AWS Architecture Blog
How HashiCorp made cross-Region switchover seamless with Amazon Application Recovery Controller
This blog was co-authored by Brandon Raabe, Sr. Site Reliability Engineer at HashiCorp.
In cloud-based systems, minutes of downtime can translate to significant business impact and eroded customer trust. HashiCorp, a leader in multicloud infrastructure automation software, faced this critical challenge as their HashiCorp Cloud Platform (HCP) scaled to serve enterprise customers with stringent availability requirements. When Regional outages threatened service continuity, the complex dance of failing over DNS entries, workloads, and databases across AWS Regions had become an error-prone process requiring intense coordination. This post chronicles how HashiCorp’s Site Reliability Engineering (SRE) team transformed their disaster recovery capabilities by implementing Amazon Application Recovery Controller (ARC), creating a solution that not only dramatically simplified cross-Region failovers but also provided a standardized way to signal Regional context to their distributed services.
In this post, we discuss HashiCorp’s journey from manual, stress-inducing failover procedures to a streamlined, confident approach that fundamentally changed how they deliver on their enterprise-grade resilience promises.
Challenges with disaster recovery in a multicloud infrastructure
HashiCorp’s SRE team recognized that as their cloud platform scaled to serve mission-critical enterprise workloads, their disaster recovery approach needed an upgrade. The existing manual processes required precise coordination across multiple systems during already stressful outage scenarios, which could lead to potential complications when speed and accuracy matter most. Regional outages posed particular challenges: if the control planes for critical services became unavailable, the very tools needed to execute recovery might be inaccessible.
ARC emerged as the ideal solution with its unique architecture: a highly available data plane accessible through endpoints in five distinct Regions, so the recovery mechanism remains operational even during significant Regional disruptions. By using the AWS SDK to interface with ARC, HashiCorp gained several critical advantages. They could apply infrastructure as code (IaC) practices to disaster recovery workflows, automate testing of failover procedures, and integrate resilience seamlessly with their existing operational tooling. This solution transformed their disaster recovery from a specialized manual procedure into a codified, repeatable process embedded within their platform operations.
Requirements and architectural considerations
After evaluating multiple disaster recovery approaches, HashiCorp established three core requirements for their solution. First, while maintaining human judgment for initiating failovers, the execution needed to proceed without additional operator interventions after it was triggered. This human-in-the-loop design preserved deliberate decision-making while reducing error-prone manual steps during implementation.
Second, the architecture needed exceptional resilience against the very failures it was designed to mitigate. Traditional DNS failover solutions presented a critical vulnerability: dependency on single-Region control planes that might be unavailable during an outage. ARC solved this problem through its distributed architecture, connecting Amazon Route 53 to a resilient control mechanism, enabled by Route 53 health checks, accessible through multiple Regional endpoints. This means the failover system itself remained available even if the primary Region went offline.
Third, the solution needed to meet or exceed HashiCorp’s existing Recovery Point Objective (RPO) and Recovery Time Objective (RTO) metrics—the maximum acceptable data loss and downtime thresholds. Using ARC, the SRE team planned to not just reach these targets but make substantial improvements, reducing potential customer impact during Regional events and strengthening HashiCorp’s enterprise-grade resilience.
Solution overview
To transform their disaster recovery posture, HashiCorp’s SRE team designed an architecture centered around ARC and complemented by a purpose-built orchestration service. This architecture seamlessly bridges the human decision to initiate failover with the complex technical operations required to shift traffic between Regions with minimal disruption.
At the heart of the solution is a custom failover service that serves as the orchestration layer for Regional transitions. This service maintains configuration details for the ARC cluster and provides a single, controlled interface for initiating Regional switchovers. When activated, the service establishes a secure connection to the ARC API endpoints and executes a two-step workflow: first disabling routing controls for the primary Region, then enabling those for the secondary Region. This sequential approach provides a clean traffic transition without split-brain scenarios or dropped connections.
The DNS architecture underwent a strategic evolution to support this new capability. HashiCorp reconfigured their critical ingress endpoints as Route 53 failover record pairs, with each pair consisting of a primary and secondary record. Each record is linked to a health check that monitors the state of an ARC routing control—effectively connecting AWS’s global DNS service to the ARC routing control. The primary records resolve to endpoints in the primary Region, and secondary records point to corresponding infrastructure in the standby Region. When routing controls change state, the associated health checks automatically trigger Route 53 to adjust DNS resolution patterns, redirecting traffic to the appropriate Regional infrastructure.
HashiCorp maintains their secondary Region in a warm standby configuration, with essential services running but not actively serving client traffic until a failover event occurs. To enable seamless awareness of Region status across their distributed system, the team implemented a signaling mechanism using specially crafted TXT DNS records. These records are tied to the same ARC routing controls as the primary service endpoints, effectively creating a discoverable, global state indicator. Services can query these TXT records to dynamically determine the currently active Region and adjust their internal routing, replication, and operational behaviors accordingly — alleviating the need for a separate configuration distribution system and making sure all components have a consistent view of the current Regional state.
The following diagram illustrates the disaster recovery workflow.
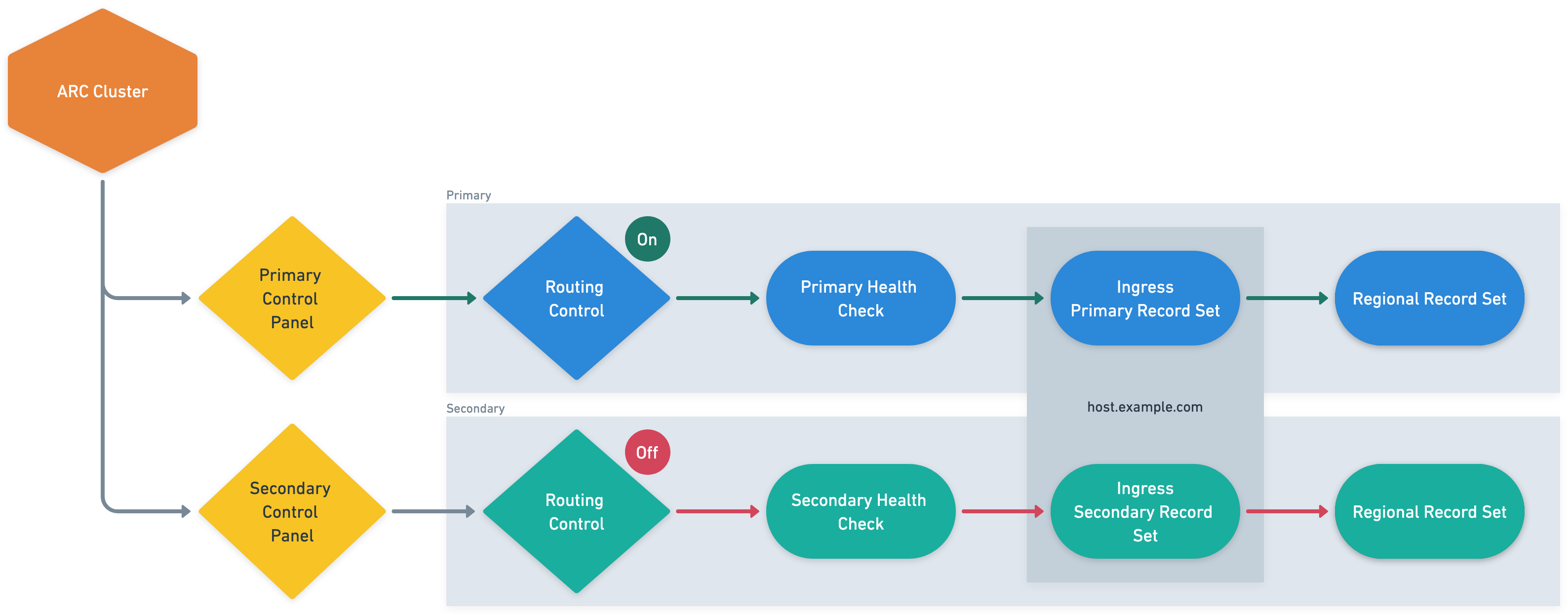
This architecture combines human oversight for initiating critical Regional transitions with fully automated execution after the decision is made. The use of ARC’s globally distributed control plane removes single-Region dependencies that might otherwise compromise the failover mechanism itself during a Regional outage event.
Operational decision framework for Regional failover
HashiCorp’s Regional failover process balances automated monitoring with deliberate human decision-making. Their comprehensive observability platform continuously monitors Regional health, automatically alerting the incident response team when anomalies are detected. When alerts trigger, the incident management protocol activates, with an incident commander quickly assembling experts to assess the situation.
The team follows a structured evaluation framework to determine if failover is warranted: confirming the issue is Region-specific, verifying that redundant intra-Region components can’t mitigate the problem, and assessing whether the projected Regional recovery time exceeds acceptable customer impact thresholds. This approach prevents unnecessary Regional transitions while providing rapid action when genuinely needed.
After the decision to failover is made, an authorized operator initiates the process through a single API call to their orchestration service, which then interfaces with ARC to execute the complex sequence of routing control changes. This design preserves human judgment for the critical decision while using automation for precise execution, so HashiCorp can respond confidently and consistently during high-pressure Regional outage scenarios.
Disaster recovery testing
HashiCorp maintains operational readiness through a disciplined monthly disaster recovery testing program in their integration environment. One week before each scheduled test, the team notifies all stakeholders to confirm organization-wide awareness and participation. On test day, they follow formal incident protocols, creating dedicated communication channels for transparent observation and collaboration.
The test execution mirrors their production failover process: an operator initiates the recovery sequence through their API, activating the ARC routing controls to shift traffic to the secondary Region. What sets HashiCorp’s approach apart is their comprehensive validation methodology. The team verifies critical services in the secondary Region and then fails back to the primary Region with subsequent validation. This bidirectional testing confirms both failover and failback procedures work reliably.
Each exercise concludes with a structured retrospective where the team documents observations and identifies improvement opportunities. By treating these tests as learning experiences rather than compliance activities, HashiCorp has established a continuous improvement cycle for their disaster recovery capabilities. The insights from these regular drills have led to numerous refinements in their ARC implementation and operational procedures, so their team can respond confidently during actual outages with practiced, predictable procedures.
Conclusion
The collaboration between HashiCorp and AWS through ARC has revolutionized HashiCorp’s disaster recovery capabilities. Regional transitions that once required careful DNS record manipulation by specialized operators now execute through a single API call, with traffic shifting within seconds and full propagation completing in approximately 2 minutes. This dramatic simplification, achieved by integrating the resilient ARC architecture with HashiCorp’s custom orchestration service, has not only improved recovery metrics but has also strengthened their enterprise-grade resilience promises.
ARC has solved a fundamental distributed systems challenge by providing a reliable mechanism for services to determine the active Region. By linking ARC routing controls to specialized TXT records, HashiCorp created a consistent global indicator that allows services to automatically adjust their behavior without additional coordination systems—simplifying their architecture and reducing dependencies.
Most significantly, this implementation has democratized disaster recovery within HashiCorp, transforming it from a specialized capability to a standardized procedure executable by their regular on-call rotation. The solution’s highly available endpoints across multiple Regions makes sure the recovery mechanism itself remains operational even during severe outages—addressing a critical vulnerability in their previous approach.
For HashiCorp’s enterprise customers, these improvements translate directly to business value: reduced recovery times during Regional events, increased operational confidence, and assurance that their critical infrastructure management tools will remain available even during major cloud disruptions. As HashiCorp continues to refine their approach through rigorous testing and continuous improvement, their ARC implementation demonstrates how thoughtfully architected disaster recovery can evolve from merely an insurance policy into a strategic competitive advantage.
To learn more, visit Amazon Application Recovery Controller, AWS Multi-Region Capabilities, and AWS multi-Region fundamentals.