随着智能汽车电子电器架构的迭代升级,车端算力水平正经历前所未有的提升。在这一技术背景下,我们持续探索构建更为高效、敏捷的车云协同架构,以满足日益增长的数据处理需求。基于之前的灵活数采的落地实践云端引擎:使用 Amazon Lambda 和 Amazon S3 打造智能汽车数据处理平台,随着车端 SOC 算力的不断增强,我们重新审视了整体架构,将数据采集模型向”轻量化、服务化”方向演进。
新架构具有以下特点:
- 动态采集策略:车端数据采集逻辑支持远程更新,实现按需采集
- 边缘数据库:对数据进行车内存储、计算和处理,利用列式存储和压缩减少传输负载
- 云端无服务化:采用 Amazon Lambda 构建弹性伸缩的数据处理引擎
- 湖仓一体化存储:结合 Amazon S3 Tables 和 Iceberg 湖仓架构,实现成本与性能的最优平衡
- 端到端边云一体化存储:GreptimeDB 云端可直接导入和查询边缘上传的数据格式,无 ETL
格睿科技(Greptime)成立于 2022 年 4 月,专注于为智能汽车、能源、物联网等时序数据密集型领域提供实时、高效的数据存储与分析服务。其打造的车云一体方案专为智能汽车场景设计,覆盖车端到云端全链路数据管理需求。核心价值在于降低车企时序数据使用成本,提升数据效率与商业价值,助力客户从海量数据中挖掘业务增长点。GreptimeDB Edge 是专为车机设计的数据库,针对存储和计算进行了优化,以极低的资源消耗实现高效的数据处理。这使得车机端可以充分利用车内的算力来开发应用,满足数据采集和计算的需求。此外,GreptimeDB Edge 支持高压缩率的数据文件同步至云端对象存储,供云端查询使用,并显著降低了带宽流量费用。
Amazon S3 Tables 是亚马逊云科技提供的一种基于 S3 的表格数据存储服务。它允许用户以表格形式管理和查询存储在 S3 中的数据,无需额外的数据库。S3 Table 支持多种数据格式,如 CSV、JSON、Parquet 等,用户可以通过简单的 API 或 SQL 查询来操作数据。它具有高可扩展性、可靠性和安全性,与 AWS 的其他服务如 Athena、Redshift 等无缝集成,适用于数据分析、日志处理、物联网等多种场景。
接下来,我们将以 CAN 信号为例,展示一个结合了 Amazon S3 Tables 与 GreptimeDB Edge 的车云解决方案 demo。在该方案中,GreptimeDB Edge 在车端运行,负责 CAN 信号的收集,压缩存储,边缘查询,数据导出和数据上传。车端数据汇总至 Amazon S3 后,即可借助 Amazon S3 Tables 强大的数据处理及查询分析能力,实现对车端数据的高效查询以及深度分析等操作。
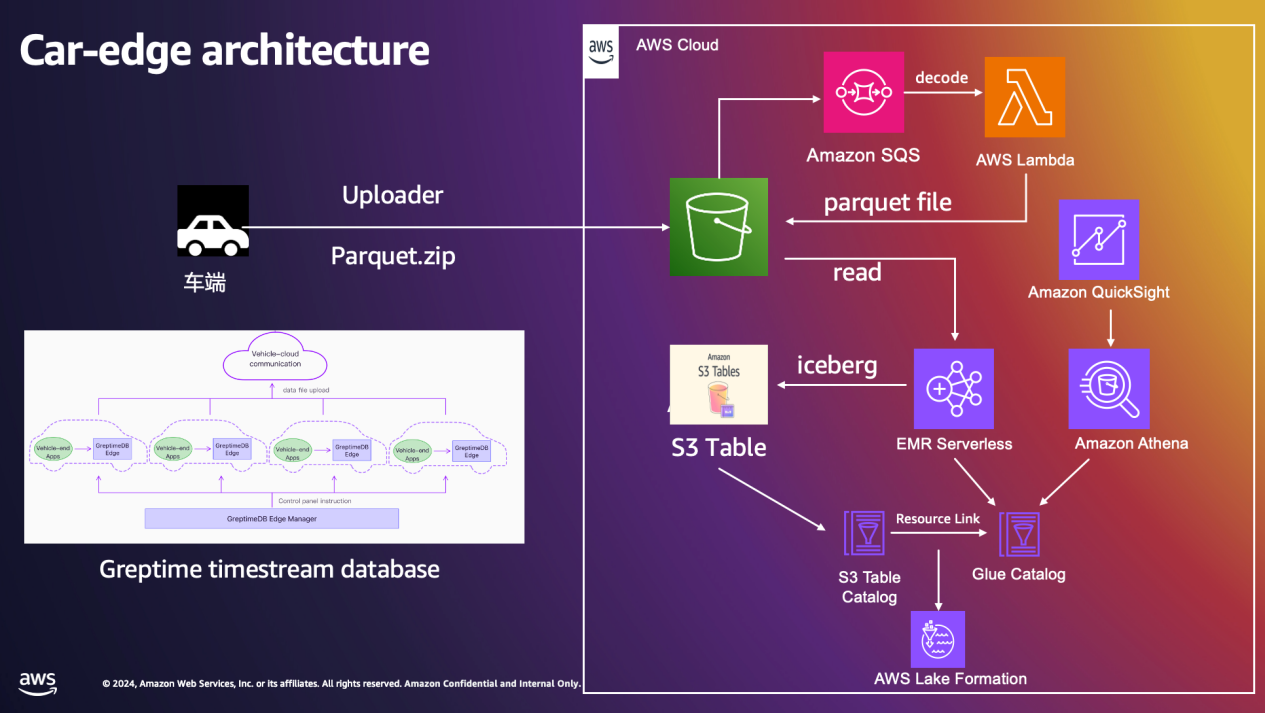
整体架构图:
数据流程:
- 车端数据传入 S3 桶
- 配置 S3 notification event 写入 SQS,每次 put 操作触发 Lambda 对文件进行解压,解压之后写入 S3 桶
- EMR Serverless 读取原始的解压文件进行数据 ETL 分析,主要包括读取 parquet 文件然后写入 S3 tables(iceberg 格式)
- 开启 S3 tables intergration 共享表结构,在 Lake Formation 授与读写权限,让 Athena 可以直接读取 S3 table 的表数据进行即时查询
- 创建 resource link 将 S3 table 的 catalog 共享到 Glue catalog,集成不同的数据分析服务,构建不同场景的数据查询分析
- 通过 QuickSight 可以读取 Athena 中的数据进行 BI 报表构建
车端部署
1. GreptimeDB Edge 编译部署
目前,车机上主流的芯片是骁龙 8295,操作系统是 Android。在本次 demo 中,我们选择 Android 作为目标平台。GreptimeDB Edge 由 Rust 语言开发,具有良好的跨平台兼容性,支持 Android 平台。通过交叉编译技术,我们可以生成适用于 Android 平台的二进制文件 greptime-edge。技术细节可见这里。
在实际应用中,GreptimeDB Edge 通常以系统服务的形式在车机系统中运行。本次 demo 为简化操作,直接在车机上执行以下命令,即可启动一个 GreptimeDB Edge 实例。
./greptime-edge edge start -c edge.toml
出现以下日志,表明 DB 启动成功。
2025-03-02T12:40:49.733875Z INFO servers::http: HTTP server is bound to 127.0.0.1:4000
2025-03-02T12:40:49.733955Z INFO servers::server: Service HTTP_SERVER is started at 127.0.0.1:4000
2025-03-02T12:40:49.734073Z INFO servers::grpc: gRPC server is bound to 127.0.0.1:4001
2025-03-02T12:40:49.736356Z INFO servers::server: Service GRPC_SERVER is started at 127.0.0.1:4001
2025-03-02T12:40:49.736518Z INFO flow::adapter: Starting flownode manager's background task
2025-03-02T12:40:49.736588Z INFO ent_edge::instance: GreptimeDB Edge is started!
2. CAN 信号数据模拟和写入
本 demo 中的 can_signal_mock 负责模拟生成 CAN 信号数据,并通过 SDK 将这些数据高效地写入 GreptimeDB Edge。
以下是 demo 中表结构的展示:
MySQL [(none)]> desc table can_001;
+-----------------------------+----------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+-----------------------------+----------------------+------+------+---------+---------------+
| vin_id | String | | YES | | FIELD |
| Charging_Time_Remain_Minute | Int32 | | YES | | FIELD |
| Extender_Starting_Point | Int32 | | YES | | FIELD |
| Fuel_CLTC_Mileage | Int32 | | YES | | FIELD |
| Fuel_WLTC_Mileage | Int32 | | YES | | FIELD |
| Fuel_Percentage | Int32 | | YES | | FIELD |
| Clean_Mode | Int32 | | YES | | FIELD |
| Road_Mode | Int32 | | YES | | FIELD |
| RESS_Power_Low_Flag | Boolean | | YES | | FIELD |
| Target_SOC | Int32 | | YES | | FIELD |
| DISPLAY_SPEED | Float32 | | YES | | FIELD |
| channel_id | Int32 | | YES | | FIELD |
| Endurance_Type | Int32 | | YES | | FIELD |
| ts | TimestampMillisecond | PRI | NO | | TIMESTAMP |
+-----------------------------+----------------------+------+------+---------+---------------+
14 rows in set (0.005 sec)
需要特别指出的是,GreptimeDB Edge 提供了一个专有的 SDK,通过采用基于共享内存的写入方式,显著降低了进程间通信的开销。
GreptimeDB Edge 的性能报告详情见这里。
3. 数据查询
GreptimeDB Edge 支持在车内本地执行数据查询,并借助兼容 MySQL 和 PostgreSQL 等协议的特性,使上游用户能够直接基于车内数据库便捷地构建数据应用,实现原始数据不出车。
下面,我们将通过 MySQL 协议查询 can_001 表中 channel_id 为 1 的记录数量。
SQL 语句:
select count(*) from can_001 where channel_id = 2;
输出结果:
MySQL [public]> select count(*) from can_001 where channel_id = 2;
+----------+
| count(*) |
+----------+
| 41528 |
+----------+
4. 数据导出以及上传
本 demo 中的 s3_uploader 负责按需导出数据库中的数据,并上传到指定的对象存储(AWS S3)中。
云端部署文档
1. 参考 https://github.com/ziling777/greptime/tree/main/cdk,部署 cdk 服务,保证部署的 user 或者 role 拥有 s3table full access+admin role
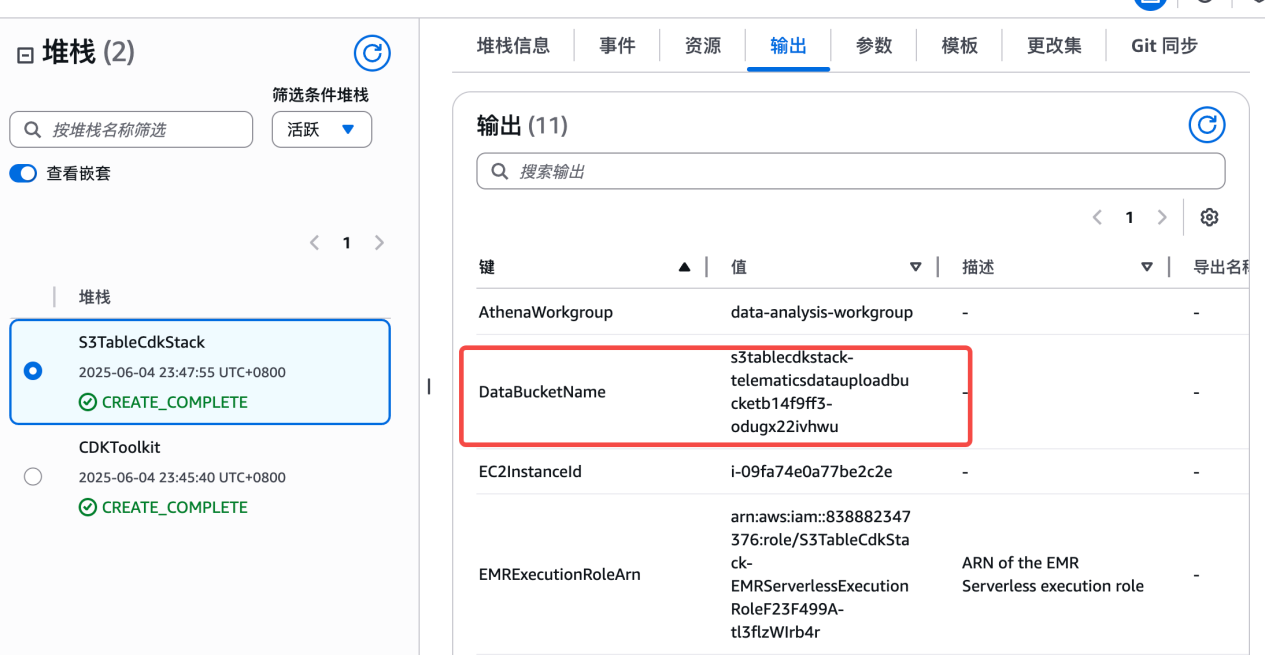
2. 部署完毕之后,选择 CloudFormation,点击输出,找到 S3 桶名
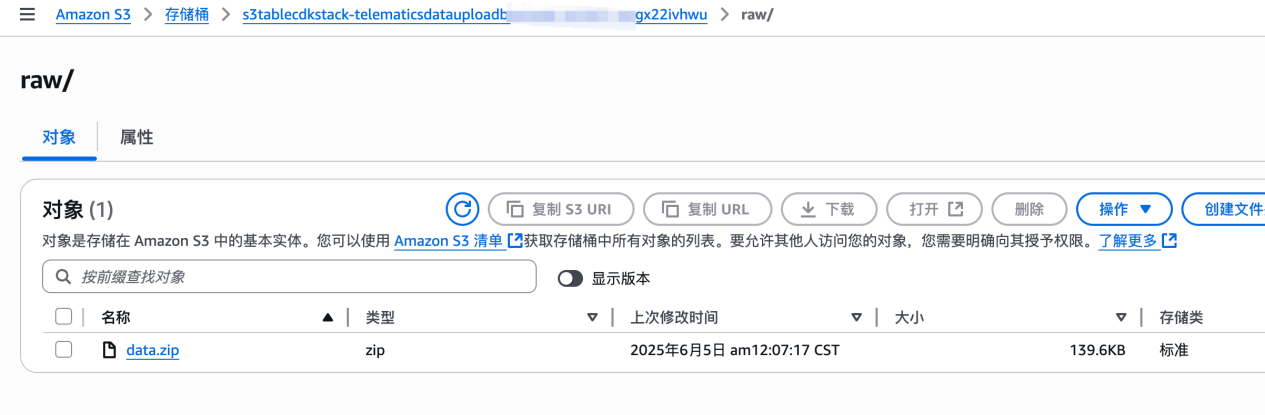
3. 访问 EC2,找到 Greptime 的机器,SSH 登陆 ,执行脚本:./greptime-edge edge start -c edge.toml。该步骤会模拟车端将数据 parquet 的压缩文件包写入 S3 的 raw 文件夹下;如果想直接测试云端环境,可以手动将文件传入 S3,文件下载地址:https://github.com/ziling777/greptime/tree/main/cdk/emr_job/sampledata
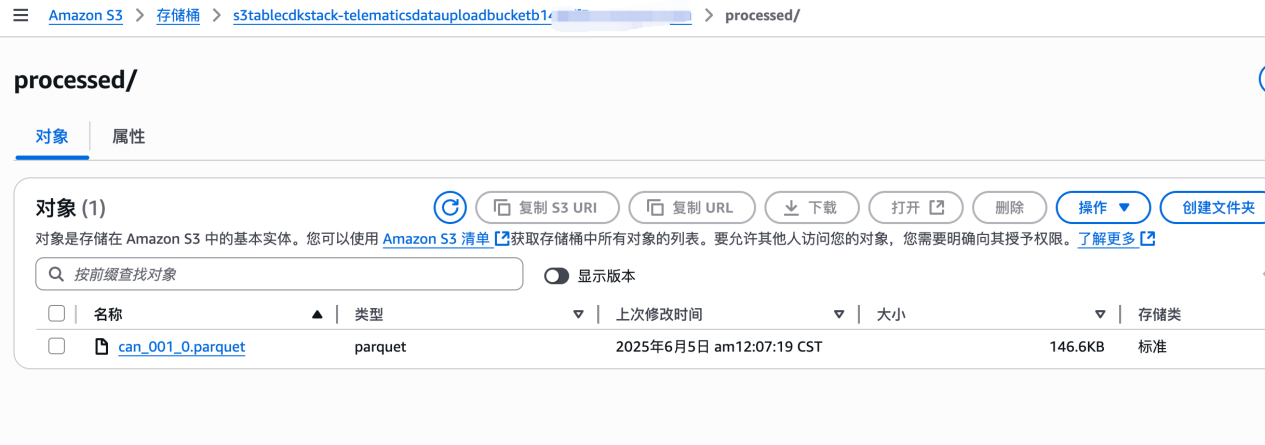
4. 访问 S3,打开创建的 S3 桶,可以看到有三个文件夹,/scripts, /raw, /processed,上传的压缩文件会自动被 Lambda 解压缩写入 processed,解压成 parquet 文件;如果需要直接测试云端可以参考 sample 数据:https://github.com/ziling777/greptime/tree/main/cdk/emr_job/sampledata
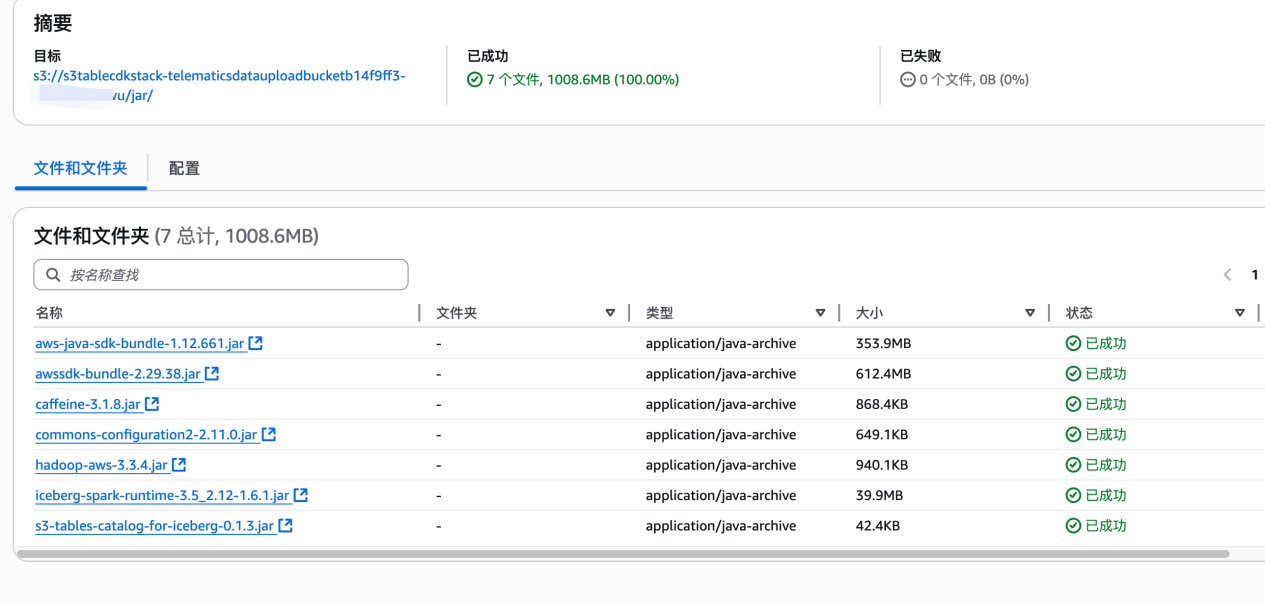
5. 因为目前 EMR Serverless 的 pyspark 的内嵌 package 没有包含 S3 table,我们需要手动加入,接着在此存储桶下创建 jar 文件夹,然后把 jar 文件传过去:https://github.com/ziling777/greptime/tree/main/cdk/emr_job/jar
Spark 的脚本如下:
from pyspark.sql import SparkSession
from pyspark.sql.functions import current_date, col, monotonically_increasing_id, concat, lit
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, BooleanType, FloatType, TimestampType
import sys
import boto3
def main():
# 获取命令行参数中的S3桶名
if len(sys.argv) > 1:
bucket_name = sys.argv[1]
else:
# 默认值
bucket_name = "default-bucket-name"
# 使用固定的catalog名称"gpdemo"
catalog_name = "gpdemo"
# 创建SparkSession
spark = SparkSession.builder \
.appName("数据处理作业") \
.getOrCreate()
# 创建命名空间
spark.sql(f"""create namespace if not exists {catalog_name}.greptime""")
# 显示所有命名空间
print("显示所有命名空间:")
spark.sql(f"""show namespaces in {catalog_name}""").show()
# 定义canbus01表的结构 - 为S3 Tables添加主键
canbus01_table = f"{catalog_name}.greptime.canbus01"
# 先删除现有表(如果存在)
try:
spark.sql(f"DROP TABLE IF EXISTS {canbus01_table}")
print(f"删除现有表: {canbus01_table}")
except Exception as e:
print(f"删除表时出错(可能表不存在): {str(e)}")
# 创建canbus01表,使用小写列名
create_canbus01_sql = f"""
CREATE TABLE {canbus01_table} (
__primary_key STRING,
vin_id STRING,
charging_time_remain_minute INT,
extender_starting_point INT,
fuel_cltc_mileage INT,
fuel_wltc_mileage INT,
fuel_percentage INT,
clean_mode INT,
road_mode INT,
ress_power_low_flag BOOLEAN,
target_soc INT,
display_speed FLOAT,
channel_id INT,
endurance_type INT,
ts TIMESTAMP
) USING ICEBERG
PARTITIONED BY (days(ts))
TBLPROPERTIES (
'write.format.default' = 'parquet',
'write.parquet.compression-codec' = 'snappy'
)
"""
print(f"创建canbus01表: {canbus01_table}")
spark.sql(create_canbus01_sql)
# 从S3读取处理后的数据
input_path = f"s3://{bucket_name}/processed/"
print(f"从路径读取数据: {input_path}")
try:
df = spark.read.parquet(input_path)
print("数据读取成功,原始数据schema:")
df.printSchema()
print(f"数据行数: {df.count()}")
# 显示前几行数据
print("数据预览:")
df.show(5, truncate=False)
# 步骤1:移除GreptimeDB特有的列
columns_to_drop = ["__sequence", "__op_type"]
df_cleaned = df
for col_name in columns_to_drop:
if col_name in df.columns:
df_cleaned = df_cleaned.drop(col_name)
print(f"移除列: {col_name}")
# 如果存在原始的__primary_key列,也删除它,我们会重新创建
if "__primary_key" in df_cleaned.columns:
df_cleaned = df_cleaned.drop("__primary_key")
print("移除原始__primary_key列")
# 步骤2:重命名列以匹配表结构(转换为小写)
column_mapping = {
"Charging_Time_Remain_Minute": "charging_time_remain_minute",
"Extender_Starting_Point": "extender_starting_point",
"Fuel_CLTC_Mileage": "fuel_cltc_mileage",
"Fuel_WLTC_Mileage": "fuel_wltc_mileage",
"Fuel_Percentage": "fuel_percentage",
"Clean_Mode": "clean_mode",
"Road_Mode": "road_mode",
"RESS_Power_Low_Flag": "ress_power_low_flag",
"Target_SOC": "target_soc",
"DISPLAY_SPEED": "display_speed",
"Endurance_Type": "endurance_type"
}
# 应用列名映射
for old_name, new_name in column_mapping.items():
if old_name in df_cleaned.columns:
df_cleaned = df_cleaned.withColumnRenamed(old_name, new_name)
print(f"重命名列: {old_name} -> {new_name}")
# 步骤3:为数据添加主键列
df_with_pk = df_cleaned.withColumn("__primary_key",
concat(col("vin_id"), lit("_"), col("ts").cast("string")))
print("数据清理和重命名后的schema:")
df_with_pk.printSchema()
# 步骤4:确保列顺序与表定义匹配
expected_columns = [
"__primary_key", "vin_id", "charging_time_remain_minute", "extender_starting_point",
"fuel_cltc_mileage", "fuel_wltc_mileage", "fuel_percentage", "clean_mode",
"road_mode", "ress_power_low_flag", "target_soc", "display_speed",
"channel_id", "endurance_type", "ts"
]
# 检查所有期望的列是否存在
missing_columns = []
for col_name in expected_columns:
if col_name not in df_with_pk.columns:
missing_columns.append(col_name)
if missing_columns:
print(f"警告:缺少以下列: {missing_columns}")
print(f"实际列: {df_with_pk.columns}")
# 选择并重新排序列(只选择存在的列)
available_columns = [col_name for col_name in expected_columns if col_name in df_with_pk.columns]
df_final = df_with_pk.select(*available_columns)
print("最终准备插入的数据schema:")
df_final.printSchema()
print(f"最终数据行数: {df_final.count()}")
# 显示最终数据预览
print("最终数据预览:")
df_final.show(5, truncate=False)
# 将数据写入canbus01表
print(f"正在将数据写入表: {canbus01_table}")
df_final.write \
.format("iceberg") \
.mode("append") \
.saveAsTable(canbus01_table)
print("数据写入成功!")
# 查询写入的数据
print(f"查询表 {canbus01_table} 中的数据:")
result_df = spark.sql(f"SELECT * FROM {canbus01_table} LIMIT 10")
result_df.show(truncate=False)
# 获取表的行数
count_df = spark.sql(f"SELECT COUNT(*) AS total_rows FROM {canbus01_table}")
print("表中的总行数:")
count_df.show()
except Exception as e:
print(f"处理数据时出错: {str(e)}")
# 显示所有表
print(f"显示 {catalog_name}.greptime 命名空间中的所有表:")
spark.sql(f"SHOW TABLES IN {catalog_name}.greptime").show()
spark.stop()
if __name__ == "__main__":
main()
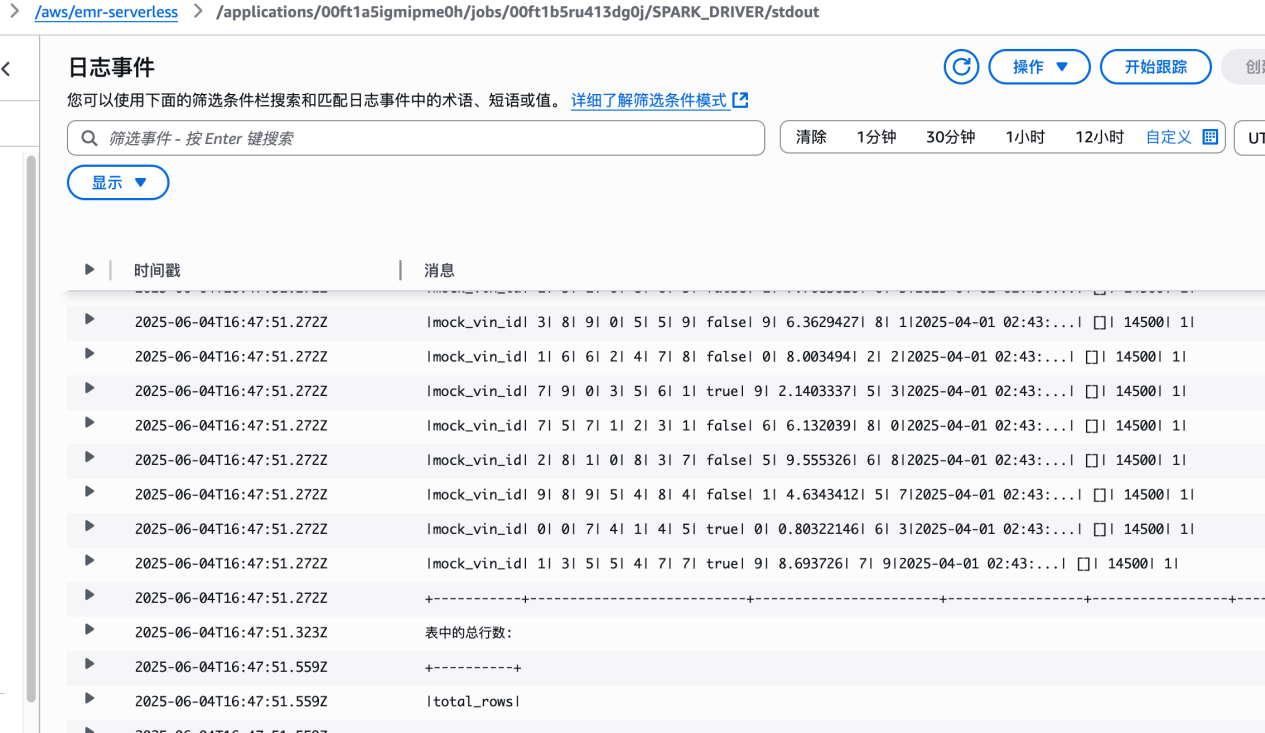
完成之后,如图所示:
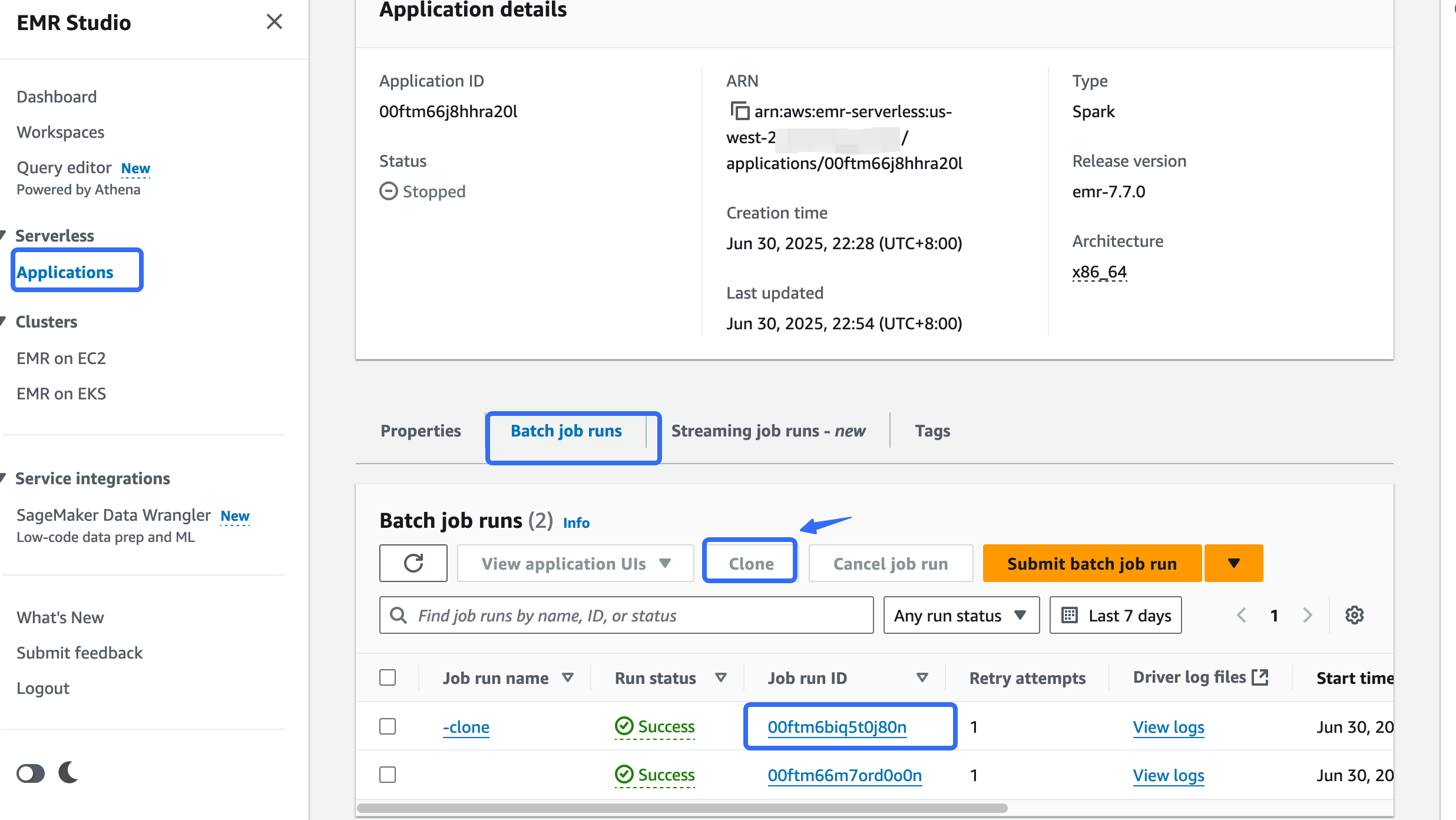
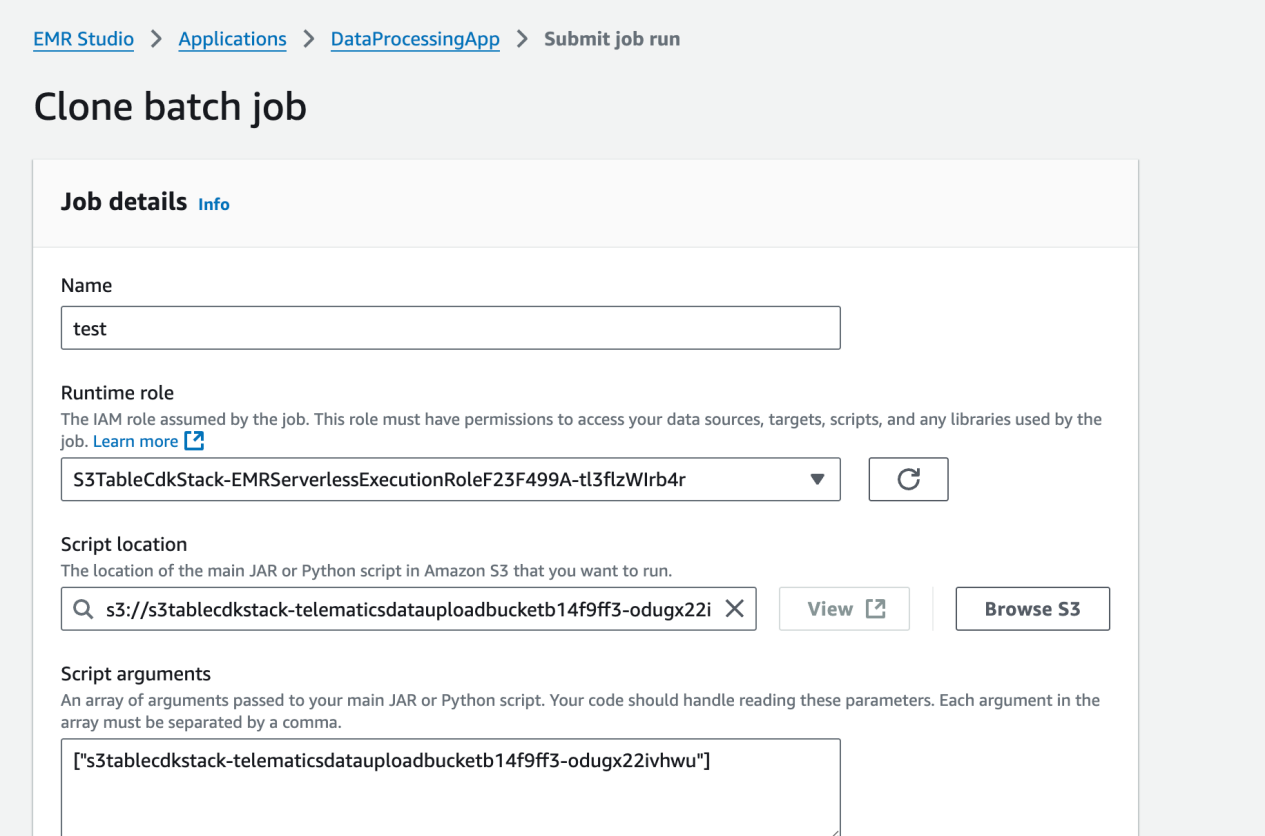
6. 打开 EMR studio,因为我们已经把所有任务提交的参数已经写入 UI,所以重新克隆一个 EMR Serverless 任务启动一个新的,把原始的数据加载到 S3 table
7. 修改任务名称之后,application log 开启 CloudWatch log, 其他配置不改,直接提交
任务执行结束之后,可以看到 CloudWatch 日志
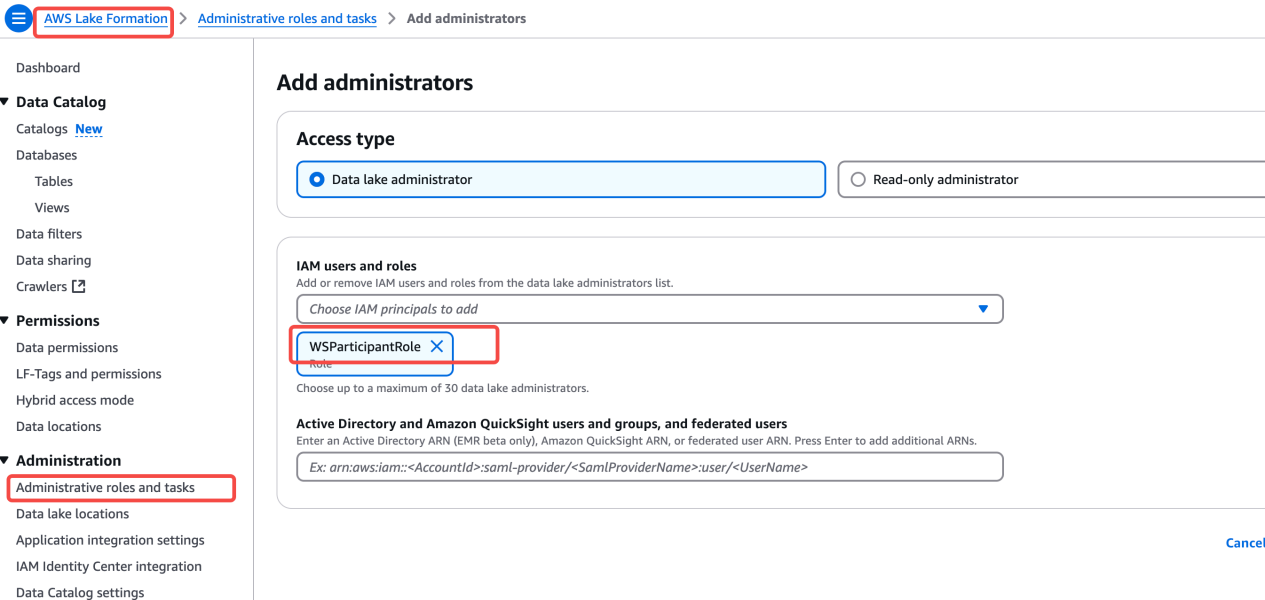
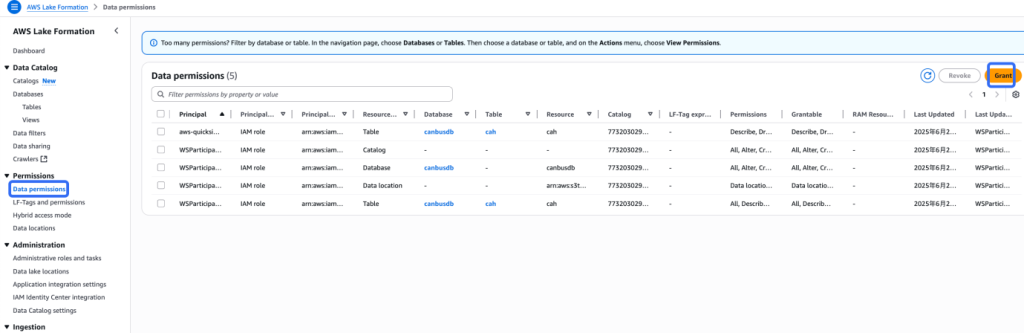
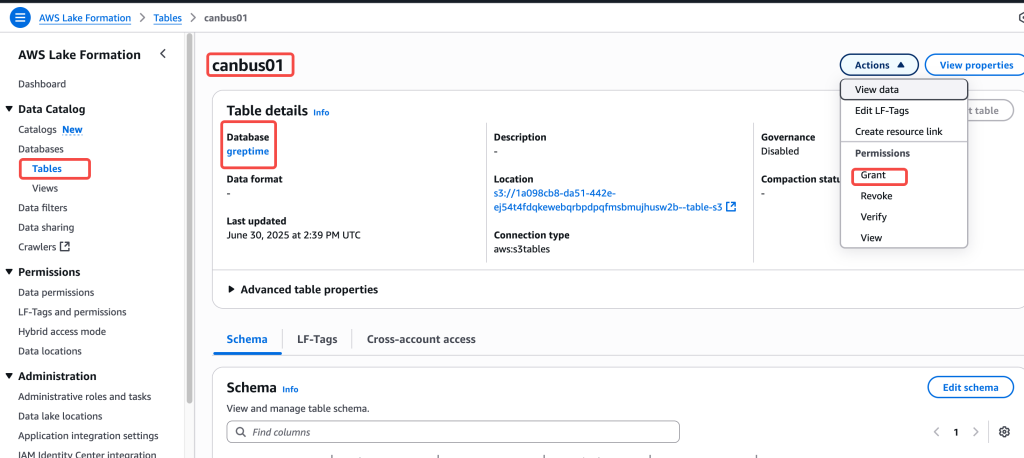
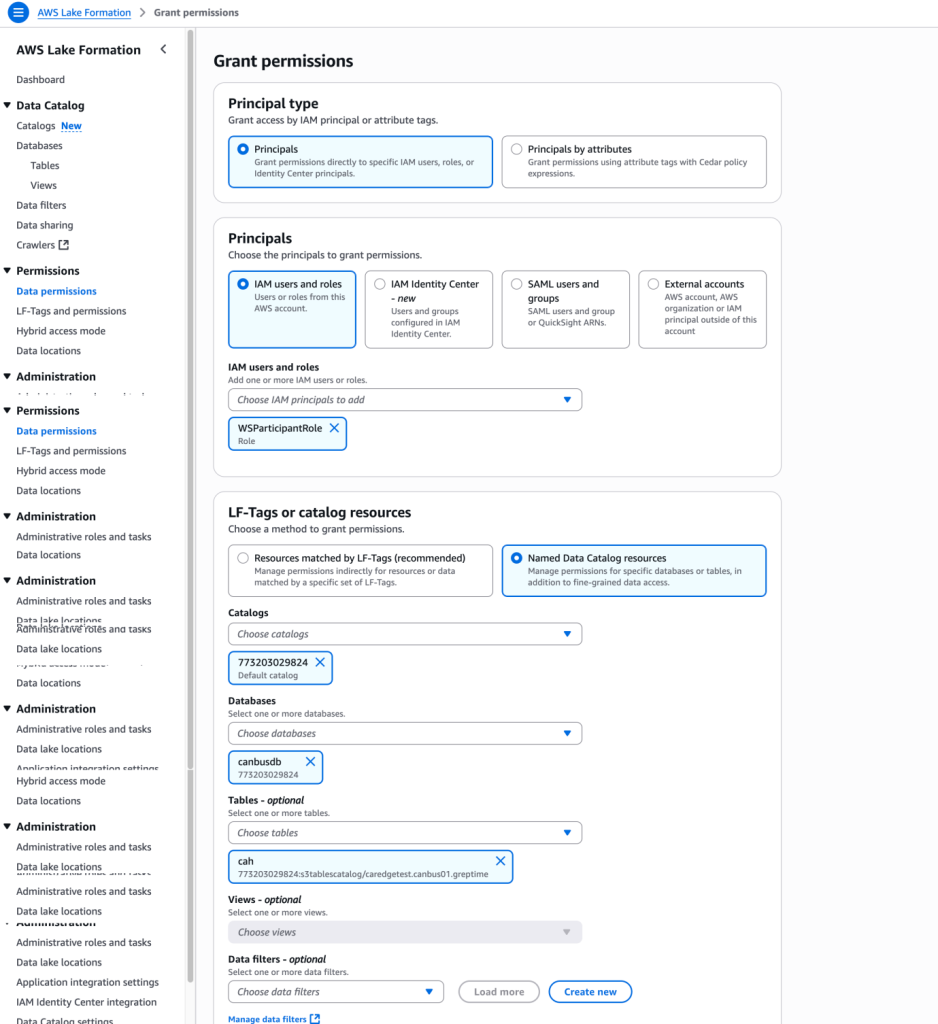
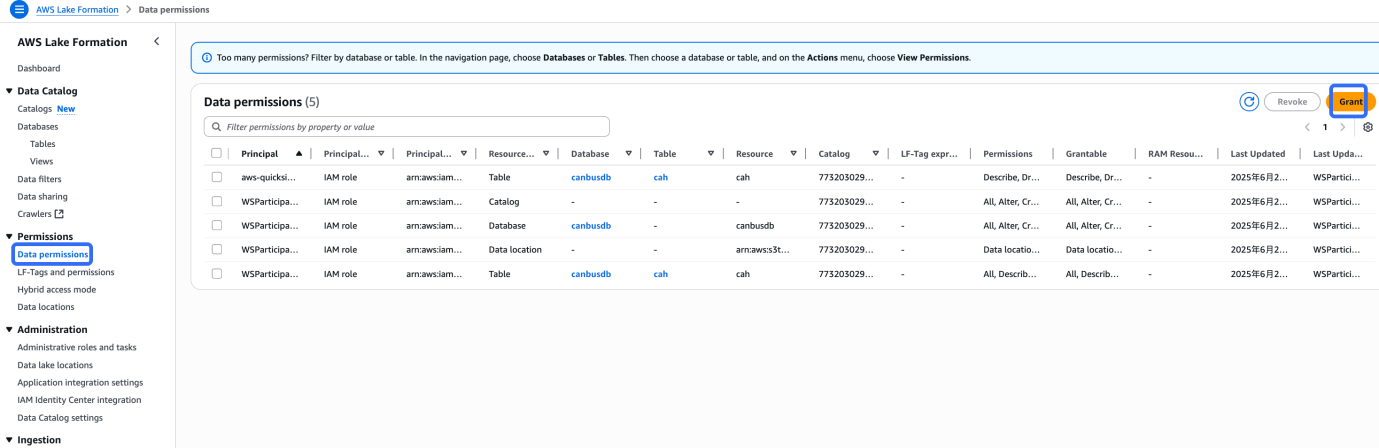
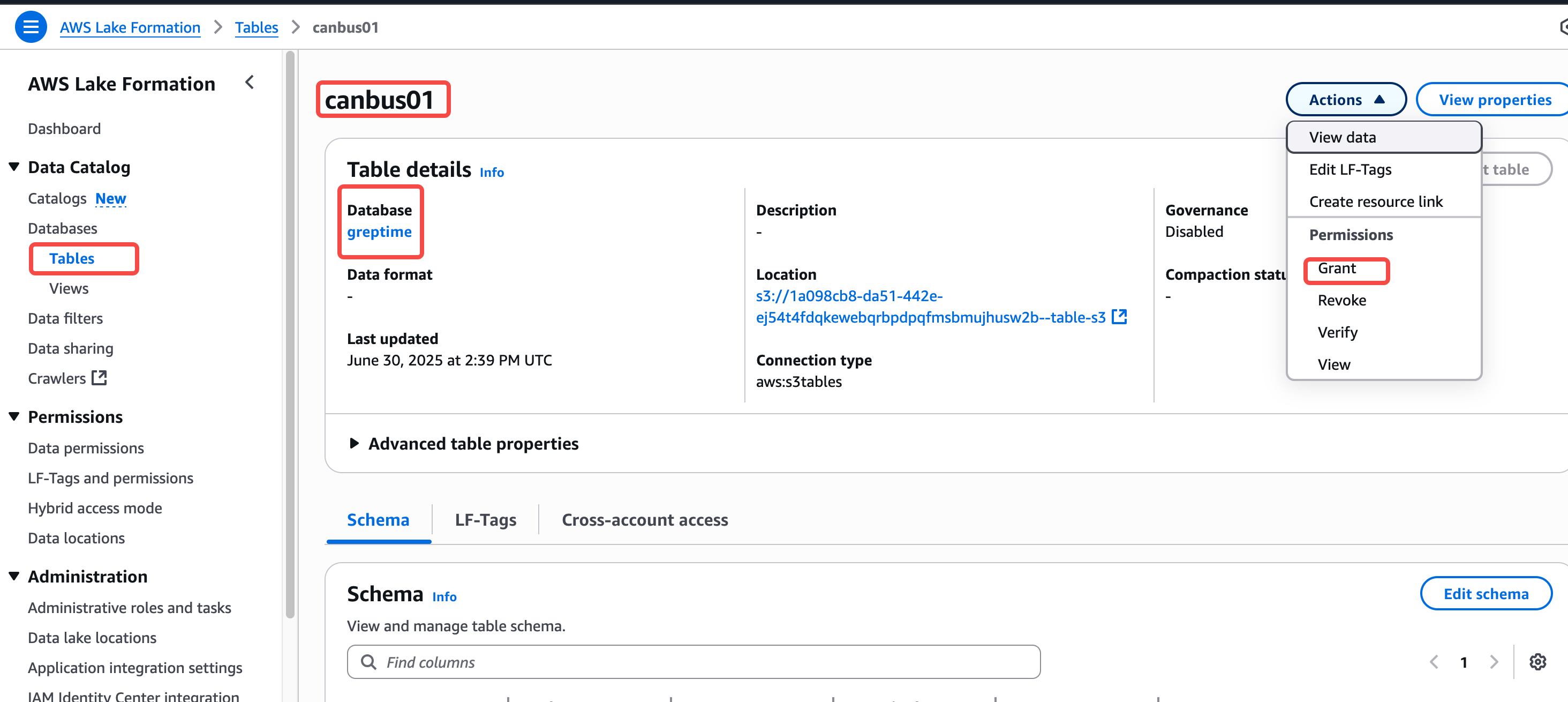
8. 为了让 S3 table 可以和 Lake Formation 以及 AWS 其他分析服务包括 Athena、EMR 集成,需要将当前操作的将 role 加入 Lake Formation admin
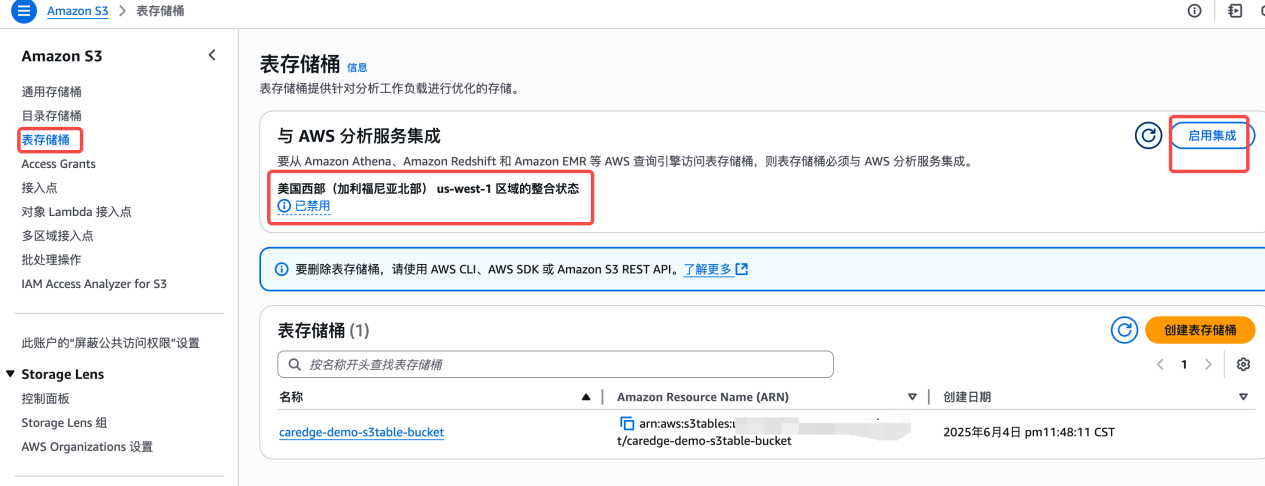
9. 开启集成
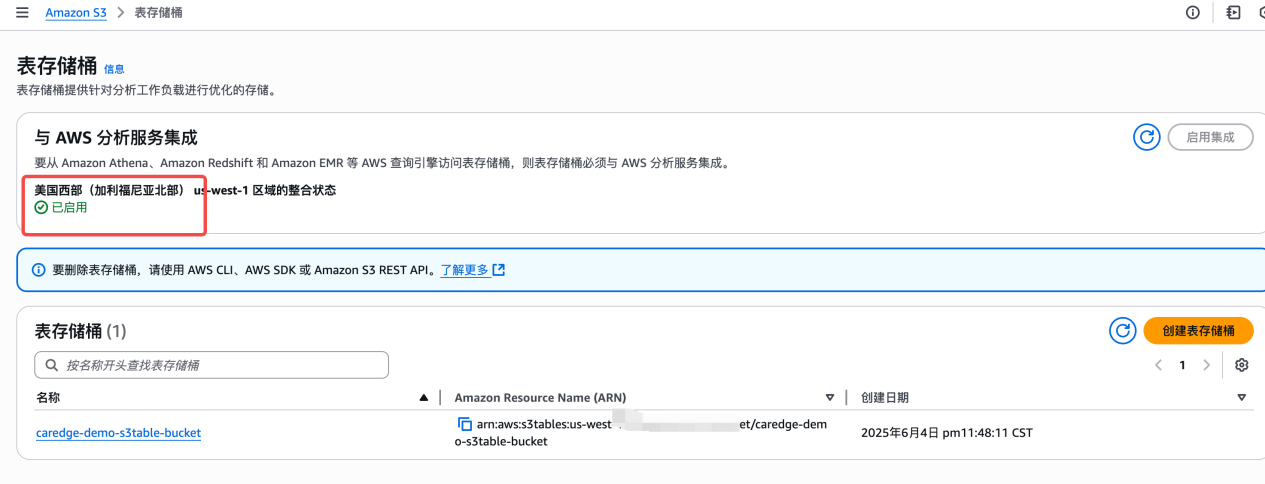
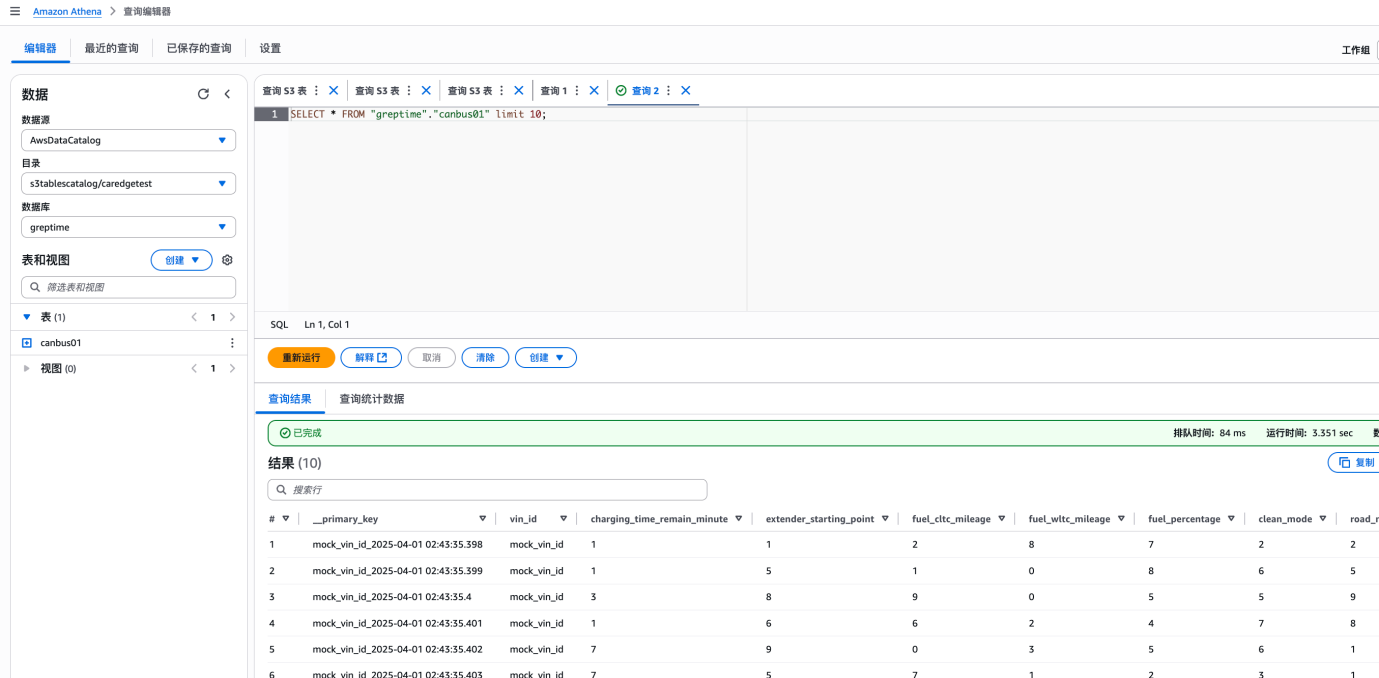
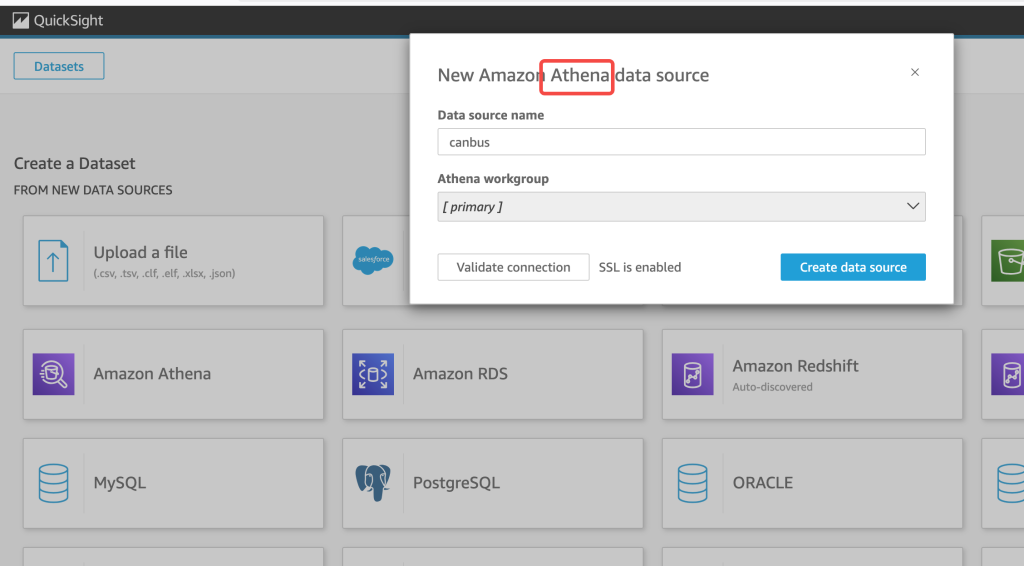
10. 集成之后,就可以用 Athena 直接查询数据,查询之前配置好 Athena 结果的保存 S3 路径
11. 接下来我们开始进行 BI 分析,访问 Amazon QuickSight,开启 QuickSight 账号,参考 https://docs.aws.amazon.com/quicksight/latest/user/signing-in.html
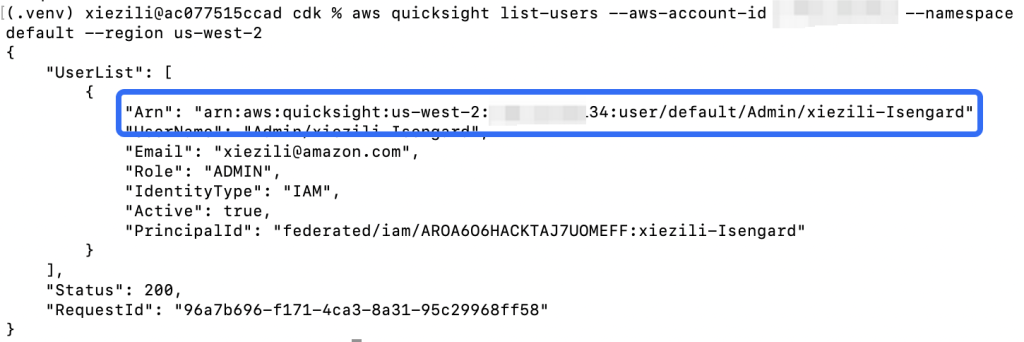
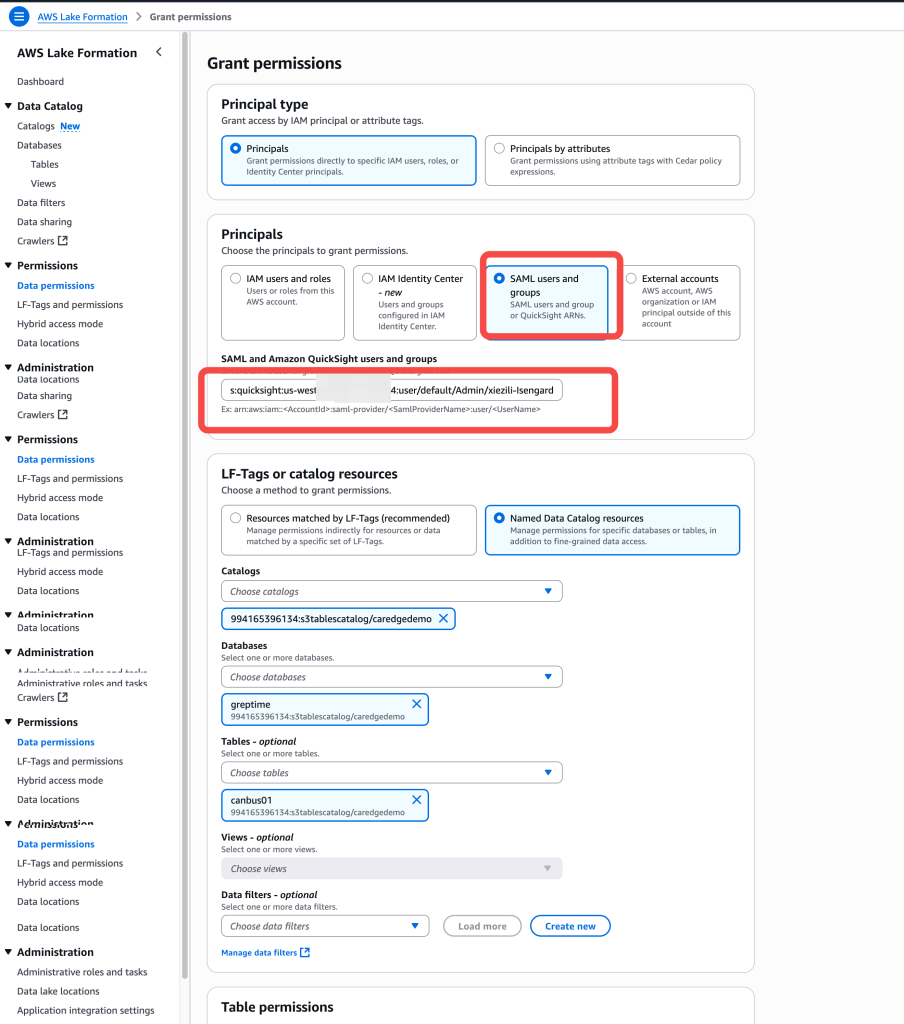
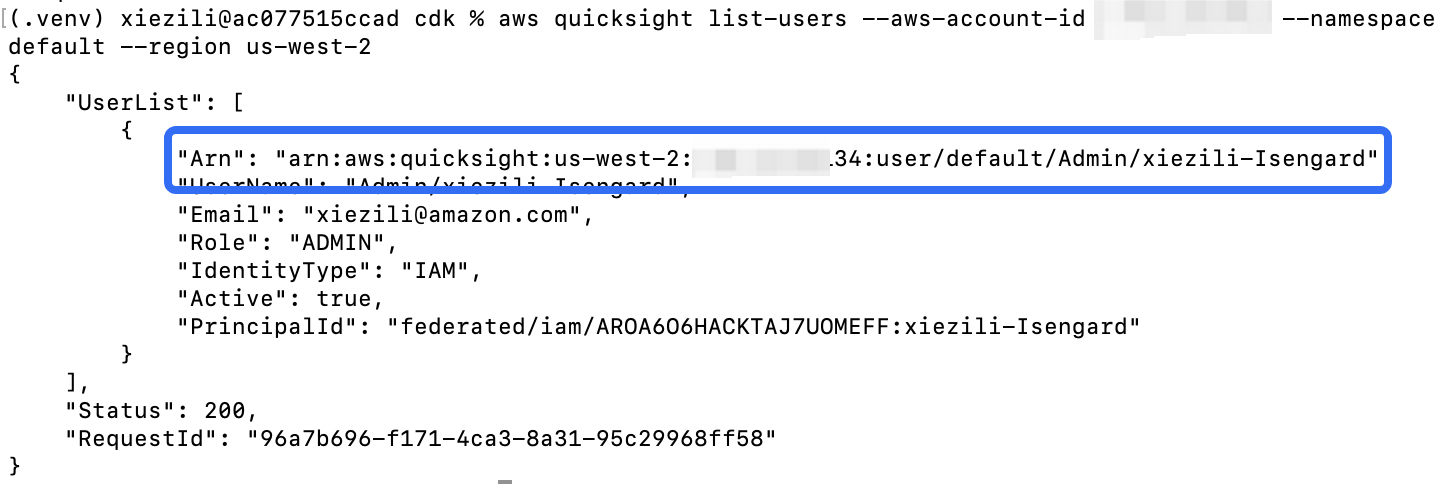
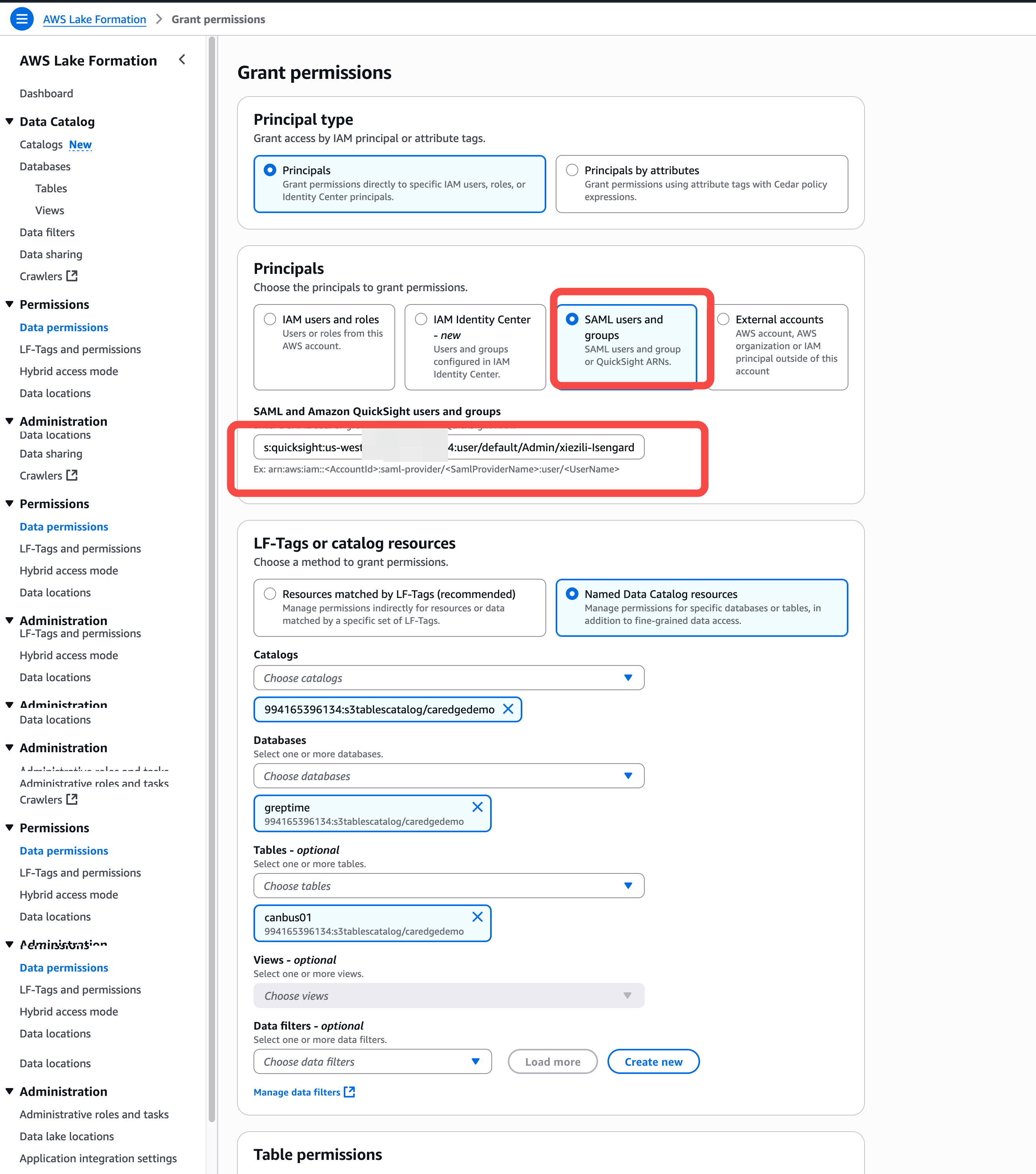
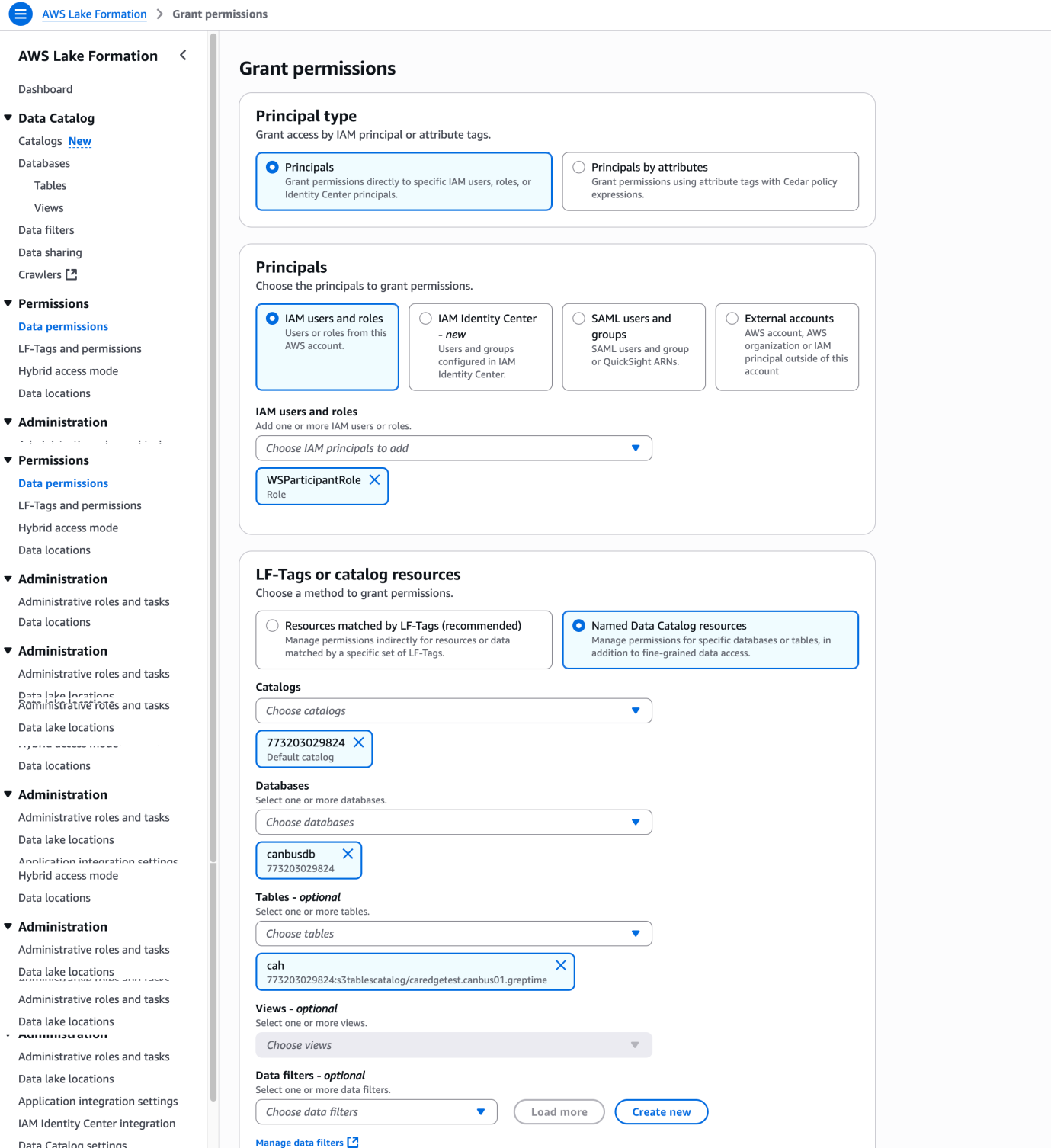
12. 访问 Lake Formation,对 QuickSight 的用户 ARN 进行表授权
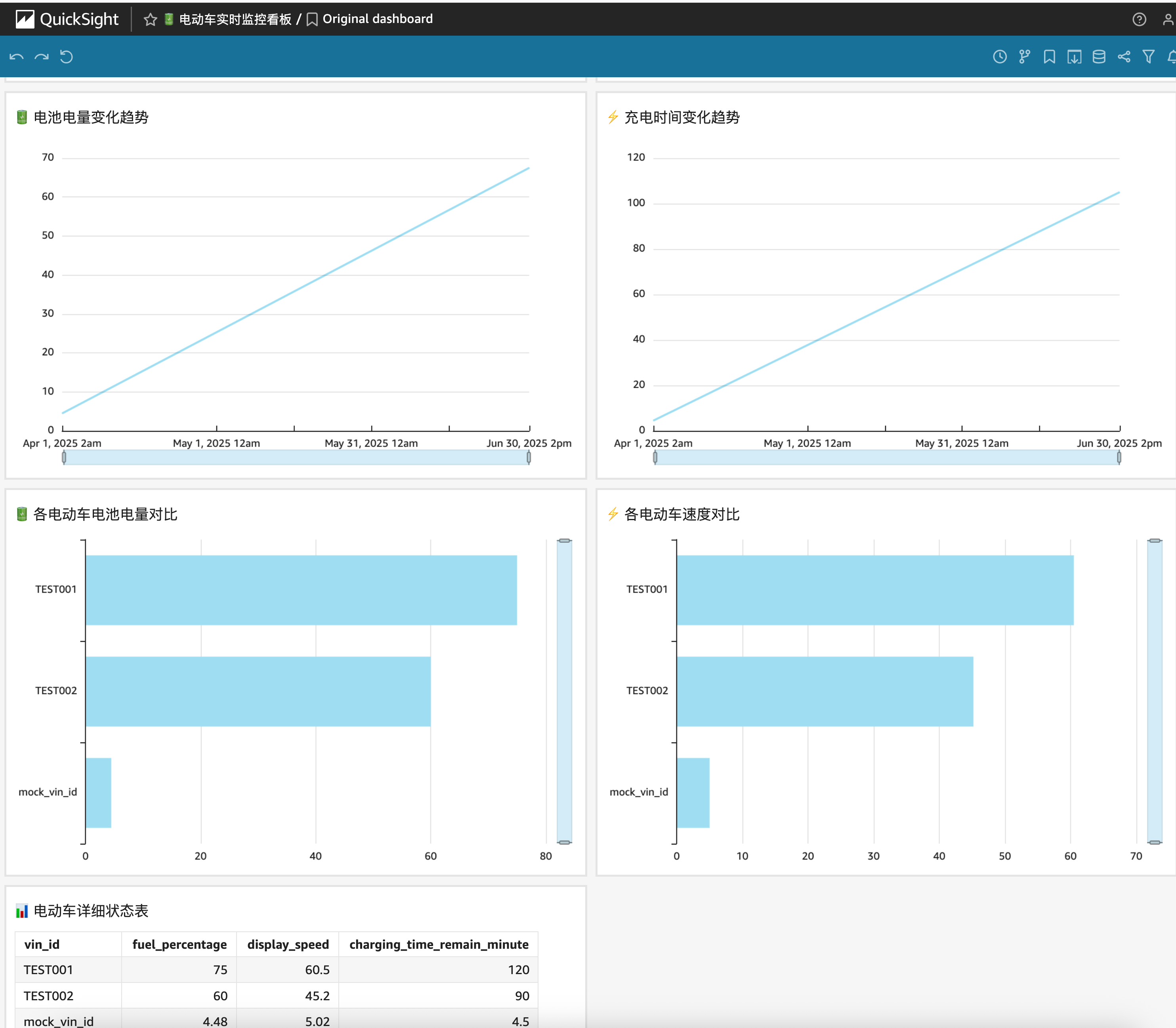
Amazon Q CLI 可以根据您描述的业务需求生成 Python 脚本,这些脚本能够自动化 QuickSight 看板的创建过程。通过运行这些脚本,您可以在 QuickSight 中快速构建初始看板结构。之后,您可以与 Amazon Q 进行交互,描述所需的具体调整,如添加新的可视化组件、修改数据筛选条件或更改图表类型等。Amazon Q 会相应地更新 Python 脚本,使您能够迭代优化看板设计。
这种方法不仅加速了看板开发过程,还提高了定制化的灵活性。作为 BI 工程师,您可以专注于高级分析策略和业务洞察,同时利用 AI 辅助工具处理技术细节,从而更高效地满足不同业务部门的数据可视化需求。
生成看板之后,也可以用 QuickSight 的 AI 功能通过自然语言构建看板:https://docs.aws.amazon.com/quicksight/latest/user/quicksight-q-get-started.html。
这样,整个湖仓一体架构基本完全打通,湖仓一体架构的核心优势是:支持多种查询引擎和分析工具无缝访问同一份数据,可以通过 Lake Formation 进行行列权限管控,最终实现真正的“一次写入,多处查询”范式。
总结
对于数据分析的平台,GreptimeDB 本身与 GreptimeDB Edge 共享相同的数据库内核,这使得 GreptimeDB 能够以零成本导入 GreptimeDB Edge 上传的数据文件,无需复杂的 ETL 过程。目前 GreptimeDB 运维简单支持容器化部署,也支持用 SQL 对数据进行查询,且提供了窗口聚合查询、数据对齐、插值查询等高级时序查询特性。关于 GreptimeDB 的任何细节可以参考官方文档 https://docs.greptime.cn。
在本篇博客中,我们的车联网数据平台采用了前沿的云原生架构,融合了 GreptimeDB 的高性能时序处理能力与 AWS 的无服务器计算优势。车端数据采集经过优化,通过 Lambda 实现实时处理,而 EMR Serverless 则负责复杂的分析任务。存储层基于 S3 和 Apache Iceberg 构建了现代化的 Lake House 架构,不仅提供了近乎无限的扩展性,还实现了 ACID 事务、灵活的 schema 演进和高效的查询性能。多引擎访问层支持 Athena、Redshift Spectrum 等多种分析工具,满足不同场景的需求。这一架构不仅确保了数据的一致性和可靠性,还大大提升了处理效率和成本效益。同时,Amazon Q 与 QuickSight 的结合使用可以显著提升数据分析和可视化的效率。Amazon Q 通过自然语言处理和 AI 辅助功能简化数据探索和查询过程,而 QuickSight 则将这些洞察转化为直观的可视化仪表板,两者协同工作,为用户提供从数据分析到可视化呈现的端到端解决方案。
本篇作者