker Lakehouse (in Amazon Simple Storage Service (Amazon S3) or Apache Iceberg) or Amazon Redshift.
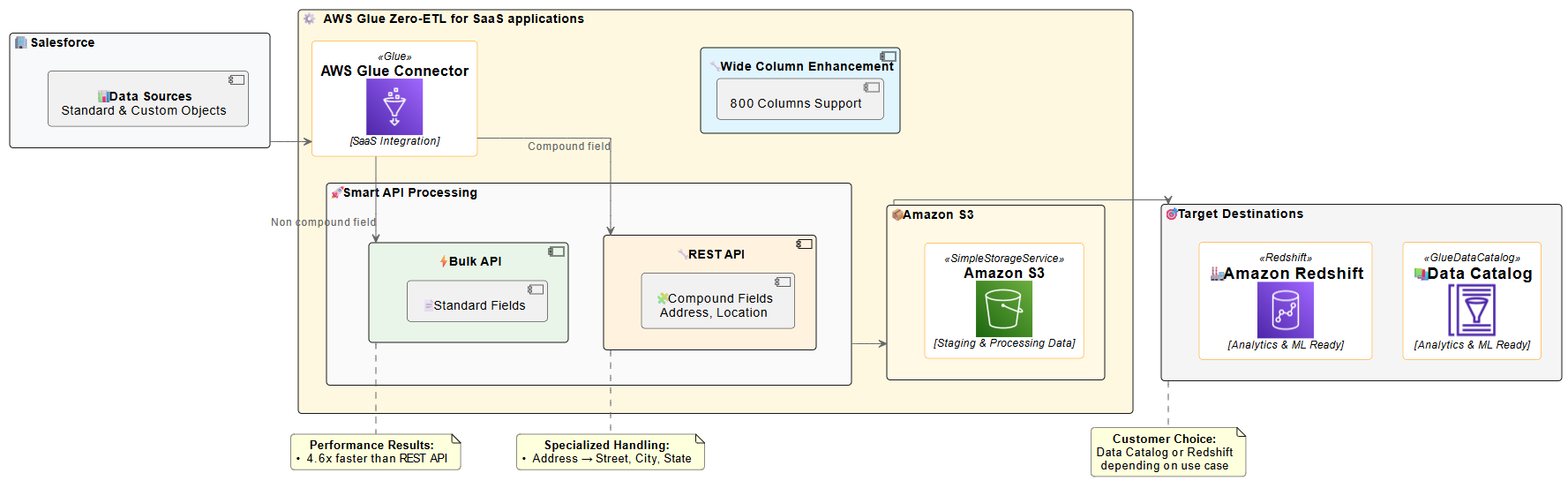
The diagram illustrates the zero-ETL data flow from Salesforce to AWS analytics services. Salesforce data is ingested using smart API processing, which intelligently selects between Bulk API for standard fields and REST API for compound fields. This approach is necessary because, as of now, the Salesforce Bulk API does not support compound fields (such as Address). Therefore, you must use the REST API in such cases for comprehensive data extraction. The solution supports Salesforce wide-column entities containing up to 800 fields, enabling comprehensive data integration. The processed data is then staged in an S3 bucket owned by the service team before being made available in the AWS Glue Data Catalog or Amazon Redshift, ready for analytics and machine learning applications.
AWS Glue zero-ETL now uses the Salesforce Bulk API by default for most data integration scenarios, delivering superior performance and scalability. This approach optimizes data extraction for most use cases, particularly when dealing with large datasets. However, the solution automatically switches to the REST API when handling compound fields. Compound fields, such as addresses (which include street, city, state, postal code, and country), are automatically processed using the REST API.This intelligent API selection provides efficient processing while maintaining the performance benefits of the Bulk API for standard data extraction. This hybrid approach provides the best of both worlds: the scalability and throughput of the Bulk API for most operations, with the specialized handling capabilities of the REST API where it makes the most sense. The system handles this switch automatically, so you don’t need to worry about which API to use for different scenarios.
Performance details
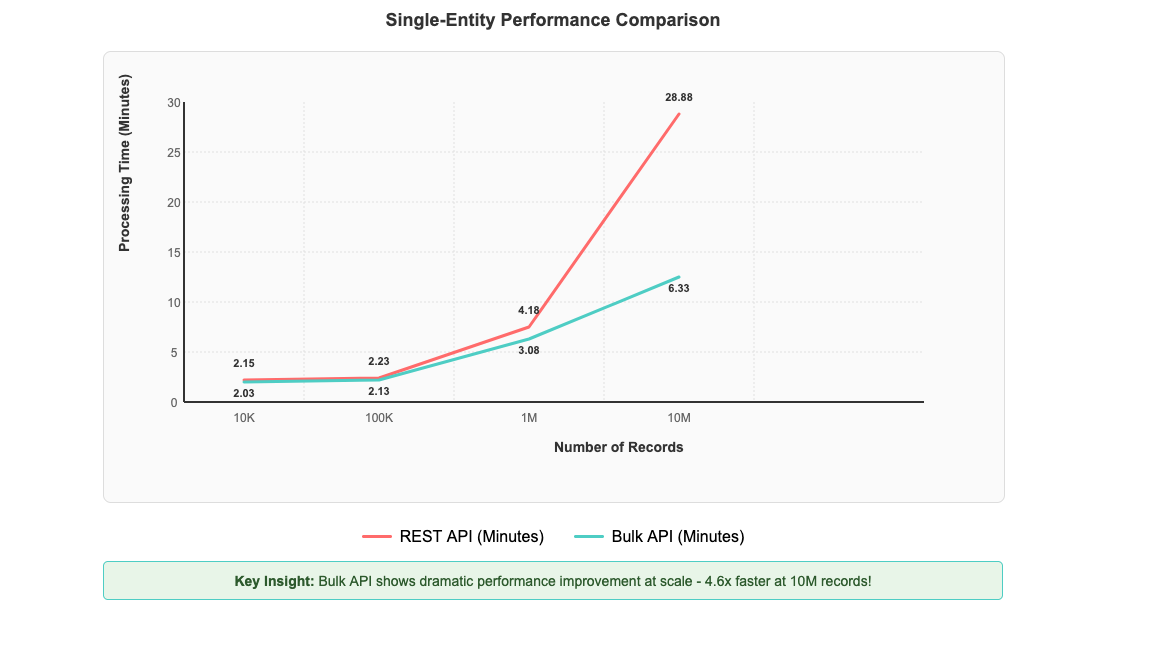
After implementing Salesforce Bulk API support in AWS Glue zero-ETL, you can see significant performance improvements that scale dramatically with data volume. To test performance benefits, we created a custom object in our Salesforce account and populated it with 10 million records. We then established a zero-ETL integration between Salesforce and AWS Glue databases to measure data transfer performance. The most impressive gains are evident with large-scale operations: processing 10 million records now completes in 6 minutes and 20 seconds compared to 28 minutes and 53 seconds with the REST API—representing a 4.6-fold improvement in processing time in our controlled testing environment, as shown in the following figure. Performance improvements can vary depending on factors such as data volume, field complexity, network conditions, and computational resources.
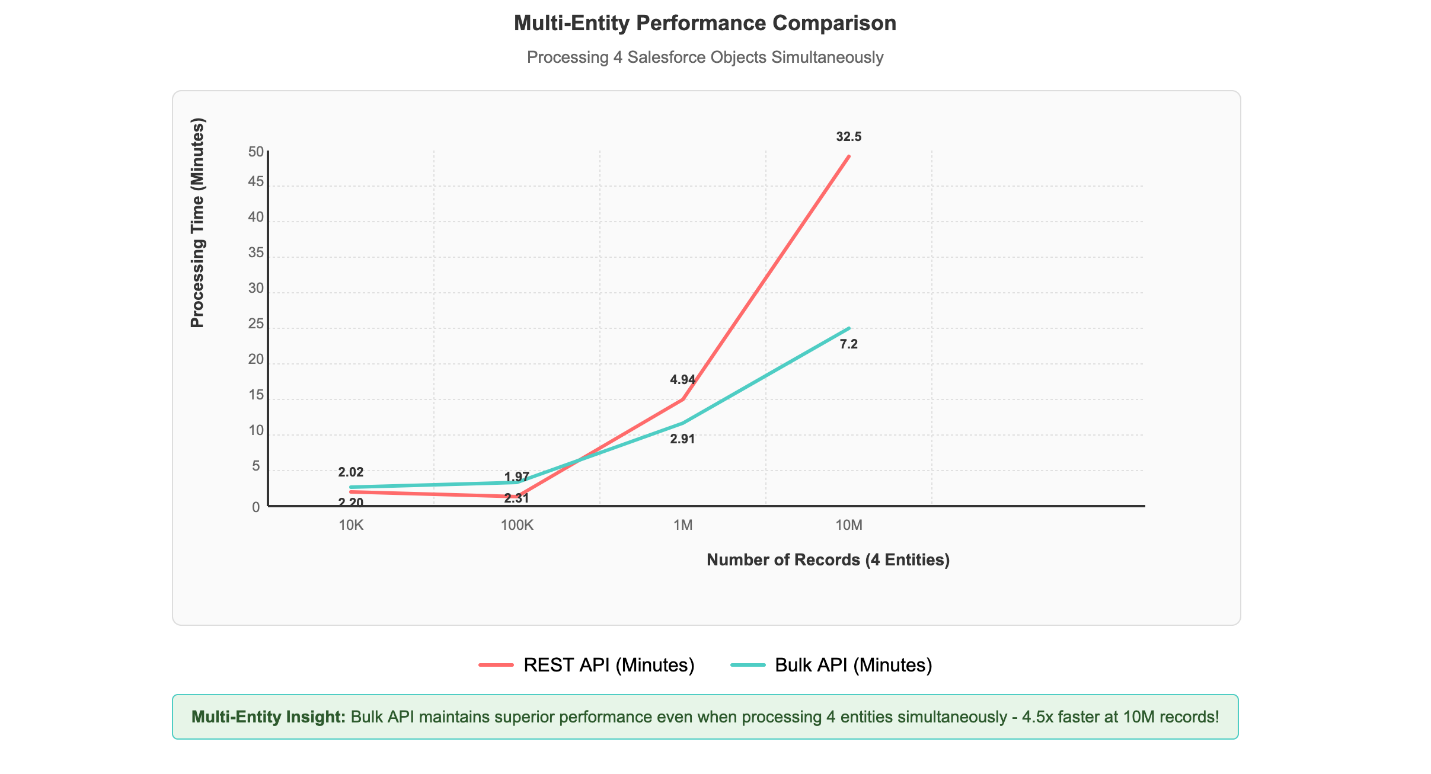
Multi-entity processing scenarios, where four different Salesforce objects are processed simultaneously, demonstrate the solution’s scalability. Even with this concurrent load, 1 million records across multiple entities complete processing in under 3 minutes, showcasing the Bulk API’s superior handling of real-world data integration scenarios, as shown in the following figure.
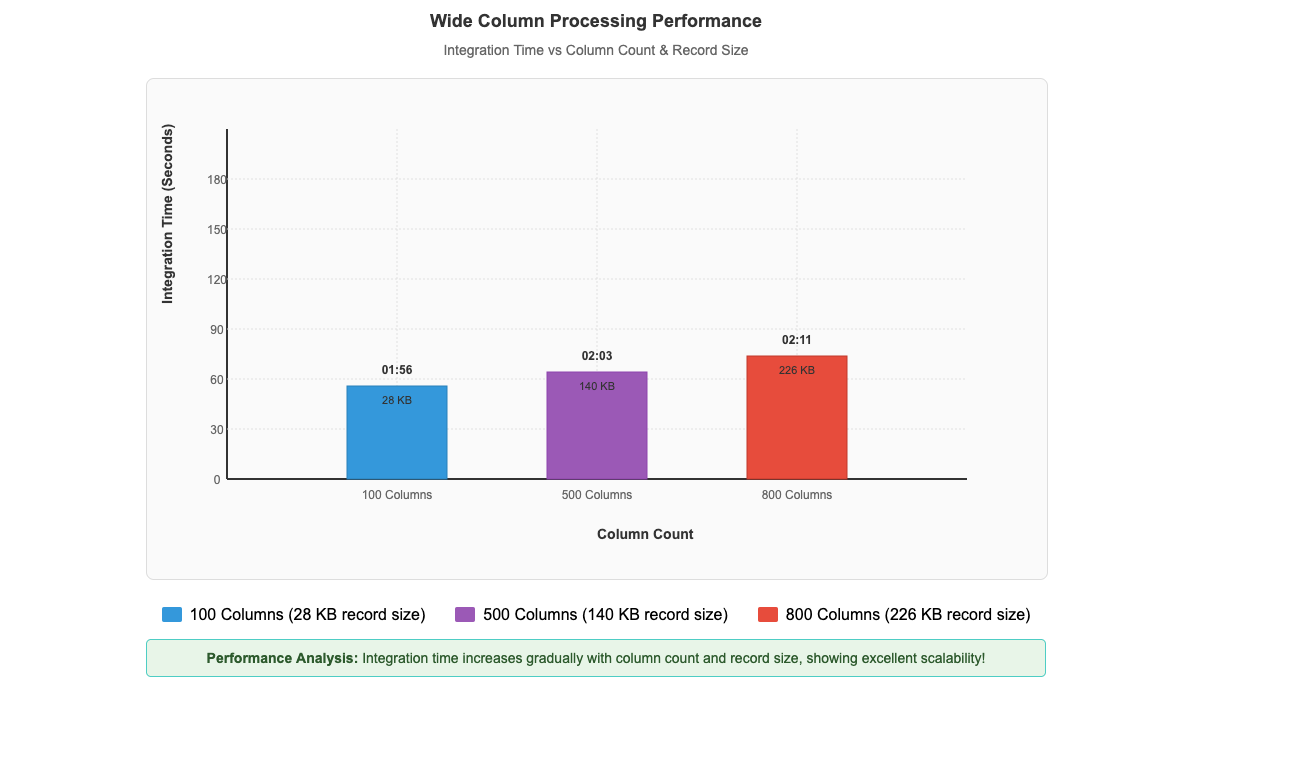
This performance pattern demonstrates that the Bulk API’s asynchronous, batch-oriented architecture delivers exceptional results when handling the large-scale data volumes that enterprises typically encounter in production Salesforce integrations. The performance advantage scales directly with data volume, making it particularly valuable for organizations processing millions of records in their daily operations. As dataset size increases, the efficiency gains become increasingly pronounced, establishing the Bulk API as the optimal choice for enterprise-scale data processing requirements.Beyond the impressive performance gains with large datasets, our recent enhancements have also unlocked another critical capability: efficient processing of wide-column entities. Our performance benchmarks demonstrate this capability in action, with custom objects containing up to 800 columns and 226 KB record sizes processing in just 2 minutes and 11 seconds, while entities with 500 columns and 140 KB records complete in 2 minutes and 3 seconds, and 100-column entities with 28 KB records process in 1 minute and 56 seconds (shown in the following figure). This remarkable consistency across varying column counts and record sizes demonstrates that zero-ETL from SaaS applications maintains excellent performance while efficiently ingesting and processing these wide-column entities, which means that you can use your complete Salesforce datasets for analytics and machine learning initiatives.
Impact
The performance improvements, demonstrated by AWS Glue zero-ETL with Salesforce Bulk API support, offer tangible benefits for businesses managing large volumes of Salesforce data. As mentioned earlier, our controlled testing, demonstrated a 4.6-fold improvement over the REST API when processing 10 million records. With these results, you can significantly reduce your data integration time windows. This faster processing allows for more frequent data updates, potentially enabling you to work with fresher data for your analytics and reporting needs. Additionally, the efficient handling of wide-column entities, such as processing custom objects with up to 800 columns in just over 2 minutes, means that you can more readily use your complete Salesforce datasets without sacrificing performance.
Prerequisites
Before implementing this solution, you need to have the following in place:
- A Salesforce Enterprise, Unlimited, or Performance Edition account
- An AWS account with administrator access
- Create an AWS Glue database with a name such as
zero_etl_bulk_demo_dband associate the S3 bucketzeroetl-etl-bulk-demo-bucketas a location of the database. - Update AWS Glue Data Catalog settings using the following IAM policy for fine-grained access control of the data catalog for zero-ETL.
- Create an AWS Identity and Access Management (IAM) role named
zero_etl_bulk_role. The IAM role will be used by zero-ETL to access data from your Saleforce account - Create the secret
zero_etl_bulk_demo_secretin AWS Secrets Manager to store Salesforce credentials.
Build and verify the zero-ETL integration
This section covers the steps required to set up a Salesforce connection and using that connection to create a zero-ETL integration.
Step 1: Set up a connector to your Salesforce instance to enable data access
- Open the AWS Management Console for AWS Glue.
- In the navigation pane, under Data catalog, choose Connections.
- Choose Create Connection.
- In the Create Connection pane, enter
Salesforcein Data Sources. - Choose Salesforce.
- Choose Next.
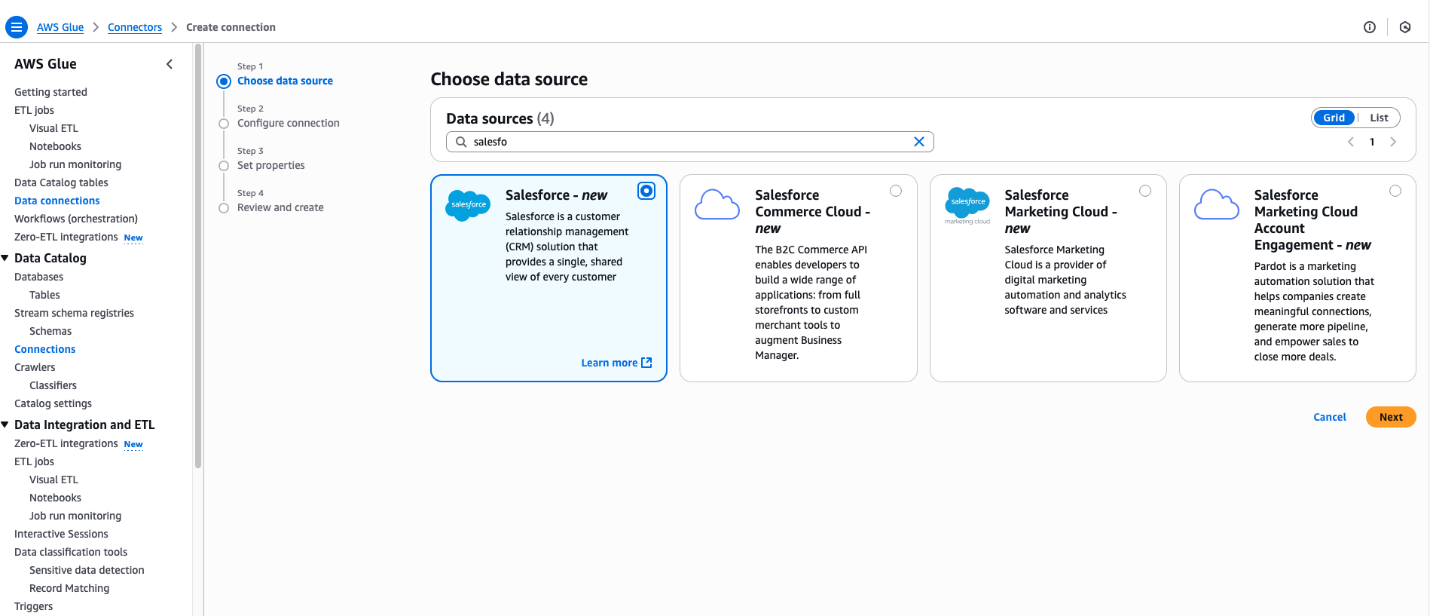
- Enter the Salesforce URL Instance URL
- For IAM service role, select the zero_etl_bulk_demo_role (created as part of the prerequisites).
- For Authentication Type, select the authentication type that you’re using for Salesforce. In this example, we selected Authorization Code.
- For AWS Secret, select the secret zero_etl_bulk_demo_secret (created as part of the prerequisites).
- Choose Next.
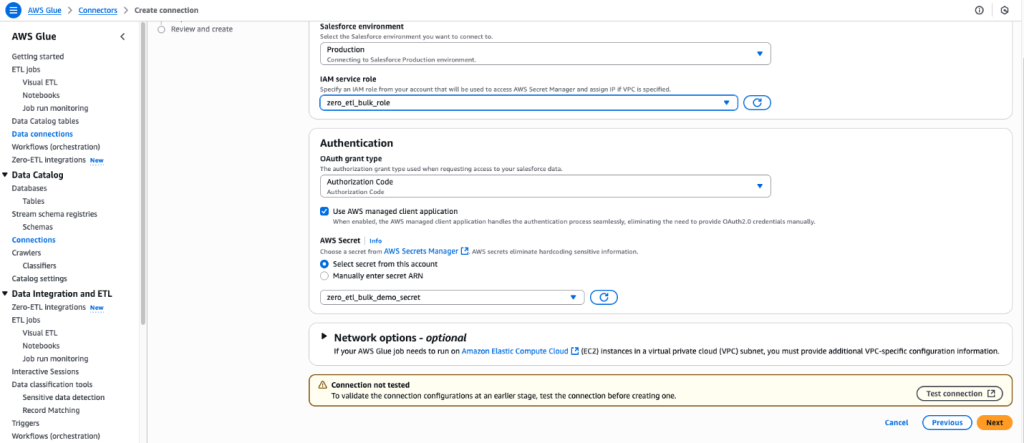
- In the Connection Properties section, for Name, enter
zero_etl_bulk_demo_conn. - Choose Next.

Step 2: Set up zero-ETL integration
- Open the AWS Glue console.
- In the navigation pane, under Data catalog, choose zero-ETL integrations.
- Choose Create zero-ETL integration.
- In the Create integration pane, enter
Salesforcein Data Sources. - Choose Salesforce.
- Choose Next.
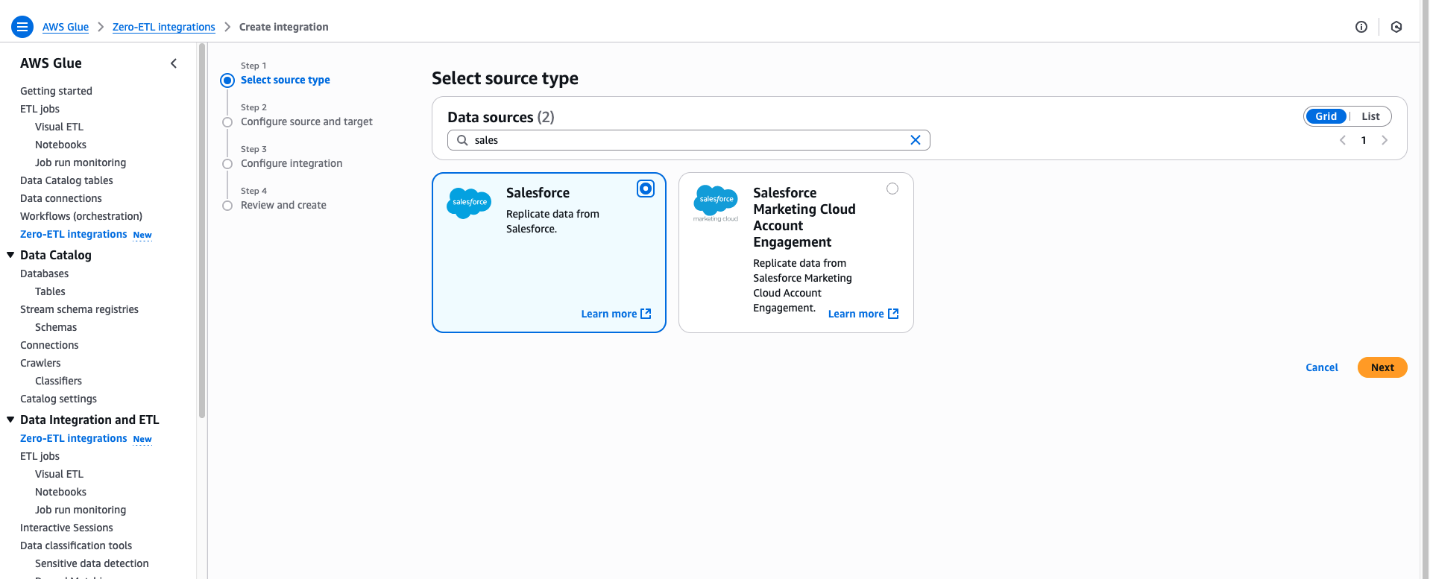
- Select the connection name that you created in the previous step.
- Select the IAM role which you created in the previous step.
- For Salesforce object, select the objects you want to perform the ingestion managed by zero-ETL integration. For this post, select Opportunity.
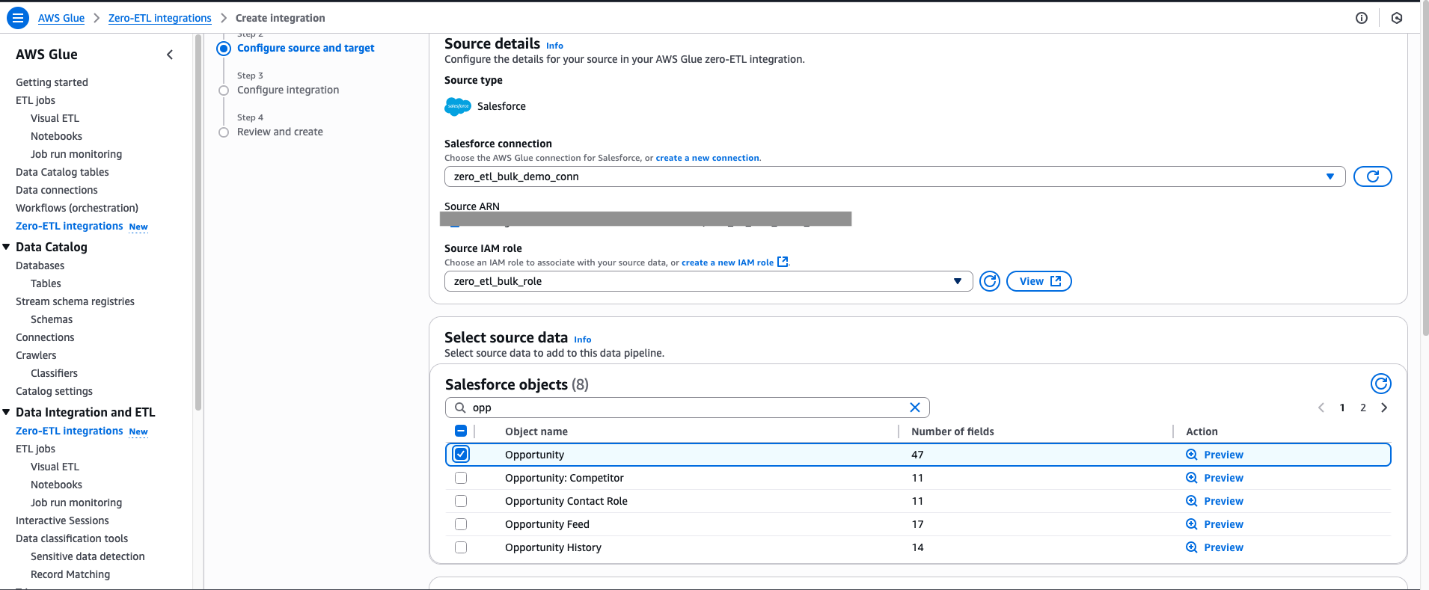
For Namespace or Database In this example, we use the zero_etl_bulk_demo_db (from the prerequisites).
- For Target IAM role, select the zero_etl_demo_role (from the prerequisites).
- Choose Next.
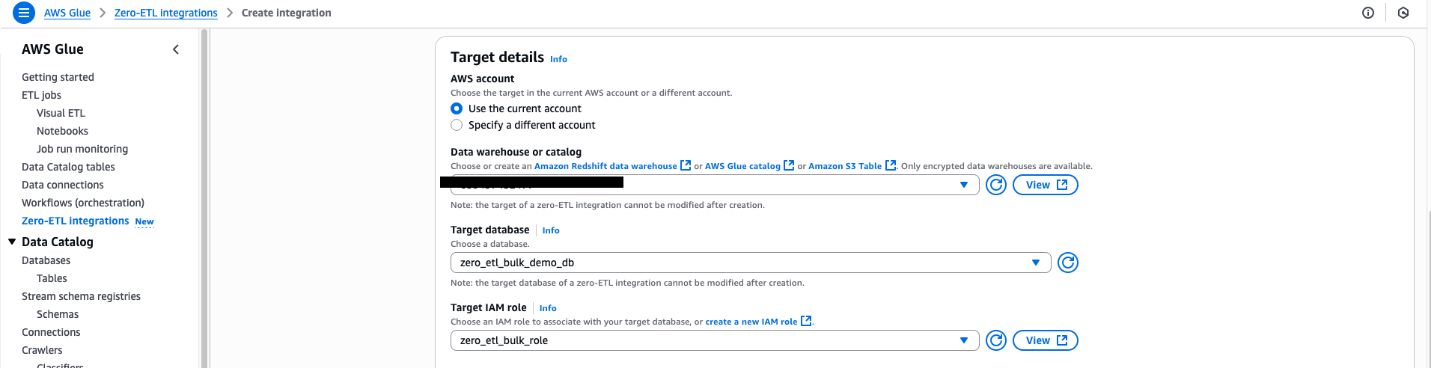
- In the Integration details section, for Name, enter
zero-etl-bulk-demo-integration. - Choose Next.
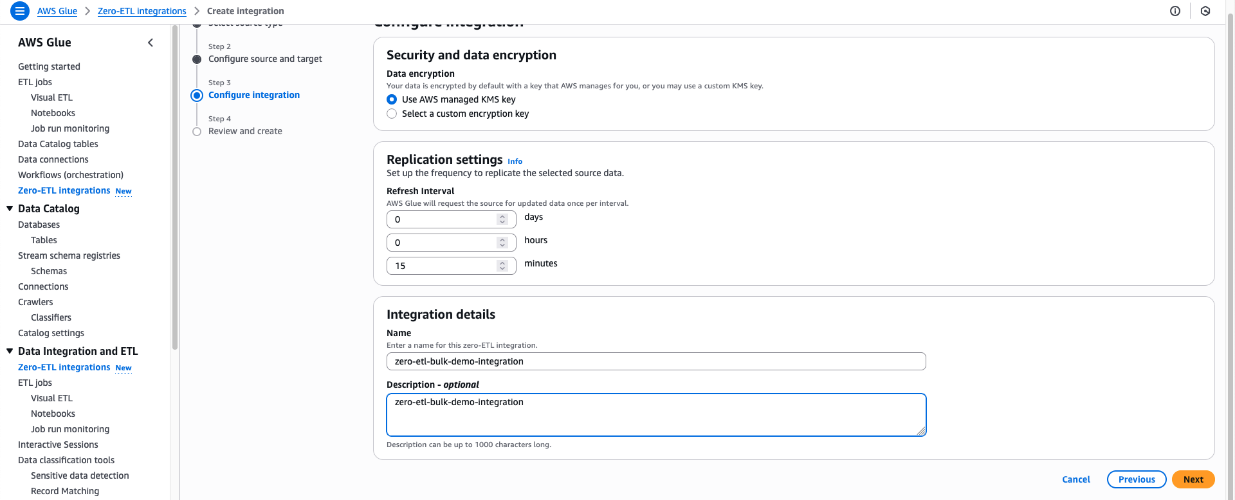
- Review the details and choose Create and launch integration.
- The newly created integration will show as Active in about a minute.

Clean up
Note that following these steps will permanently delete the resources created in this post; back up any important data before proceeding.
- Delete the zero-ETL integration
zero-etl-bulk-demo-integration. - Delete content from the S3 bucket
zeroetl-etl-bulk-demo-bucket. - Delete the Data Catalog database
zero_etl_bulk_demo_db. - Delete the Data Catalog connection
zero_etl_bulk_demo_conn. - Delete the Secrets Manager secret
zero_etl_bulk_demo_secret.
Conclusion
The integration of Salesforce Bulk API support in AWS Glue zero-ETL marks a significant advancement in our data integration capabilities. By addressing the limitations of the REST API, efficiently handling wide-column entities and compound fields, and implementing robust error handling, you can now use AWS Glue zero-ETL to ingest larger volumes of Salesforce data more efficiently.This enhancement improves performance and opens up new possibilities for your organization to use their Salesforce data for analytics, machine learning, and other data-driven initiatives. As we continue to evolve AWS Glue zero-ETL, we remain committed to providing cutting-edge solutions that empower our customers to make the most of their data integration processes.
Learn more
- AWS Glue documentation
- AWS Glue zero-ETL documentation
- AWS Glue Salesforce Connector documentation
- SageMaker lakehouse