背景
在云计算日新月异的时代,企业对 AWS 资源的使用正在呈现指数级增长。从最初的几十个资源扩展到数百甚至上万个,有效管理这些云资源已成为企业 IT 运营中的关键挑战。AWS 资源标签(Tags)作为一种元数据机制,已发展成为现代云资源管理策略的基石。
AWS 标签不仅是简单的键值对标识,它们在企业云环境中扮演着多重角色:
- 财务管控的支柱:使财务团队能够将云支出精准归类到特定业务单元、项目或环境,实现成本透明化
- 安全防线的基础:允许安全团队基于资源标签实施精细的访问控制策略,增强安全态势
- 运维效率的催化剂:帮助运维团队快速定位、筛选和组织管理相关资源,提升日常运维效率
- 自动化流程的驱动力:为自动化脚本和工作流提供目标资源的识别机制,加速 IT 流程自动化
然而,在实际实施过程中,标签管理往往面临诸多挑战:手动操作的低效性,在 AWS 控制台中逐一添加标签不仅耗时,还易出错;标签一致性的难题,不同团队可能采用不同的命名规范,导致标签混乱;历史资源的标签缺失,早期创建的资源往往没有按照当前策略打标签。
这些挑战在大规模云迁移项目中尤为突出。例如,在将数百个应用迁移到 AWS 的过程中,确保所有资源均带有“map-xxx”标签对于跟踪迁移进度、评估成功率以及后续资源管理至关重要。
本文将介绍一套自动化标签管理解决方案,帮助组织全面扫描 AWS 资源、识别未标记的资源并高效批量应用标签。该方案不仅适用于迁移场景,也可应用于任何需要优化标签策略的企业云环境。
解决方案概述
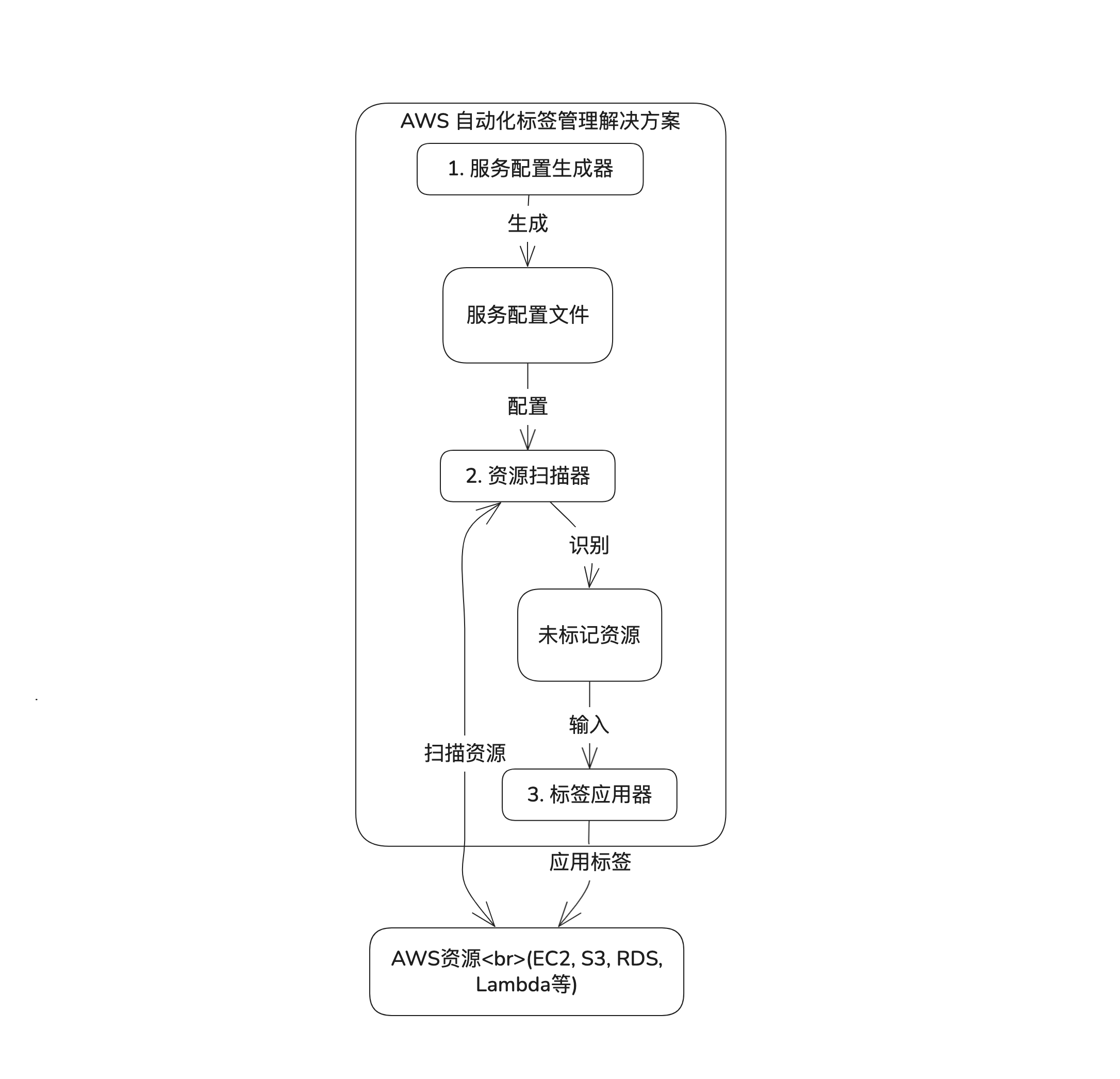
我们设计的自动化标签管理工具是一个全面而灵活的端到端解决方案,专为解决客户在 AWS 环境中面临的标签管理挑战而设计。该工具采用模块化架构,包含三个核心组件。可以手动执行 python 代码,也可以设置触发器在资源新建立的时候调用代码,通过触发器自动打标签,参考代码链接(仅供参考,不要直接使用生产环境):

1. 服务配置生成
此组件能自动探索 AWS 账户中支持的服务和资源类型,并生成结构化配置文件。它利用 AWS SDK 智能检测已启用的服务,定义各类资源类型、对应的 API 调用方法以及数据提取逻辑,为后续扫描过程奠定基础。
2. 资源扫描
该模块根据生成的配置文件,高效地遍历账户中的所有区域和服务,精确识别缺少特定标签的资源。采用多线程设计实现并行处理多个区域,大幅提升扫描效率,即使在大型环境中也能保持良好性能。
3. 标签应用
最后一个组件负责将指定标签批量应用于已识别的资源。它利用 AWS Resource Groups Tagging API 执行标签操作,同时生成详细的执行报告,包括成功、失败和跳过操作的统计信息,确保标签应用过程可追踪。
4. 自动化配置(可选)
可以设置触发器在资源新建立的时候调用代码,通过触发器自动打标签。当用户创建 AWS 资源时,API 调用会被 CloudTrail 记录并通过 EventBridge 触发 Lambda 函数执行打标签的逻辑,详细可参考此链接。
服务支持(可以根据自己的需求扩展配置模板):
- 计算服务:EC2、Lambda、ECS、EKS 等虚拟机和容器服务
- 存储服务:S3、EBS、EFS 等对象存储和文件系统
- 数据库服务:RDS、DynamoDB、Redshift、DocumentDB 等关系型和非关系型数据库
- 应用服务:SQS、SNS、SES 等应用集成组件
- 安全服务:IAM、KMS、Secrets Manager 等身份与加密管理
- 管理服务:CloudWatch、Systems Manager 等基础设施管理工具
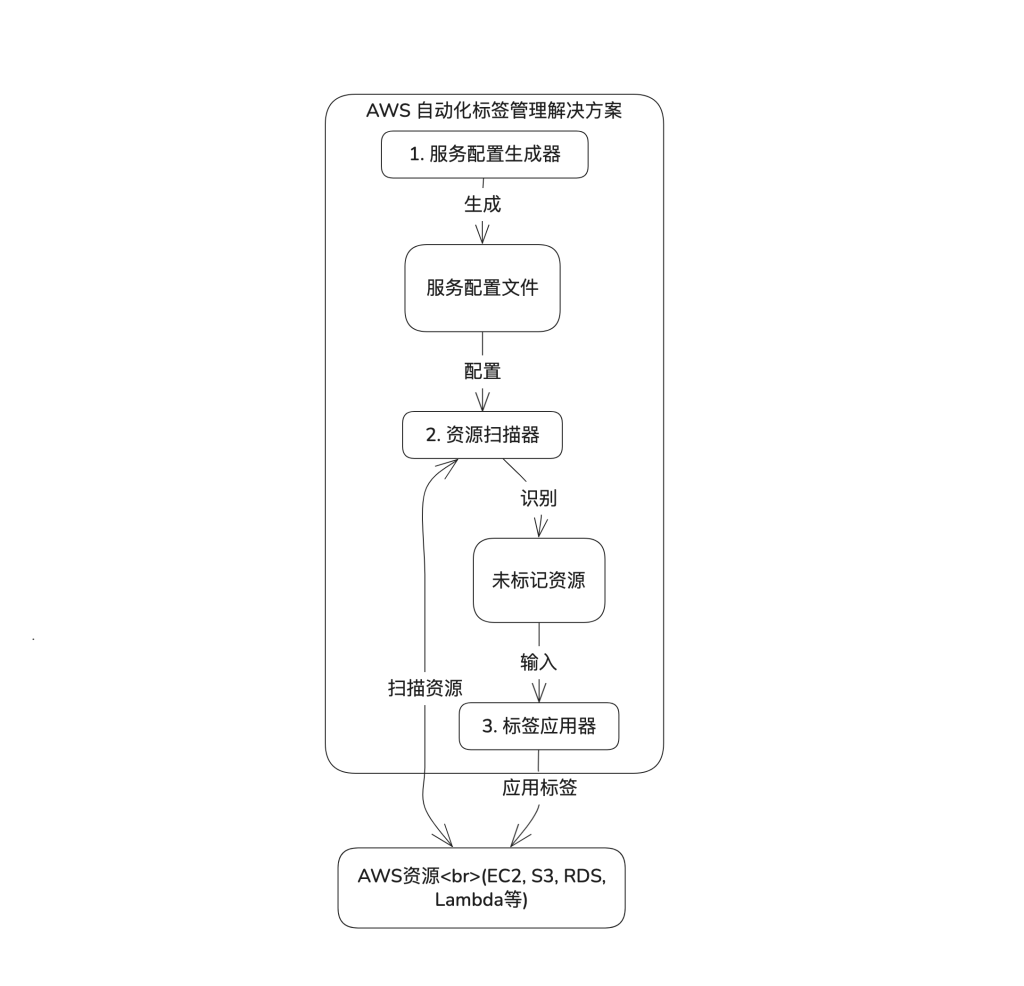
工作流程
该解决方案提供清晰而灵活的工作流程,如图所示,可分为以下三个主要步骤:
- 服务配置生成:自动扫描 AWS 账户,创建服务和资源类型映射,识别可标记的资源
- 资源扫描:利用映射信息,识别缺少指定标签的所有 AWS 资源
- 标签应用:为识别出的资源批量添加预定义标签
整个流程既支持完全自动化执行,也可分步骤手动实施,允许管理员在应用标签前审查扫描结果。这种设计适用于一次性标签修正活动,也适合定期的合规性检查。还可以通过将代码改造为 Lambda 函数并结合 EventBridge 调度或者做成定时任务,实现完全自动化的持续标签管理,细致流程如下所示:
技术实现
1. 服务配置生成
服务配置生成是解决方案的基础环节。为了有效扫描和标记资源,系统需要了解每种 AWS 服务的资源类型及其 API 交互方式。AWS 服务的异构性和复杂性(如不同的 API 结构、资源标识符格式、标签支持差异)是该环节面临的主要挑战。
我们开发的智能脚本 generate_service_config.py 能够:
- 自动识别账户中启用的 AWS 服务
- 为每种服务定义资源类型、API 调用方法、ARN 模板和资源 ID 提取逻辑
- 将配置保存为 JSON 格式,供后续模块使用
该脚本使用预定义的服务模板库,涵盖常见 AWS 服务的特性,同时具备自适应能力,能根据实际环境动态调整配置。
代码示例(核心配置生成逻辑):
#!/usr/bin/env python3
import boto3
import json
import logging
from concurrent.futures import ThreadPoolExecutor, as_completed
# 服务模板示例 - EC2服务配置
SERVICE_TEMPLATES = {
'ec2': {
'resource_types': [
{
'type': 'instance',
'list_method': 'describe_instances',
'arn_template': 'arn:aws:ec2:{region}:{account_id}:instance/{id}',
'extract_ids': 'lambda data: [i["InstanceId"] for r in data.get("Reservations", []) for i in r.get("Instances", [])]'
},
{
'type': 'volume',
'list_method': 'describe_volumes',
'arn_template': 'arn:aws:ec2:{region}:{account_id}:volume/{id}',
'extract_ids': 'lambda data: [v["VolumeId"] for v in data.get("Volumes", [])]'
}
# ... 更多资源类型
]
}
# ... 更多服务配置
}
def discover_active_services(region):
"""发现指定区域中活跃的AWS服务"""
active_services = {}
for service_name in POTENTIAL_SERVICES:
try:
client = boto3.client(service_name, region_name=region)
# 检查是否有实际资源
if service_name in SERVICE_TEMPLATES:
for resource_type in SERVICE_TEMPLATES[service_name]['resource_types']:
try:
list_method = resource_type['list_method']
response = getattr(client, list_method)()
# 提取资源ID
extract_ids = eval(resource_type['extract_ids'])
resource_ids = extract_ids(response)
if resource_ids:
active_services[service_name] = SERVICE_TEMPLATES[service_name]
logger.info(f"发现活跃服务: {service_name} ({len(resource_ids)} 个资源)")
break
except Exception as e:
logger.debug(f"检查服务 {service_name} 时出错: {str(e)}")
continue
except Exception as e:
logger.debug(f"服务 {service_name} 不可用: {str(e)}")
continue
return active_services
资源扫描是解决方案的核心功能,检查 AWS 环境并识别未标记的资源。
扫描器利用 AWS Resource Groups Tagging API 集中查询资源标签,再结合各服务的专用 API 进行资源枚举,确保全面发现所有未标记资源。
代码示例(核心扫描逻辑):
def get_untagged_resources(account_id, regions=None, services=None, tag_key='xxx-xxxx', max_workers=10):
"""获取未打指定标签的资源"""
if regions is None:
regions = get_available_regions()
untagged_resources = {}
# 使用线程池并行处理多个区域
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_region = {
executor.submit(process_region, account_id, region, services, tag_key): region
for region in regions
}
for future in as_completed(future_to_region):
region = future_to_region[future]
try:
region_resources = future.result()
if region_resources:
untagged_resources[region] = region_resources
except Exception as e:
logger.error(f"处理区域 {region} 时出错: {str(e)}")
return untagged_resources
def process_service(account_id, region, service_name, service_config, tagging, tag_key):
"""处理单个服务的资源扫描"""
service_resources = {}
try:
client = boto3.client(service_config['client'], region_name=region)
for resource_type_config in service_config['resource_types']:
# 获取资源列表
paginator = client.get_paginator(resource_type_config['list_method'])
all_resources = []
for page in paginator.paginate():
extract_ids = resource_type_config['extract_ids']
if resource_type_config['arn_template'] is None:
# 直接返回ARN的服务
resource_arns = extract_ids(page)
else:
# 需要构建ARN的服务
resource_ids = extract_ids(page)
resource_arns = [
resource_type_config['arn_template'].format(
id=resource_id, region=region, account_id=account_id
) for resource_id in resource_ids
]
all_resources.extend(resource_arns)
# 批量检查标签
untagged = []
for i in range(0, len(all_resources), 20):
batch = all_resources[i:i+20]
try:
response = tagging.get_resources(ResourceARNList=batch)
tagged_resources = {
res['ResourceARN']: [tag['Key'] for tag in res.get('Tags', [])]
for res in response.get('ResourceTagMappingList', [])
}
for arn in batch:
if tag_key not in tagged_resources.get(arn, []):
untagged.append(arn)
except ClientError as e:
logger.warning(f"检查标签时出错: {str(e)}")
continue
if untagged:
service_resources[resource_type_config['type']] = untagged
except Exception as e:
logger.error(f"处理服务 {service_name} 时出错: {str(e)}")
return service_resources
使用方法
该解决方案的使用流程直观且灵活,适合不同规模的 AWS 环境:
步骤 1:生成服务配置
python generate_service_config.py --regions us-east-1 us-west-2 --output aws_service_config.json --verbose
此命令将扫描指定区域的 AWS 服务,并生成详细的服务配置文件。参数说明:
--regions:要扫描的 AWS 区域列表--output:配置文件输出路径--verbose:启用详细日志输出
步骤 2:扫描未标记资源
python add_service_tag.py --tag-key xxx-xxxx --output untagged_resources.json --regions us-east-1 us-west-2
此命令将在指定区域中扫描缺少”xxx-xxxx”标签的资源,并将结果保存到 JSON 文件。参数说明:
--tag-key:要检查的标签键--output:扫描结果输出文件--regions:要扫描的 AWS 区域
步骤 3:应用标签
python add_service_tag.py --input untagged_resources.json --tag-value xxxx-xx-xxx --apply
此命令将为之前识别的资源应用指定值的标签。参数说明:
--input:包含未标记资源的输入文件--tag-value:要应用的标签值--apply:确认实际应用标签(不带此参数则只进行试运行)
完整的工作流程可以从头至尾一次执行,也可以分步骤进行,让管理员有机会在各阶段审查结果。
注意事项
权限要求
运行此工具的 IAM 用户或角色需具备以下权限:
tag:GetResources 和 tag:TagResources:用于标签管理ec2:DescribeRegions:用于获取区域列表- 各服务的资源列表权限(如
ec2:DescribeInstances)
建议创建专用的 IAM 角色,仅授予必要的最小权限集,可以在执行过程中根据需要自行调整。
性能优化
在大型 AWS 环境中优化工具性能的建议:
- 限制扫描范围:使用
--regions 和 --services 参数缩小扫描范围
- 调整并行度:根据系统能力修改
max_workers 参数
- 分批处理:按区域或服务分别执行扫描和标签应用
- 优化配置:从服务配置中移除不需要的服务或资源类型(修改预生成的标签文件)
未来展望
MCP 协议集成:MCP 化改造,面向 AI 驱动的智能化治理
Model Context Protocol(MCP)是 Anthropic 推出的开放协议标准,专为连接 AI 大语言模型与外部系统而设计。MCP 的核心价值在于为 AI 应用提供标准化的工具调用接口,使得智能体能够动态发现和调用各种外部服务能力。
在云资源管理领域,MCP 协议的引入意味着:
- 自然语言驱动:用户可以用自然语言描述需求,由 AI 助手理解并执行相应的标签管理操作
- 智能决策支持:AI 可以分析资源状态,提供个性化的标签策略建议
- 动态能力发现:AI 助手能够自动发现和学习新的标签管理功能
工具 MCP 化改造的价值
将现有标签管理工具升级为 MCP 服务后,可以实现以下突破性能力,以下只是建议,非本文核心内容:
1. 智能化操作体验
用户: "标记所有在us-east-1区域、超过30天未使用的EC2实例为'candidate-for-termination'"
AI: 正在扫描us-east-1区域的EC2实例...
发现12个超过30天未使用的实例
正在应用标签...
操作完成:成功标记12个实例
2. 上下文感知的智能建议
AI 助手可以基于历史数据和最佳实践,提供个性化建议:
- 分析未标记资源的成本影响
- 推荐基于业务场景的标签策略
- 识别标签不一致性并建议修复方案
MCP 服务实现
以下是将标签管理工具封装为 MCP 服务的核心实现,以下只是代码示例,可根据自己的需求进行编写:
from mcp import ClientSession, StdioServerTransport
import json
import asyncio
class AWSTaggingMCPServer:
"""AWS资源标签管理MCP服务"""
def
__init__
(self):
self.name = "aws-tagging-service"
self.version = "1.0.0"
async def get_tool_definitions(self):
"""返回MCP工具定义"""
return {
"aws-resource-discovery": {
"name": "aws-resource-discovery",
"description": "发现和分析AWS资源的标签状态",
"parameters": {
"type": "object",
"properties": {
"regions": {
"type": "array",
"items": {"type": "string"},
"description": "要扫描的AWS区域列表",
"default": ["us-east-1"]
},
"services": {
"type": "array",
"items": {"type": "string"},
"description": "要扫描的AWS服务列表",
"default": ["ec2", "s3", "rds"]
},
"tag_key": {
"type": "string",
"description": "要检查的标签键",
"default": "Environment"
},
"analysis_type": {
"type": "string",
"enum": ["untagged", "inconsistent", "cost-analysis"],
"description": "分析类型",
"default": "untagged"
}
}
}
},
"aws-tag-application": {
"name": "aws-tag-application",
"description": "为AWS资源批量应用标签",
"parameters": {
"type": "object",
"properties": {
"resource_arns": {
"type": "array",
"items": {"type": "string"},
"description": "要标记的资源ARN列表"
},
"tags": {
"type": "object",
"description": "要应用的标签键值对",
"additionalProperties": {"type": "string"}
},
"dry_run": {
"type": "boolean",
"description": "是否为预演模式",
"default": true
}
},
"required": ["resource_arns", "tags"]
}
},
"aws-tag-compliance-check": {
"name": "aws-tag-compliance-check",
"description": "检查资源标签合规性并生成报告",
"parameters": {
"type": "object",
"properties": {
"compliance_policy": {
"type": "object",
"description": "标签合规策略定义",
"properties": {
"required_tags": {
"type": "array",
"items": {"type": "string"}
},
"tag_patterns": {
"type": "object",
"additionalProperties": {"type": "string"}
}
}
},
"output_format": {
"type": "string",
"enum": ["json", "csv", "html"],
"default": "json"
}
}
}
}
}
async def execute_tool(self, tool_name: str, parameters: dict):
"""执行MCP工具调用"""
try:
if tool_name == "aws-resource-discovery":
return await self._discover_resources(parameters)
elif tool_name == "aws-tag-application":
return await self._apply_tags(parameters)
elif tool_name == "aws-tag-compliance-check":
return await self._check_compliance(parameters)
else:
return {"error": f"未知工具: {tool_name}"}
except Exception as e:
return {"error": f"执行工具时出错: {str(e)}"}
async def _discover_resources(self, params):
"""发现和分析资源"""
from add_service_tag import get_untagged_resources, get_account_id
# 调用现有的扫描逻辑
account_id = get_account_id()
untagged = get_untagged_resources(
account_id=account_id,
regions=params.get('regions'),
services=params.get('services'),
tag_key=params.get('tag_key', 'Environment')
)
# 生成智能分析报告
total_resources = sum(
len(arns)
for region_data in untagged.values()
for service_data in region_data.values()
for arns in service_data.values()
)
analysis = {
"summary": {
"total_untagged": total_resources,
"regions_affected": len(untagged),
"services_affected": len({
service for region_data in untagged.values()
for service in region_data.keys()
})
},
"details": untagged,
"recommendations": self._generate_recommendations(untagged)
}
return analysis
async def _apply_tags(self, params):
"""应用标签到资源"""
from add_service_tag import tag_resources
# 构造资源数据结构
resources_by_region = {}
for arn in params['resource_arns']:
region = self._extract_region_from_arn(arn)
if region not in resources_by_region:
resources_by_region[region] = {'batch': {'resources': []}}
resources_by_region[region]['batch']['resources'].append(arn)
# 应用标签
results = {}
for region, region_data in resources_by_region.items():
region_results = tag_resources(
resources={region: region_data},
tag_key=list(params['tags'].keys())[0],
tag_value=list(params['tags'].values())[0],
dry_run=params.get('dry_run', True)
)
results[region] = region_results
return {
"operation": "tag_application",
"dry_run": params.get('dry_run', True),
"results": results,
"summary": {
"total_processed": len(params['resource_arns']),
"success_rate": self._calculate_success_rate(results)
}
}
def _generate_recommendations(self, untagged_resources):
"""生成智能建议"""
recommendations = []
# 分析EC2实例
ec2_count = sum(
len(region_data.get('ec2', {}).get('instance', []))
for region_data in untagged_resources.values()
)
if ec2_count > 0:
recommendations.append({
"type": "cost_optimization",
"priority": "high",
"message": f"发现{ec2_count}个未标记EC2实例,建议立即添加Environment和Owner标签以进行成本归属"
})
# 分析S3存储桶
s3_count = sum(
len(region_data.get('s3', {}).get('bucket', []))
for region_data in untagged_resources.values()
)
if s3_count > 0:
recommendations.append({
"type": "security",
"priority": "medium",
"message": f"发现{s3_count}个未标记S3存储桶,建议添加Classification和DataOwner标签以加强数据治理"
})
return recommendations
MCP服务启动
async def main():
server = AWSTaggingMCPServer()
# 配置MCP传输层
transport = StdioServerTransport()
async with ClientSession(transport) as session:
# 注册工具
tools = await server.get_tool_definitions()
await session.initialize(server.name, server.version, tools)
# 处理工具调用
async for request in session.request_stream():
if request.method == "tools/call":
result = await server.execute_tool(
request.params["name"],
request.params.get("arguments", {})
)
await session.send_result(request.id, result)
if
name
== "
__main__
":
asyncio.run(main())
MCP 集成的实际应用场景
场景 1:智能成本分析(仅举例)
可以配合 AWS Q CLI,调用成本分析 MCP 服务(Cost Explorer MCP Server)完成成本分析工作,步骤如下:
- 安装 AWS Q CLI,安装步骤见链接
- 安装 MCP 服务,部署官方提供的成本分析 MCP 服务,部署说明见链接
- 启动 MCP 服务后,通过 q chat 调用成本分析服务,如下所示:
🛠️ Using tool: get_today_date from mcp server awslabscost_explorer_mcp_server
⋮
● Running get_today_date with the param:
⋮ {
⋮ "arguments": {},
⋮ "name": "get_today_date"
⋮ }
Allow this action? Use 't' to trust (always allow) this tool for the session. [y/n/t]:
分析后的结论如下(部分):
## 成本可见性对比
### 当前状态 (部分标记)
总成本: $34.34/月
可分配成本:
├── Training部门 (CostCenter): $11.39 (33.1%)
│ └── ResilienceWorkshop项目: $11.39
└── 未分配成本: $22.95 (66.9%) ❌
└── EKS工作负载: $22.95 (无法追踪到具体项目)
### 完整标记后的预期状态
总成本: $34.34/月
可分配成本:
├── Training部门 (CostCenter): $34.34 (100%)
│ ├── ResilienceWorkshop项目: $11.39 (33.1%)
│ └── EKS-Workshop项目: $22.95 (66.9%) ✅
└── 未分配成本: $0.00 (0%) ✅
## 立即行动的ROI
### 标记成本 vs 收益
• **一次性标记工作**: ~20分钟
• **月度成本节省潜力**: $6.87-$11.45 (20-33%)
• **年度ROI**: 4,100-6,870%
### 具体节省机会
1. EKS节点优化: $6.87/月 (通过正确调度)
2. 自动关停: $4.58/月 (非工作时间)
3. 实例类型优化: $3.44/月 (基于使用模式)
结论: 投入~20分钟完成标记工作,每月可节省$10-17,年度ROI超过6,000%,6,000%,
同时获得完整成本可见性和控制力。
场景 2:合规性自动检查(仅举例)
可以使用本博客提供的代改造成 MCP 服务,配合 AWS Q CLI 做资源检查:
用户: "检查所有资源是否符合公司标签策略"
AI: 执行合规性检查...
策略要求: Environment、Owner、Project标签必须存在
检查结果:
✅ 合规资源: 1,234个 (78%)
❌ 不合规资源: 345个 (22%)
建议修复措施已生成,是否立即执行标签修复?
总结
AWS 资源标签对于有效管理云基础设施至关重要,但随着环境规模增长,手动管理标签变得日益困难。我们开发的自动化标签管理解决方案为企业提供了强大而灵活的工具,该解决方案适用于多种场景,包括云迁移项目、成本分配优化等,还可以配合数据库或者文件存储做标签分类,可为企业带来显著的运维效率提升和治理能力增强。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者