AWS Architecture Blog
Category: Analytics

Temporal data lake architecture for benchmark and indices analytics
Financial trading houses and stock exchanges generate enormous volumes of data in near real-time, making it difficult to perform bi-temporal calculations that yield accurate results. Achieving this requires a processing architecture that can handle large volumes of data during peak bursts, meet strict latency requirements, and scale according to incoming volumes. In this post, we’ll […]

Reduce archive cost with serverless data archiving
For regulatory reasons, decommissioning core business systems in financial services and insurance (FSI) markets requires data to remain accessible years after the application is retired. Traditionally, FSI companies either outsourced data archiving to third-party service providers, which maintained application replicas, or purchased vendor software to query and visualize archival data. In this blog post, we […]

Let’s Architect! Open-source technologies on AWS
We brought you a Let’s Architect! blog post about open-source on AWS that covered some technologies with development led by AWS/Amazon, as well as well-known solutions available on managed AWS services. Today, we’re following the same approach to share more insights about the process itself for developing open-source. That’s why the first topic we discuss […]

Managing data confidentiality for Scope 3 emissions using AWS Clean Rooms
Scope 3 emissions are indirect greenhouse gas emissions that are a result of a company’s activities, but occur outside the company’s direct control or ownership. Measuring these emissions requires collecting data from a wide range of external sources, like raw material suppliers, transportation providers, and other third parties. One of the main challenges with Scope […]

Creating scalable architectures with AWS IoT Greengrass stream manager
Designing a scalable, global, real-time, distributed system to process millions of messages from a variety of critical devices can complicate architectures. Collecting large data streams or image recognition from the edge also requires scalable solutions. AWS IoT Core is designed to handle large numbers of Internet of things (IoT) devices sending a few messages per […]
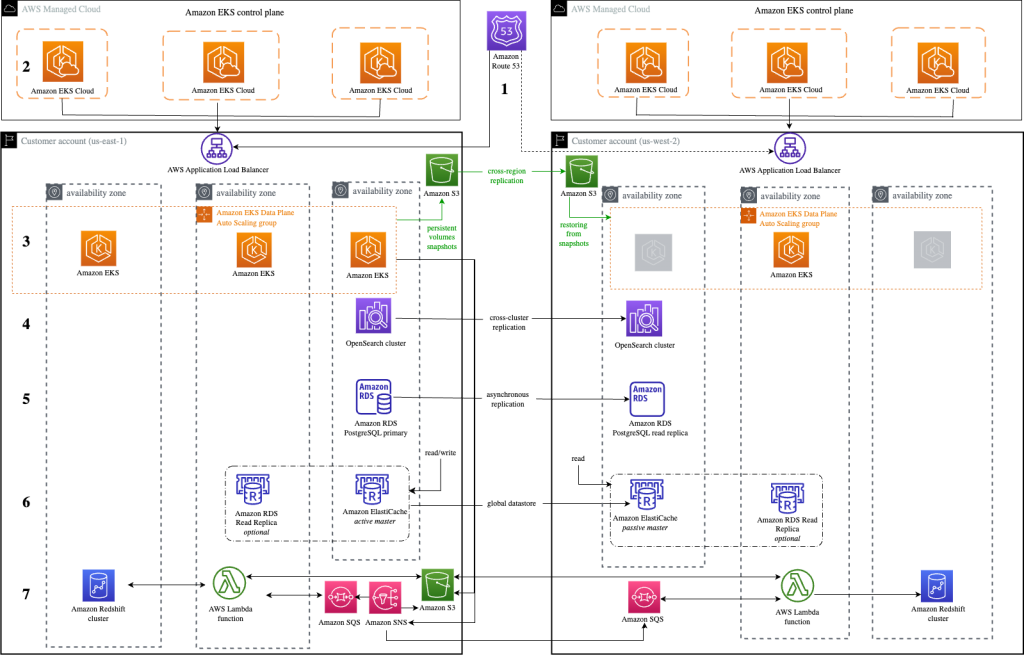
Disaster Recovery Solutions with AWS managed services, Part 3: Multi-Site Active/Passive
Welcome to the third post of a multi-part series that addresses disaster recovery (DR) strategies with the use of AWS-managed services to align with customer requirements of performance, cost, and compliance. In part two of this series, we introduced a DR concept that utilizes managed services through a backup and restore strategy with multiple Regions. […]

Boosting Resiliency with an ML-based Telemetry Analytics Architecture
Data proliferation has become a norm and as organizations become more data driven, automating data pipelines that enable data ingestion, curation, and processing is vital. Since many organizations have thousands of time-bound, automated, complex pipelines, monitoring their telemetry information is critical. Keeping track of telemetry data helps businesses monitor and recover their pipelines faster which results […]

Building an event-driven solution for AvalonBay property leasing and search
In this blog post, we show you how to build an event-driven and serverless solution for property leasing and search that is scalable and resilient. This solution was created for AvalonBay Communities, Inc.—a leading residential Real Estate Investment Trusts (REITs). It enables: More than 150,000 multi-parameter searches per day The processing of more than 3,500 […]

Text analytics on AWS: implementing a data lake architecture with OpenSearch
Text data is a common type of unstructured data found in analytics. It is often stored without a predefined format and can be hard to obtain and process. For example, web pages contain text data that data analysts collect through web scraping and pre-process using lowercasing, stemming, and lemmatization. After pre-processing, the cleaned text is […]

Building a healthcare data pipeline on AWS with IBM Cloud Pak for Data
Healthcare data is being generated at an increased rate with the proliferation of connected medical devices and clinical systems. Some examples of these data are time-sensitive patient information, including results of laboratory tests, pathology reports, X-rays, digital imaging, and medical devices to monitor a patient’s vital signs, such as blood pressure, heart rate, and temperature. […]